Dear Knimers,
I’ve read several sequential CSV monthly files (in a continuous series of years), using the Knime workflow suggested in:
Then, I used the node “Extract table dimension”, to count the number of rows per file. But didn’t know how to insert this node in the workflow.
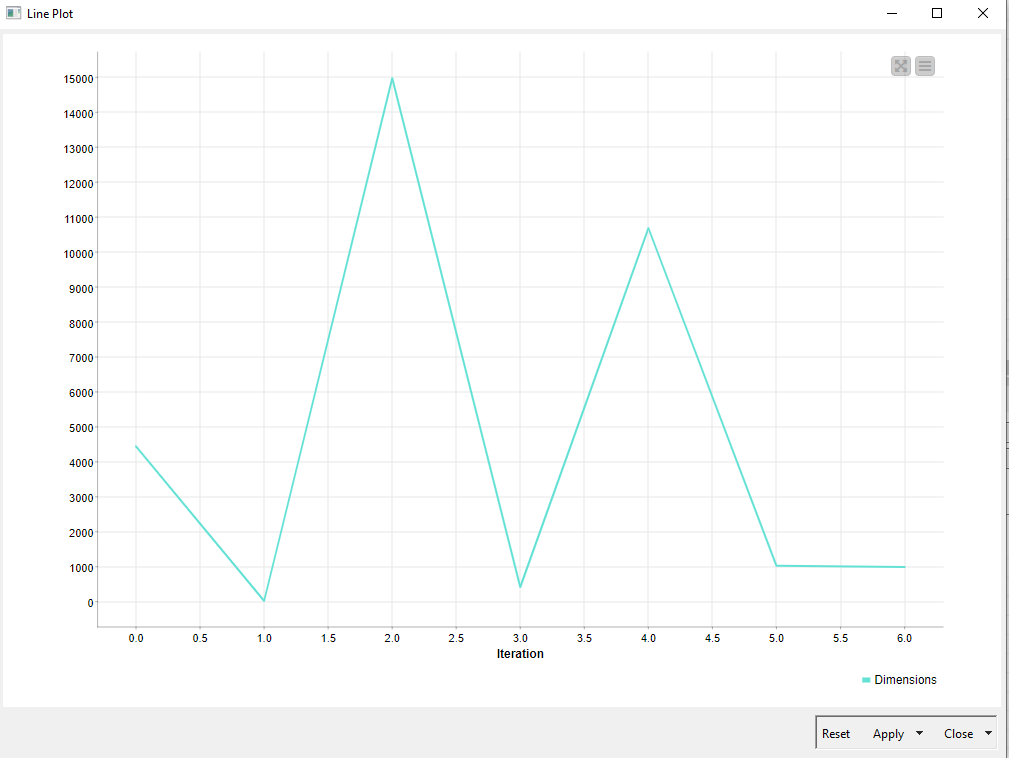
Next, I wish to plot these numbers of rows, to see how they have changed over time. This would be easy IF I could insert an additional column per read file, with these partial countings, so I could follow them by month, and sum them all at the end.
Thus, I need to add a column with these partial countings, without being obliged to count them manually. But I haven’t found a node called “add columns” or something like that. Can someone help me with this part of my task?
Thanks for any help.
B.R.
Rogério.
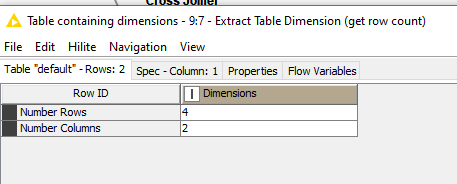
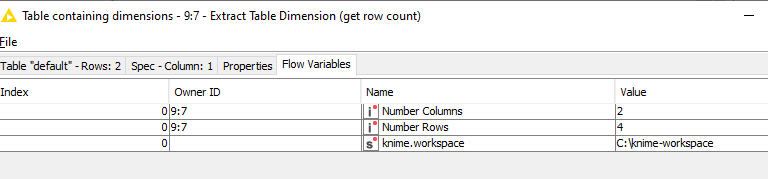
The Extract Table Dimensions generated row and column count information as both a table, and as a pair of flow variables, “Number of Rows” and “Number of Columns”, which gives you a few options for appending the count as a new column onto the table.
