Hi @Spacesurfer , there are a few ways to do this - that’s how it usually is with Knime.
I think the main challenge here is to determine/build the list of values/groups. Once this is done, the rest is pretty much easy.
Also, an additional challenge is that your data is not as clean. For example:
Row0 | 2. Fahrerjacke (Herren/Damen)
Row23 | 1x zusätzliche Fahrerjacke (Herren/D
Row37 | 2. Fahrerjacke zusätzlich (Damen/Her
It looks like some data got cut off. Or it also looks like there might be some cases of Herren/Damen vs Damen/Herren. It’s up to you how you want to handle these types of “dirty” data - either fix them manually or add them to the ignore list (see further down for ignore list).
And an another additional challenge for me in particular is that I’m not in that field (clothing/jacket) and also I don’t read German, so I can’t really determine what’s common name vs the values that we want.
Nevertheless, I’ve put something together that can give you an idea of which direction to go, and you can tweak it based on your knowledge of German and clothing/jacket.
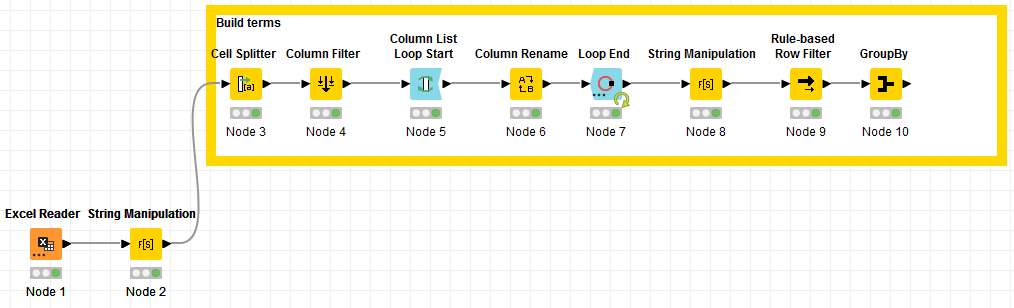
Let’s start building the values (I call them “terms”):
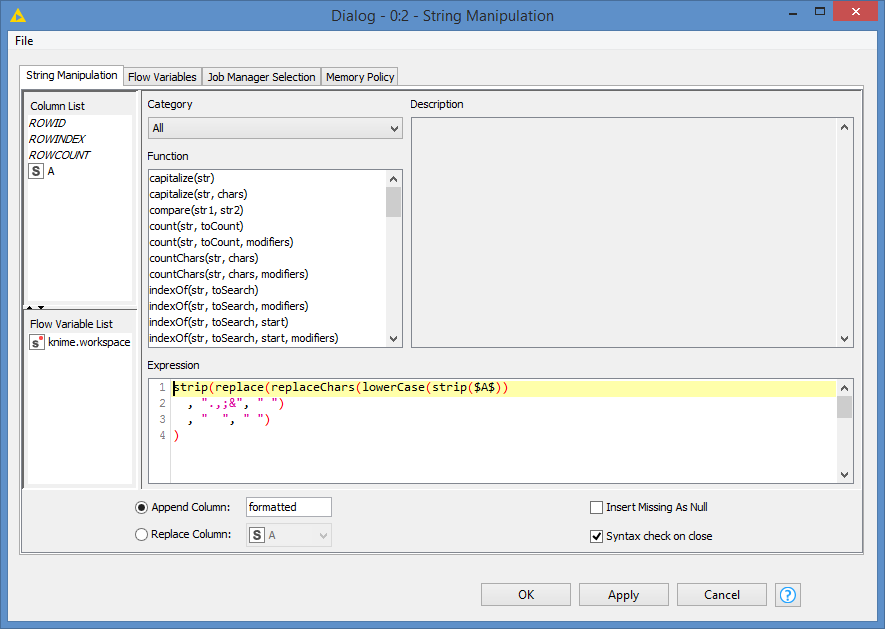
First step is to try to clean the data as much as possible:
strip(replace(replaceChars(lowerCase(strip($A$))
, ".,;&", " ")
, " ", " ")
)
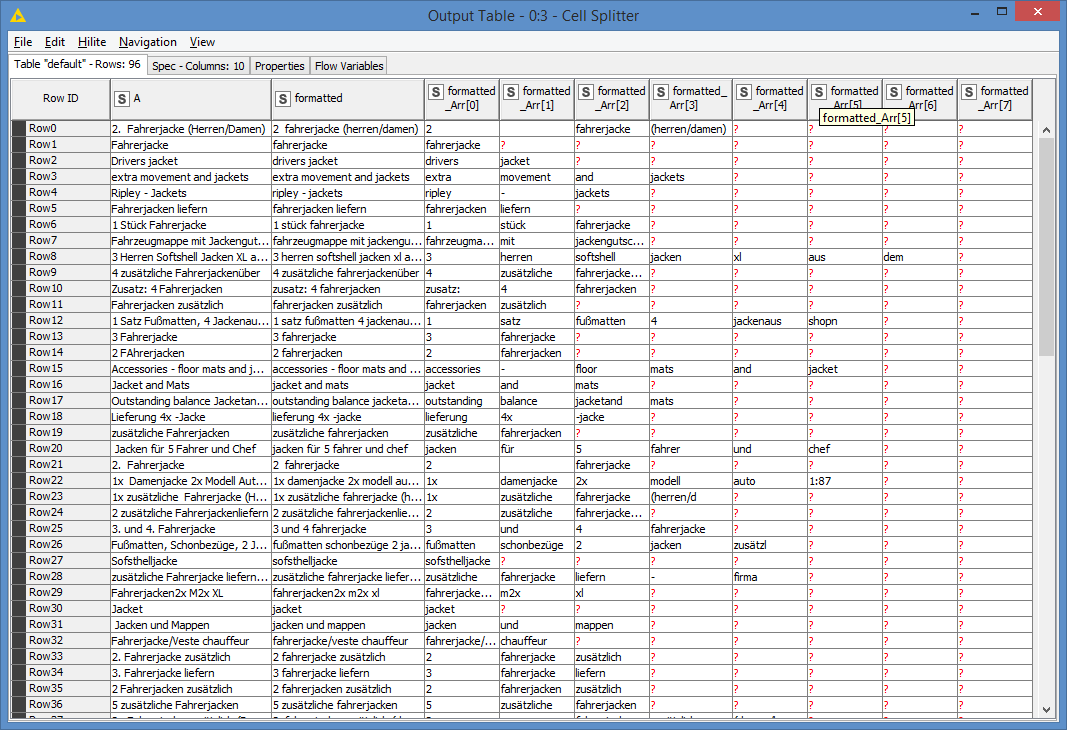
Results:
I extract each word (a word being something separated by a space):
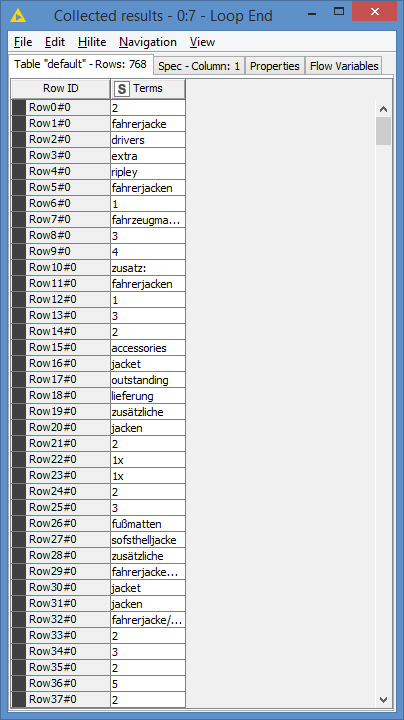
And I merge all of the extracted words into 1 column:
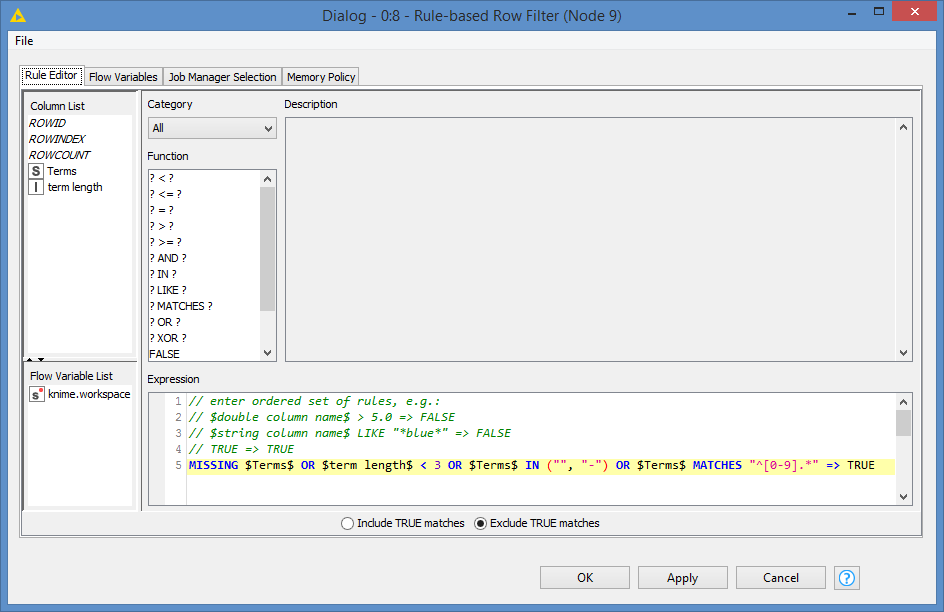
I then apply some base rules to filter out some values:
MISSING $Terms$ OR $term length$ < 3 OR $Terms$ IN ("", "-") OR $Terms$ MATCHES "^[0-9].*" => TRUE
