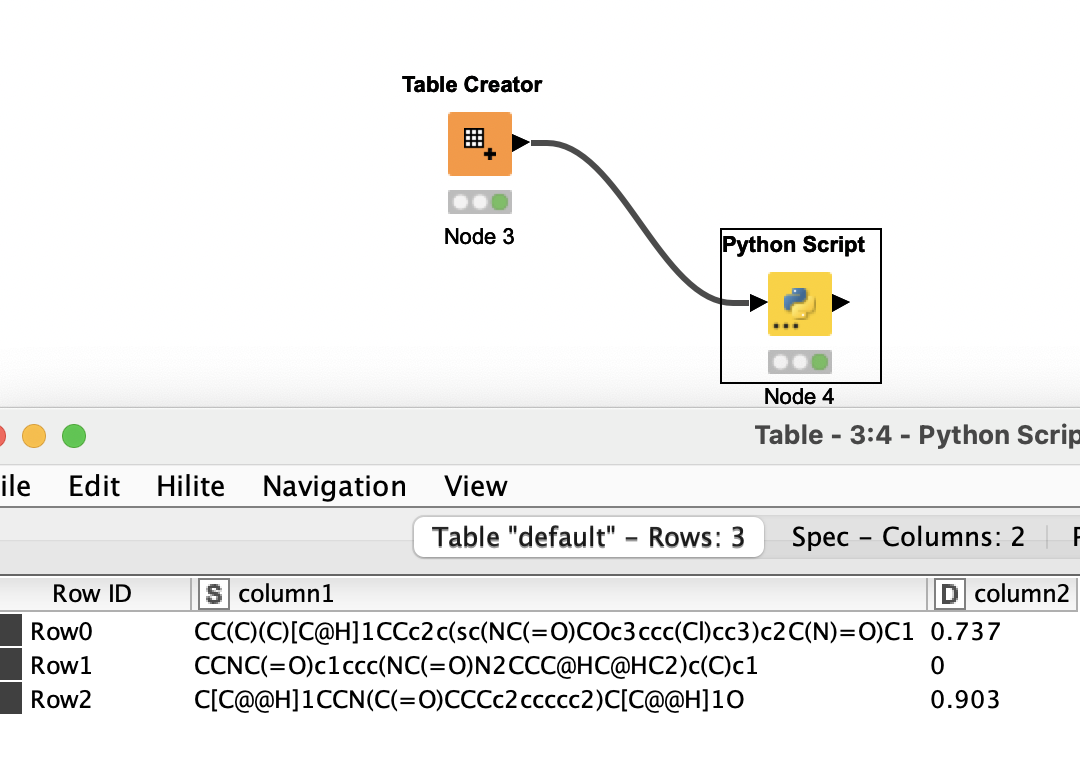
Hi, I am investigating if it is possible to run Python code from the Therapeutic Data Commons (TDC) by using the KNIME Python Integration. For example this code allows one to calculated the drug likeness , expressed as QED for molecules in smiles format:
Is it possible to do this in KNIME? Ideally by feeding the Python Script node with a KNIME table containing smiles strings, with the output being the QED values, one for each row.
Any pointers on if/how to get this to work appreciated.
Make the Python module of TDC available in a local Python environment to be used in your KNIME installation
Write and test the code within a Python Script node
Make the local Python environment exportable via Conda Environment Propagation node to share the whole workflow with others
The first point can be tackled by creating a Python environment. One approach is via command line / terminal /anaconda3 prompt. Create a environment for the Python Script node as described in this section about metapackages. You might have to look at the prerequisites section at the beginning of the chapter. As pytdc is available via Pip (up until version 0.4.1) or via Conda (up until version 0.3.8), I describe the approach via Conda:
If 0.3.8 is not sufficient, you can install a more recent version via pip (easy, google it )
Make sure that in Preferences -> KNIME -> Python you choose Conda instead of Bundled or Manual and select the above created environment (which I named here my_environment).
Now you should have a working Python environment.
Thanks for your swift reply. I got quite far but in the end it comes down to writing the correct Python code under 2).
First off I used your code to create the Conda environment for PyTDC, and then tried to run the Oracle QED code directly on the command line. This did not work initially but I got it to work by doing
pip install PyTDC
after which it still did not work. I then did
pip install PyTDC --upgrade
and then the code worked, so I had a working environment for KNIME. I specified this environment under the Python preferences in KNIME.