As Extract Table Dimensions returns a table in this form:
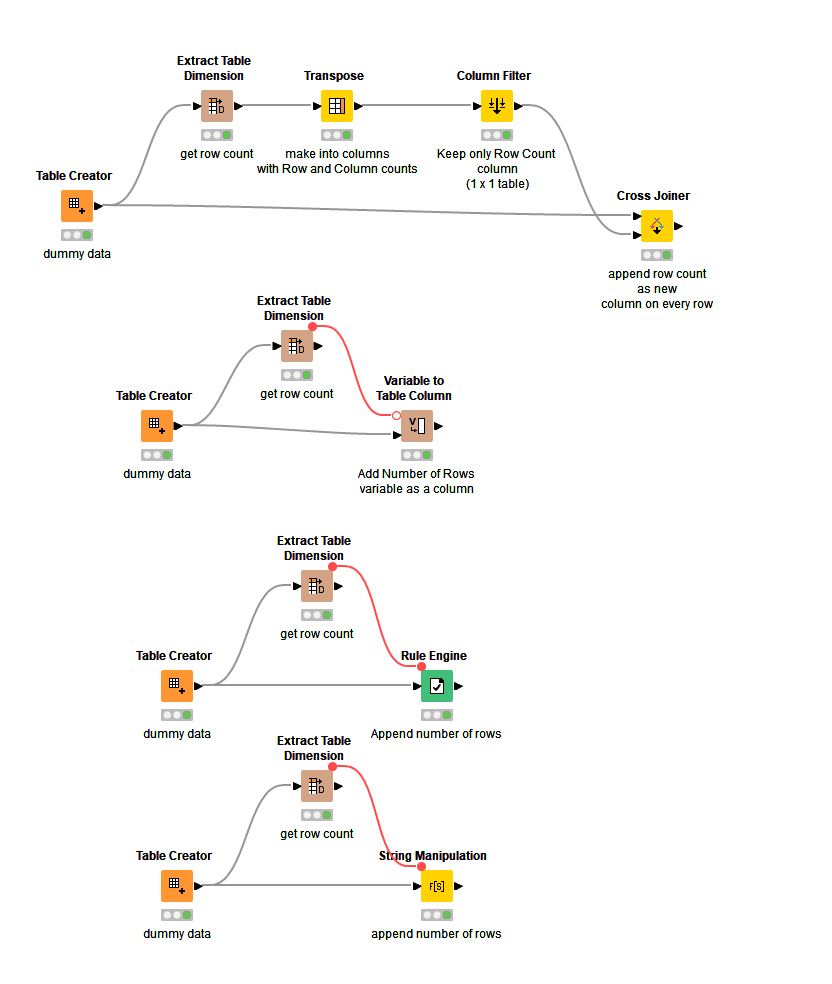
… to obtain a “Number of Rows” column, you could transpose the table, then retain only the “Number of Rows” column using a column filer and then cross join to the other table, or a possible alternative would be to use a row filter a Row Filter to retain only the Row ID “Number of Rows”, then rename the column as “Number of Rows” and then cross join. In the example below I have used the former option.
Note that Cross Joiner is only suitable here because the table being “appended” has been limited to a single row. If it had multiple rows you would end up with duplication if using the cross joiner!
Alternatively, as Extract Table Dimensions also returns the values as Flow Variables
Quick and dirty method based on the example workflow that you mention:
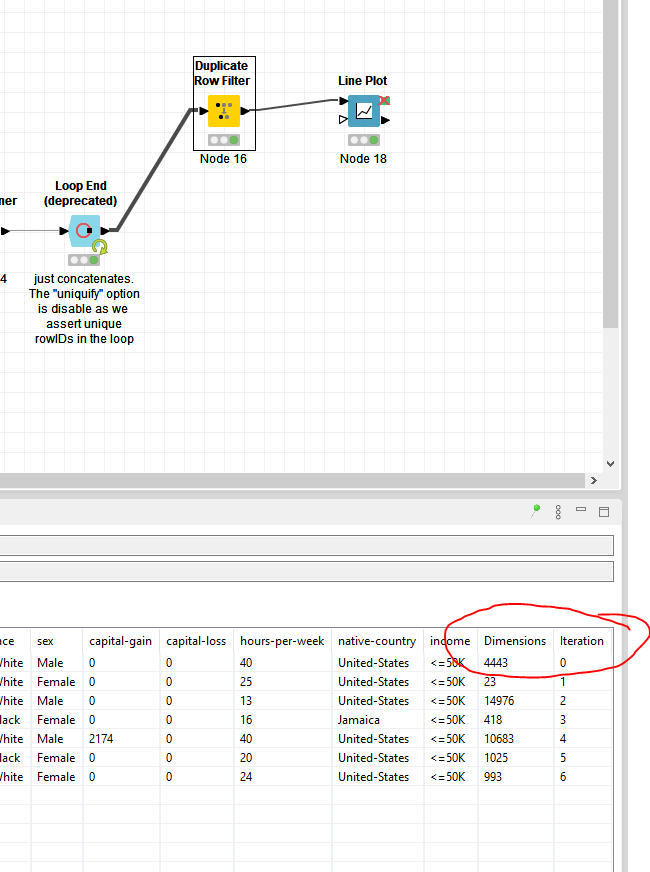
Within the loop, extract the dimension, filter the first row only to get the number of rows and use a cross joiner to associate that with the file that’s currently in the loop.