So, I’m filtering out any missing values, values whose length is less than 3, removing empty values, removing values that are equal to “-”, and finally removing values that start with a number - Note: You can tweak this part. I basically checked what the results of the previous node was, and tried to filter out what I think do not make a proper term.
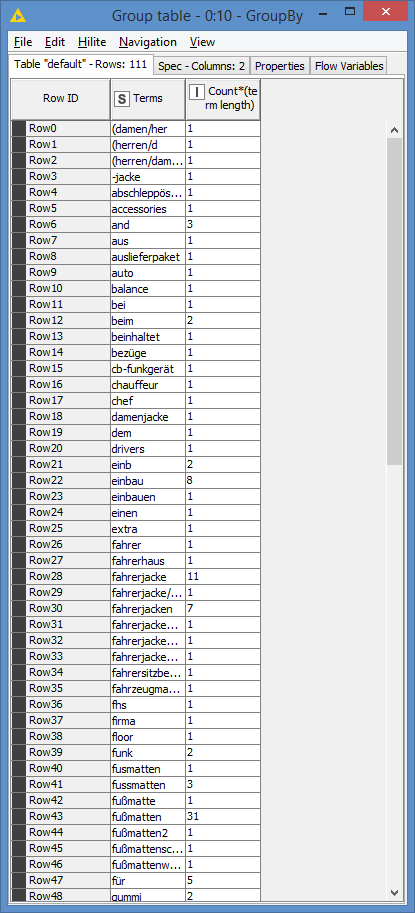
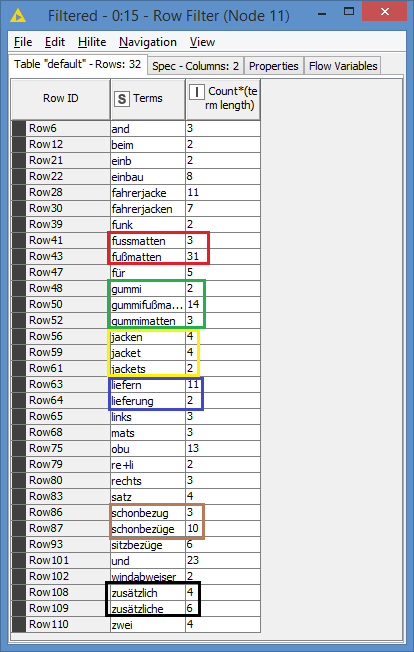
After that, I count the number of occurences of each term - this will also show me what the unique terms are:
I choose to assume that anything that occurred only once does not qualify as a group - you might try to ignore and not apply this rule first and see what results that you have in case that this is not a correct assumption; this will also depend on what are the keywords you want:
Results:
I highlighted some terms together as they might actually mean the same thing - again, it’ll be up to you how you want to handle these (you could create a mapping table to have them renamed to the same name)