Now it comes basically down to writing the correct Python code in the Python Scripting node. I feed this node with a table containing the 3 smiles form the Oracle QED example, and enter the following code…
#This example script simply outputs the node’s input table.
PPS: I do not think that the pip part is necessary for the usage within the Python Script node if the conda command for the environment creation is executed as I suggested.
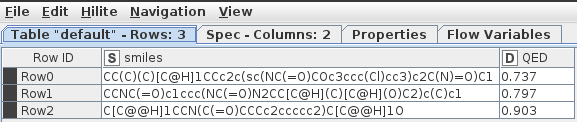
Bit interesting that you get a value of 0 (zero) for the second row with the same smiles?
Anyway, this is great as it gives access to a lot of interesting cheminformatics tools from the Therapeutic Data Commons via KNIME, which should be of interest to quite a few people in the life science field.
If I then activate my_environment in KNIME and rerun the Python scritp I get this error in KNIME:
ERROR Python Script 3:2 Execute failed: ImportError: cannot import name ‘rmsd’ from ‘tdc.chem_utils.oracle.oracle’ (/home/evehom/miniconda3/envs/my_environment/lib/python3.11/site-packages/tdc/chem_utils/oracle/oracle.py)
So clearly pytdc does not get installed on my system this way.
On the command line in the same environment it looks like this, if this is of any use:
python3
Python 3.11.4 | packaged by conda-forge | (main, Jun 10 2023, 18:08:17) [GCC 12.2.0] on linux
Type “help”, “copyright”, “credits” or “license” for more information.
from tdc import Oracle
oracle = Oracle(name = ‘QED’)
Traceback (most recent call last):
File “”, line 1, in
File “/home/evehom/miniconda3/envs/my_environment/lib/python3.11/site-packages/tdc/oracles.py”, line 58, in init
self.assign_evaluator()
^^^^^^^^^^^^^^^^^^^^^^^
File “/home/evehom/miniconda3/envs/my_environment/lib/python3.11/site-packages/tdc/oracles.py”, line 74, in assign_evaluator
from .chem_utils import qed
File “/home/evehom/miniconda3/envs/my_environment/lib/python3.11/site-packages/tdc/chem_utils/init.py”, line 3, in