If you want to keep it simple, you can use the iteration as identifier. In your case it’s probably better to retrieve the filename or a particular month.
You can then in a separate data flow only retain the unique values of Dimensions and Iterations for analysis.
Dear @takbb (Brian) and @ArjenEX,
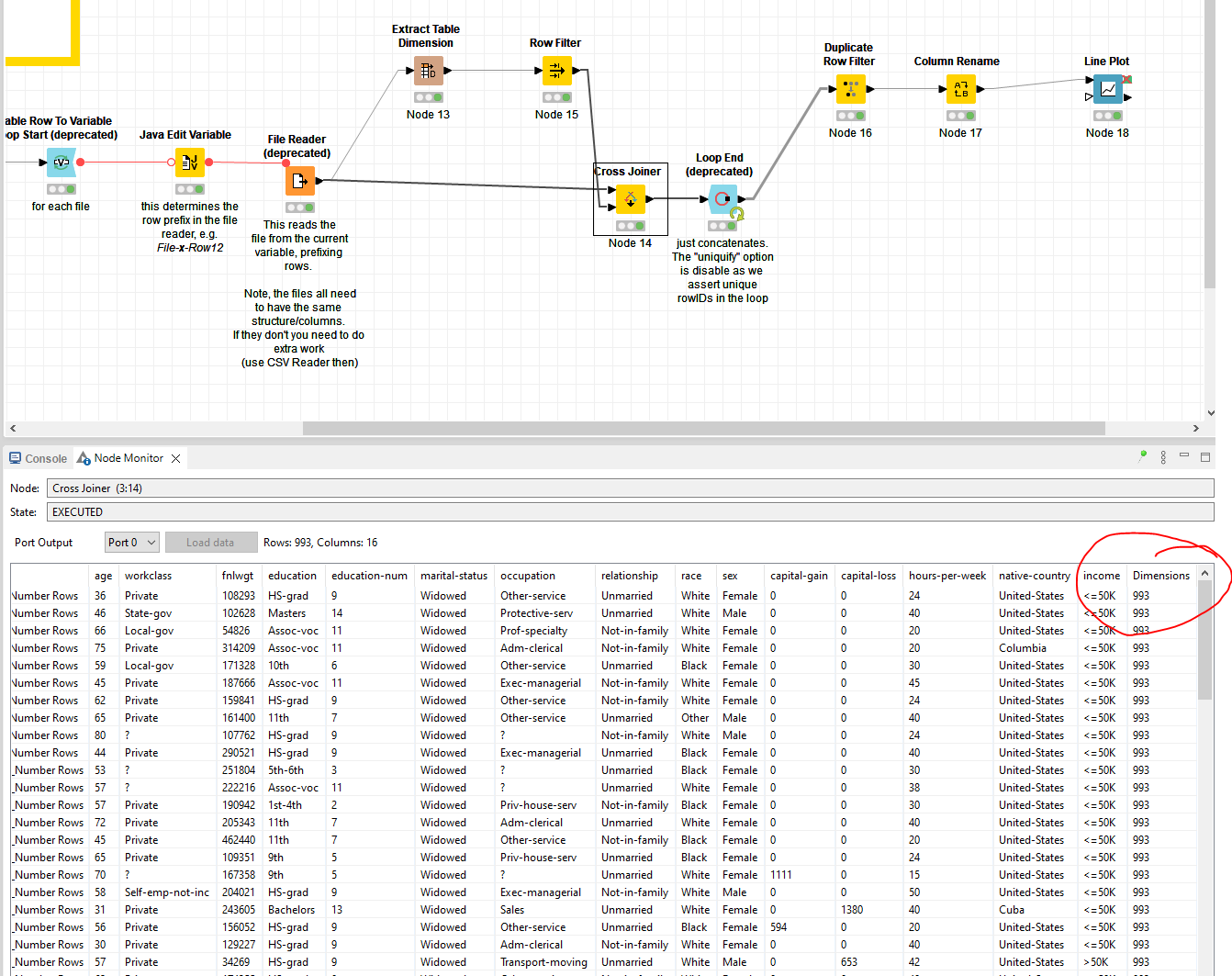
I’ve considered all of your suggestions (one by one), and it seemed to me (due to my own knowledge limitations) that the easiest option was to insert in my loop the combination of these two nodes: “Extract Table Dimension” and “Variable to Table Column”. They allowed me to achieve a table with the desired extra column, with the total number of records inside each of the monthly files inside my loop, having a unique cell value repeated along the entire iteration.
I deeply thank you both for all your help. Even though it was on a Sunday, you both have “saved my skin”. I was a little stuck on it.
All the best.
Rogério.