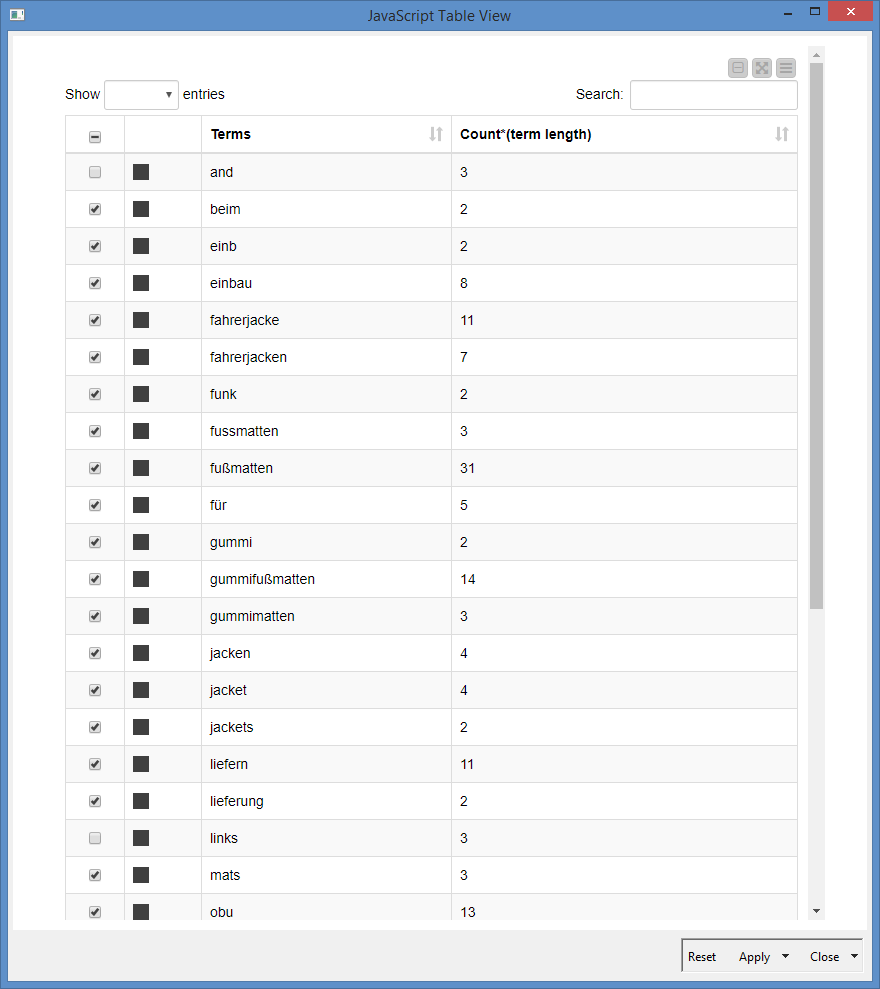
At this point, I can create my ignore list for additional filtering. There are 2 ways I would consider here. Either you can create a table manually via a Table Creator, especially if you are going to re-use the workflow and you can add new words to the table - you can tweak this, and you probably will as you most likely might not get it perfect the first time:
Or you can do this interactively via a Table View where you can select what to keep or remove:
Pros and cons:
Table list is tedious to manually add the terms, but you will only to do this once as it is permanent, meaning if you re-run the workflow, you don’t need to re-add the terms, while the interactive option, easier to click to select than manually entering the terms, but will reset if you re-run the workflow, meaning you will have to re-select the terms.
I’ll include both options. Then it’s just a matter of matching the terms.
