Hi everyone,
I am kind of new in KNIME. I am trying to make a data manipulation for my thesis.
I have the input table below. I just need to keep the first row for a unique article. For example for article 1922, I only need the first row with author_ID=1105826 and score=0.50
I tried it with GroupBy but it didn’t help. I kindly need your suggestions.
INPUT
article_ID author_ID score
1350 891898 0.06
1922 1105826 0.50
1922 1036060 0.10
2661 243949 0.02
2985 857965 0.02
5182 306771 0.50
5182 255639 0.50
5182 335639 0.06
OUTPUT
article_ID author_ID score
1350 891898 0.06
1922 1105826 0.50
2661 243949 0.02
2985 857965 0.02
5182 306771 0.50
Thanks,
Busra
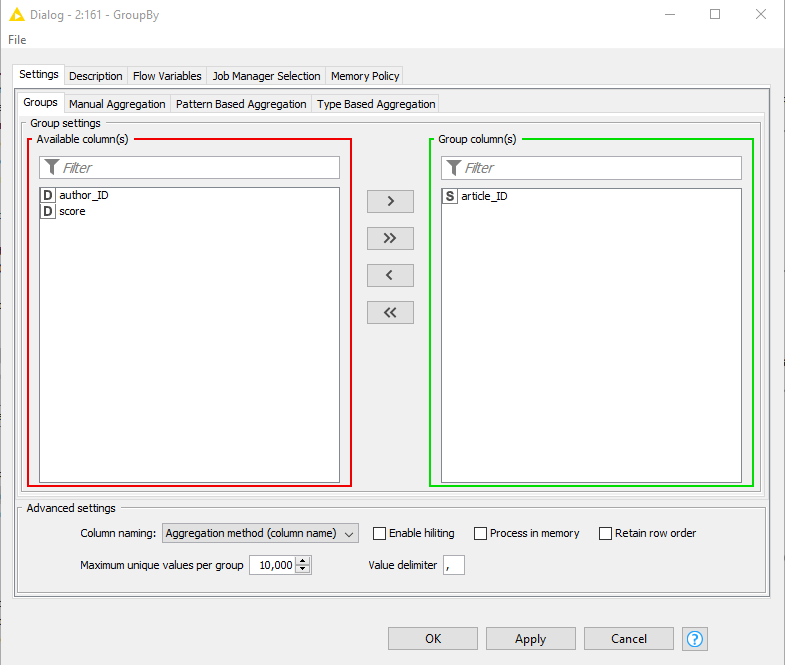
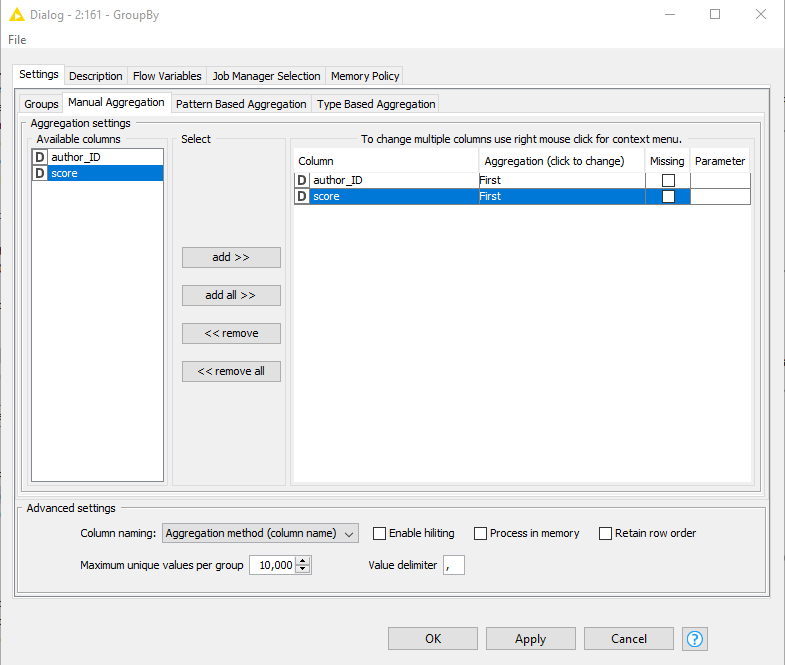
 I just wanted to highlight also that if you are using KNIME 4.0, you can also play around with the Duplicate Row Filter. It does exactly that: find duplicates and keep the rows you would like to based on a certain rule - for instance, keeping the first row.
I just wanted to highlight also that if you are using KNIME 4.0, you can also play around with the Duplicate Row Filter. It does exactly that: find duplicates and keep the rows you would like to based on a certain rule - for instance, keeping the first row.