from .oracle.oracle import PyScreener_meta, Vina_3d, Score_3d, Vina_smiles, molecule_one_retro, ibm_rxn,
ImportError: cannot import name ‘rmsd’ from ‘tdc.chem_utils.oracle.oracle’ (/home/evehom/miniconda3/envs/my_environment/lib/python3.11/site-packages/tdc/chem_utils/oracle/oracle.py)
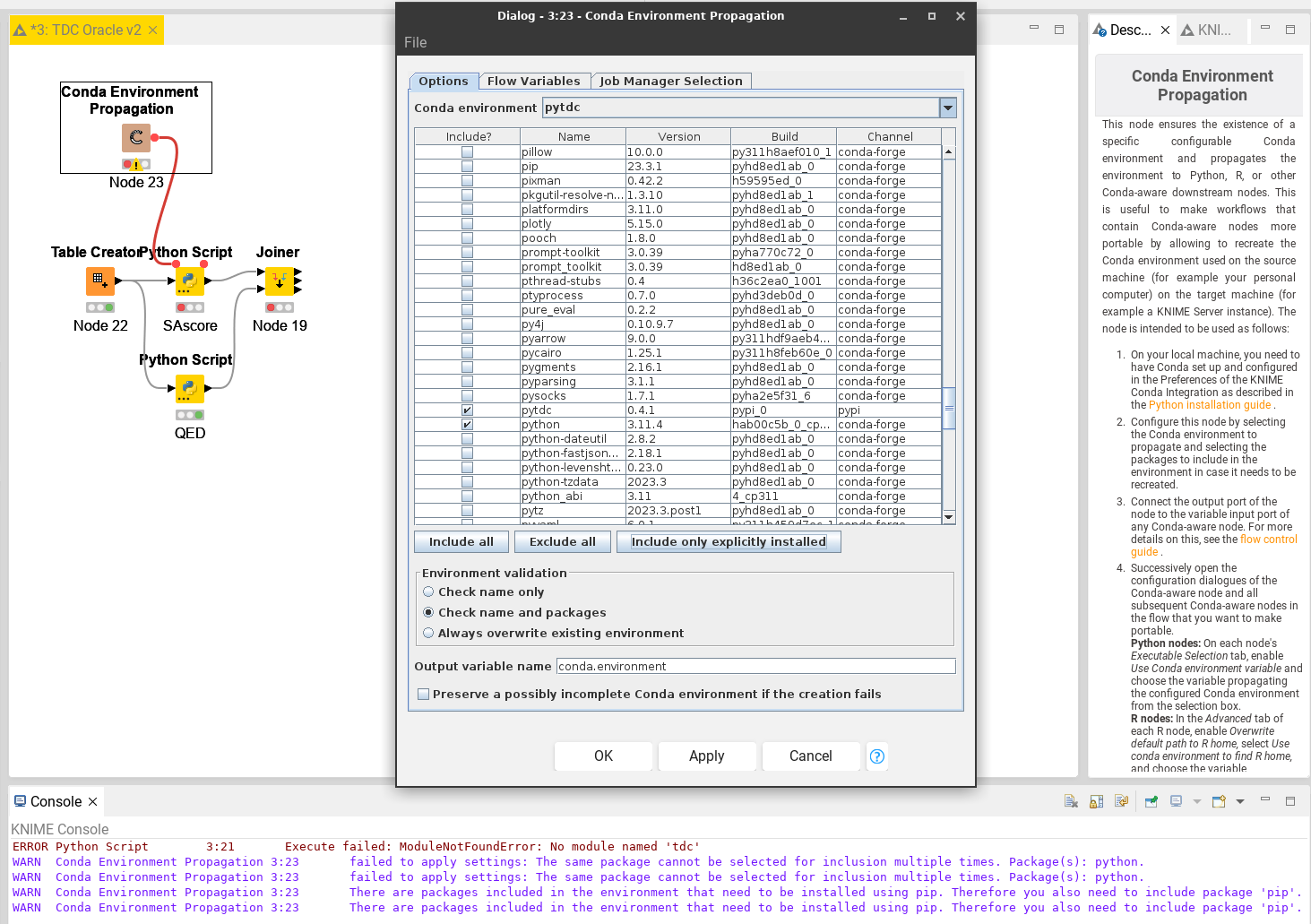
One more thing: if I use the Conda Environment Propagation node to set the working PyTDC environment to be used for Python Scripting, I get the same error message as when running the QED script command line:
ERROR Python Script 3:2 ImportError: cannot import name ‘rmsd’ from ‘tdc.chem_utils.oracle.oracle’ (/home/evehom/miniconda3/envs/my_environment/lib/python3.11/site-packages/tdc/chem_utils/oracle/oracle.py)
Maybe you can shine a light on why it works when setting the environment through the preferences, but not when using the Conda Environment Propagation node.
The different values are interesting, maybe TED has different implementations on MacOS Intel (which I have) vs your OS?
About the whole pip thing. I understand (and thanks for all the details, that was helpful).
One correction: clearly pytdc does get installed on your system with conda-forge. However, as stated in my first answer, it installs only version 0.3.8, whereas pip installs the newer version 0.4.1. The error you (and I) get when using the conda-forge version is fixed in the newer 0.4.1. I opened a ticket for you at their issue portal and gave them a very clear picture: Conda-forge contains old version · Issue #213 · mims-harvard/TDC · GitHub
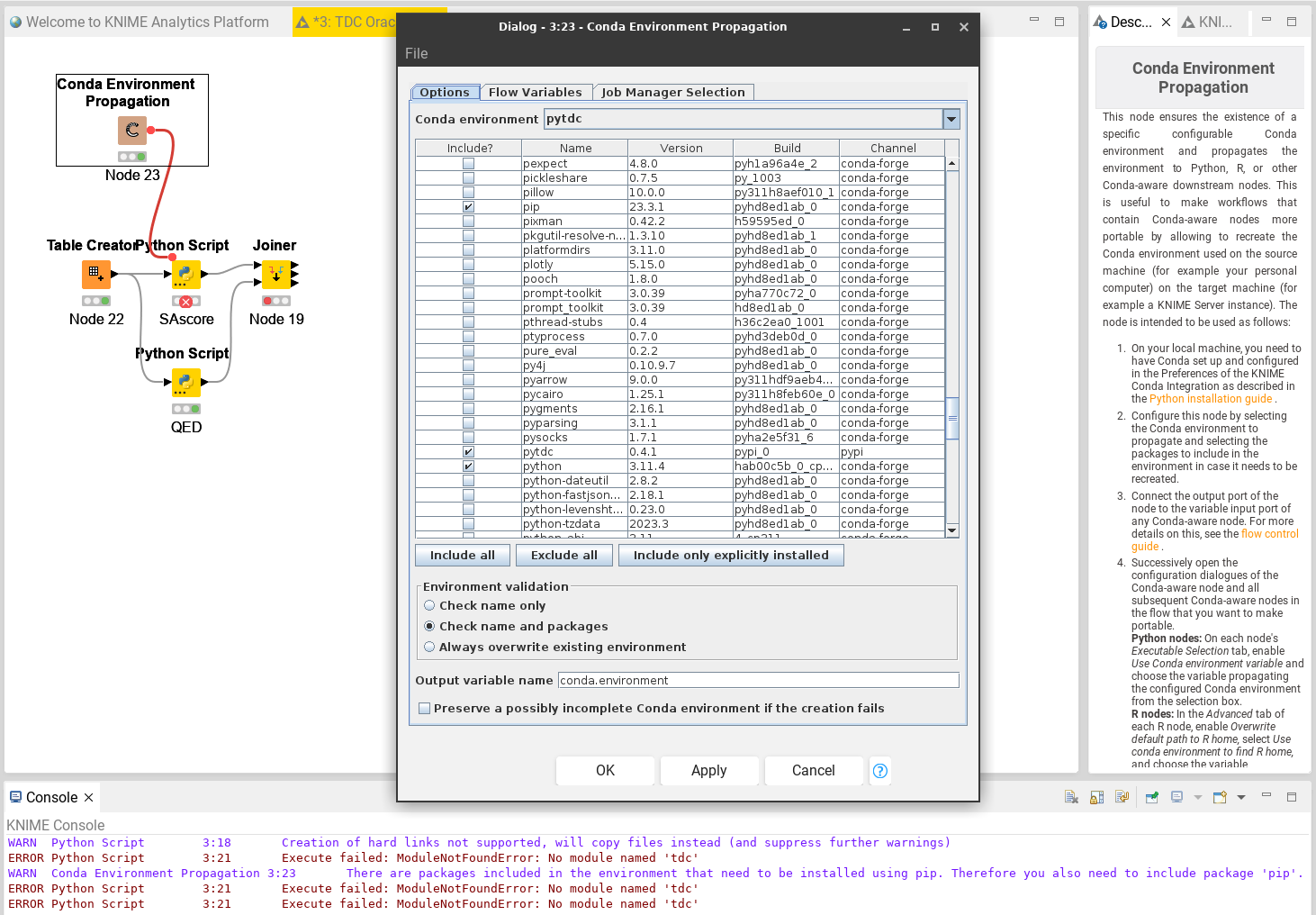
The Conda Env Prop node of yours seem to also use a wrong version (i.e. 0.3.8). Can you configure it with a working Python environment and verify that it contains the correct (i.e. 0.4.1) version of PyTDC, which can be seen in the configuration dialog? If you have trouble, please provide a workflow with the Conda Env Prop node in this thread.