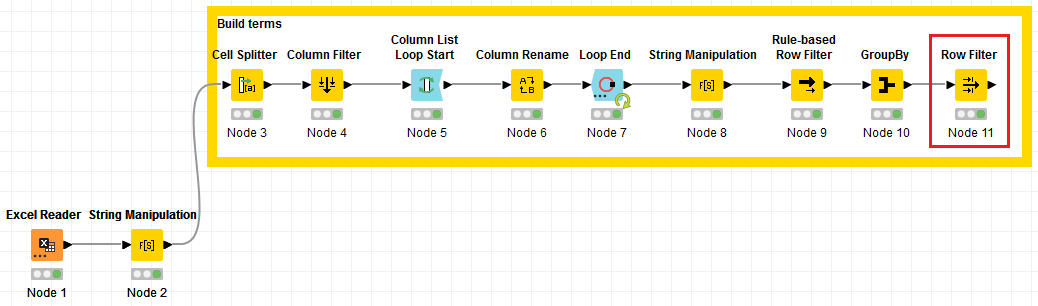
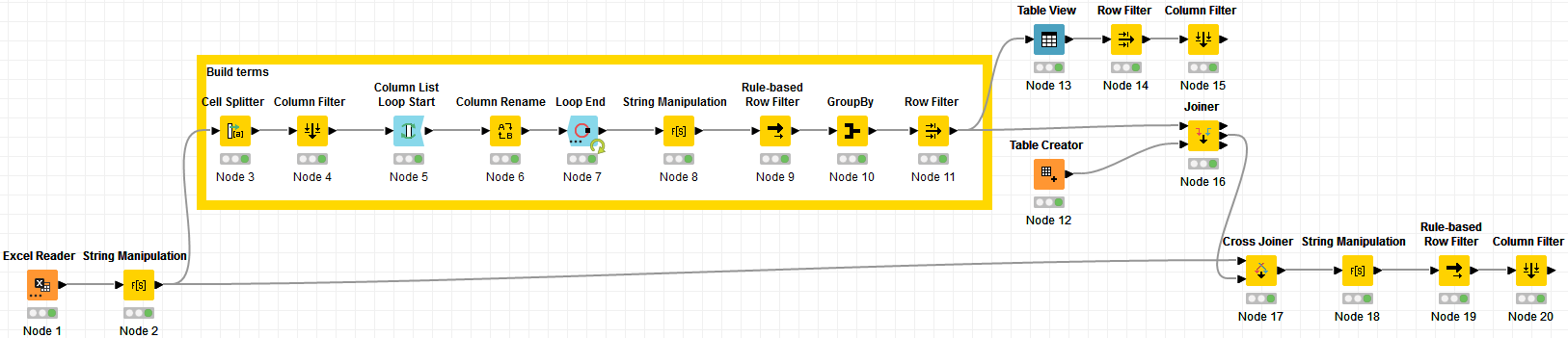
The final workflow looks like this:
So, the Column Filter (Node 15) has the same results as the 2nd output port of the Joiner (Node 16). They are the 2 options of either creating a list via a Table Creator or selecting via the Table View (obviously they will be the same of the same terms are selected).
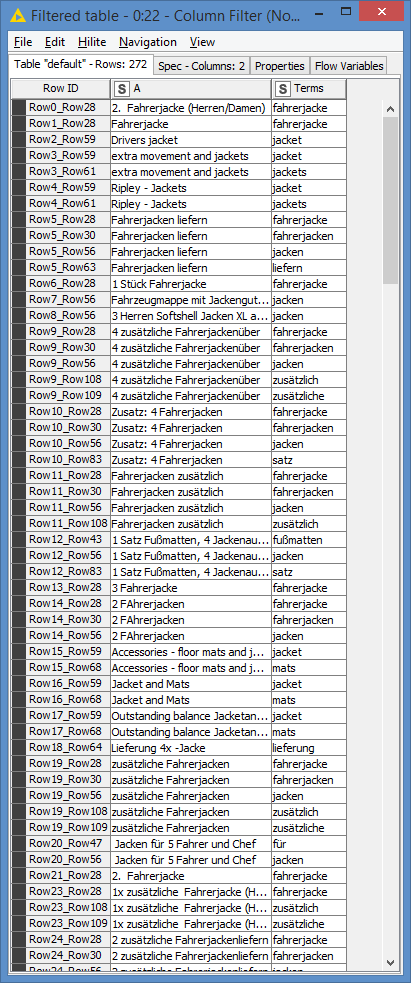
Here are the results after matching:
You will get duplicates in my case, as some of the items match more than 1 group. For example, “jackets” will match both “jacket” and “jackets”. Or “mats and jacket” will match both “mats” and “jacket”. You can tweak it based on your needs. For example, you may just combine both “jacket” and “jackets” under the same term, in which case you can add “jackets” as an ignore word, or you can simply apply a duplicate row filter and choose only 1 match per item. I’ll leave that part to you.
Here’s the workflow (Excel file included): Identify groups based on similar words.knwf (159.2 KB)