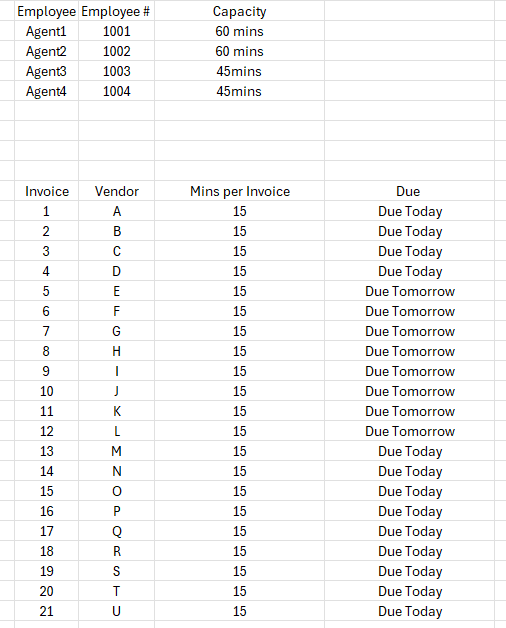
Here’s the list of the employees
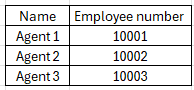
And here’s the data that should be allocated on the employees
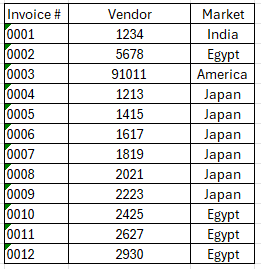
And I want to allocate the datas on my employee equally and this is the output I want
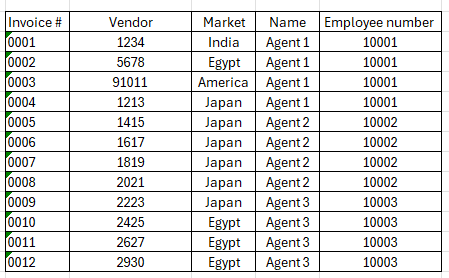
thanks for the help
Here’s the list of the employees
And here’s the data that should be allocated on the employees
And I want to allocate the datas on my employee equally and this is the output I want
thanks for the help
Hi @Elaine_Presa , welcome to the KNIME forum.
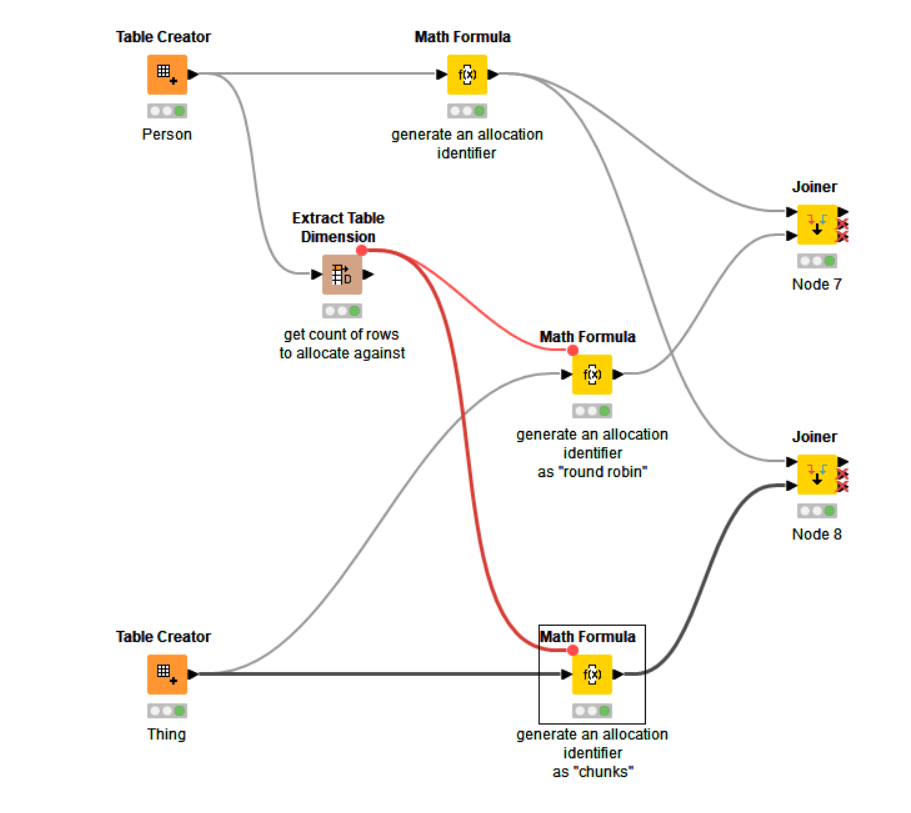
A relatively simply way to do this is to create a sequential identifier for each row in your employee table, and then assign an identifier mathematically to each row in the data-to-be-allocated table.