To be honest I don’t really understand how all this works with Python. I have a working environment (pytdc) that works command line, and also with KNIME if I choose it under the preferences. But it does not work when I under preferences use the bundle Python and then propagate my working pytdc environment with the Conda Env node. The contents of this node look different before and after running the workflow. What do all the yellow lines mean?
BTW, I am calculating SAscore and QED in parallel but could this be combined in just one node? Again both work fine if I set the Python env through the preferences.
BTW pytdc 0.4.1 is available through Conda Envirnment Propagation, yet I get the error that it is missing when running the workflow. Does it matter if it comes from pypi or conda-forge?
that seems to be a misconfiguration of the Conda Env Prop node. Please use the radio button “Check name and packages” near the bottom of the config dialog. If that does not help enforcing the correct (0.4.1) version, then the “Always overwrite existing…” option should help. I also suggest using the “Include only explicitly installed” button to make the workflow available for other OS (because if everything is included, then also packages, which are downloaded as specific dependencies for your OS, will be tried to be installed on a new computer with a different OS).
And yes, SAscore and QED can be combined in one node.
If you want to read up about KNIME and python setup I can offer this article.
Maybe best to create as yaml file with the necessary packages first, the an environment per operating system that you can then distill into a Conda Environment propagation.
This is where I hope the article can shed some light. The easiest way to use KNIME and Python is to use the integrated Python version in the extension.
Then: pip will just install the packages you tell it to install without considering the dependencies. Conda tries to manage them. So you might first want to use conda (via Miniforge), and if this does not work add additional packages with pip. Which is what the configuration (YAML) files suggest.