I need to do a left single match join in Knime, and with the Joiner node I can’t achieve this.
What I basically want to do is:
If there are duplicates of the identifiers, only one value from the new data will be kept, and added to the existing rows. That one row seems to be the one which appeared first in the new data. In the above example, the identifier ‘c’ is duplicated in the new data, so the first record (c,8) will be used in left single match and the other record(c,9) will not be considered.
You could add a -Duplicate Row Filter- after your joining:
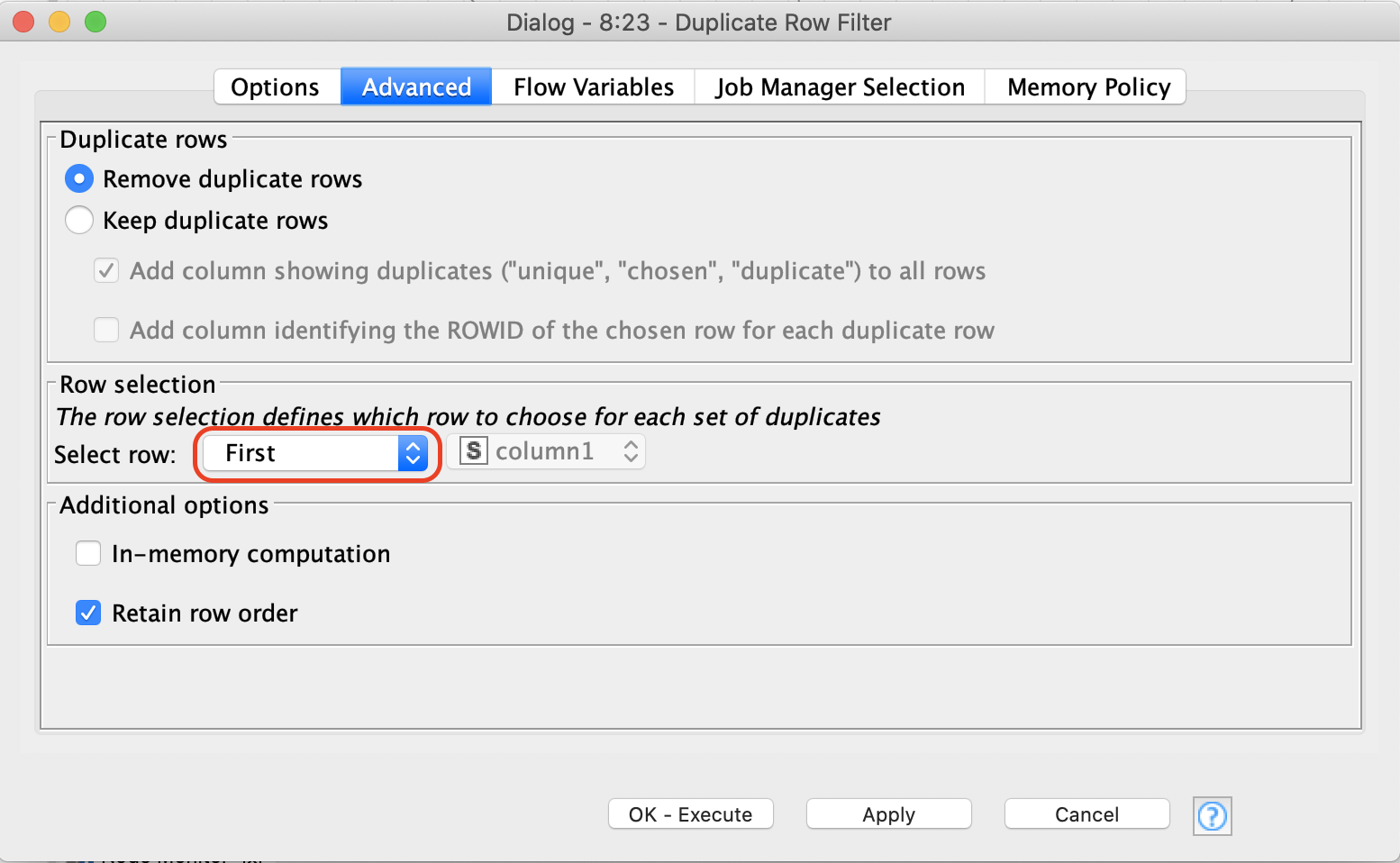
Since you need to keep only the first occurency of every duplicated join, the -Duplicate Row Filter- does exactly the job this way and hence it should work as you want.
for this transformation I would use a combination of a Duplicate Row Filter and Joiner node.
Step 1: Use the Duplicate Row Filter node to remove rows with a duplicate row identifier in the second table. For this make sure that “First” is selected as the row to choose
If you second table is not to large (regarding columns) another but probably more tedious option would be to group the second table first with first as aggregation and then do the join
br