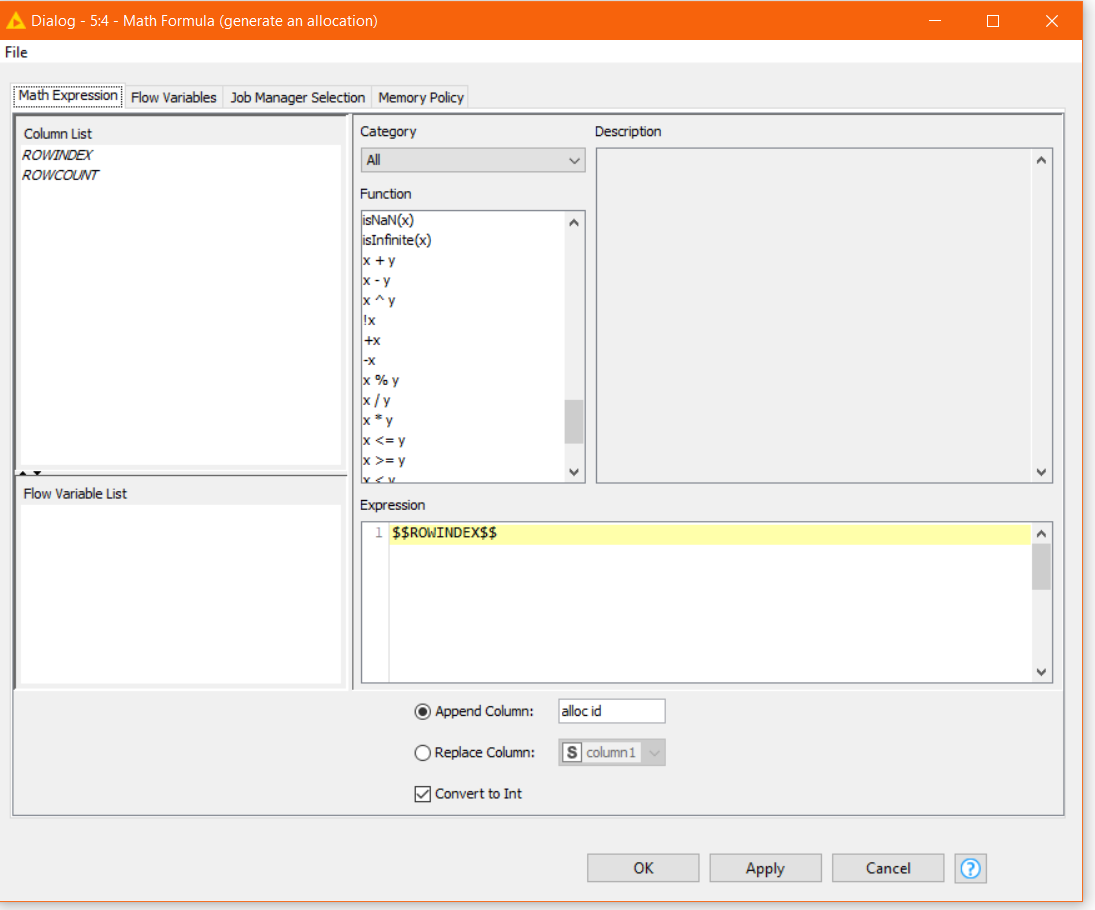
The follow math formula against your employee table will assign a numeric identifier “alloc id” starting at zero, simply using $$ROWINDEX$$. Make sure it is set to return as an int:
You can then use the Extract Table Dimension node to get a count of your employees, as this will be needed in a subsequent node to apportion the other data.
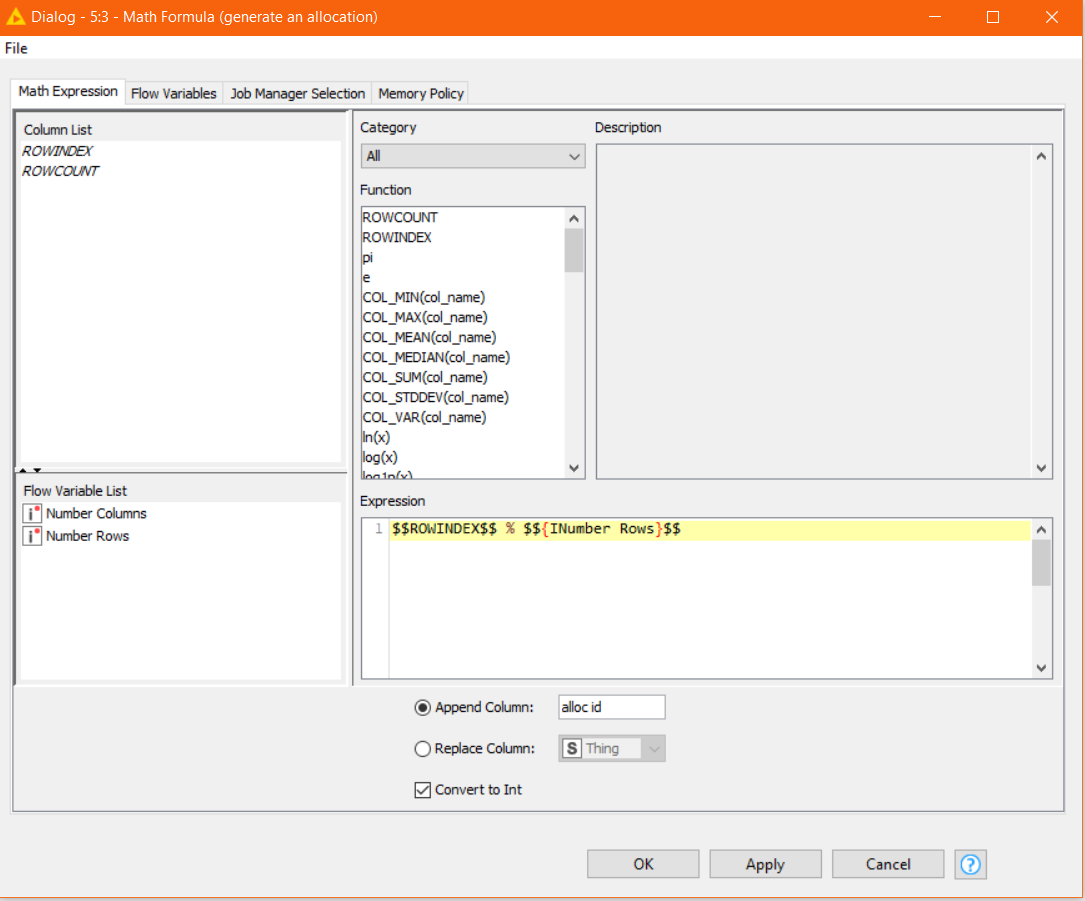
With the output of “Number of rows” from the Extract Table Dimension node, you can use either of the following Math Formulas to allocate an id to each data item:
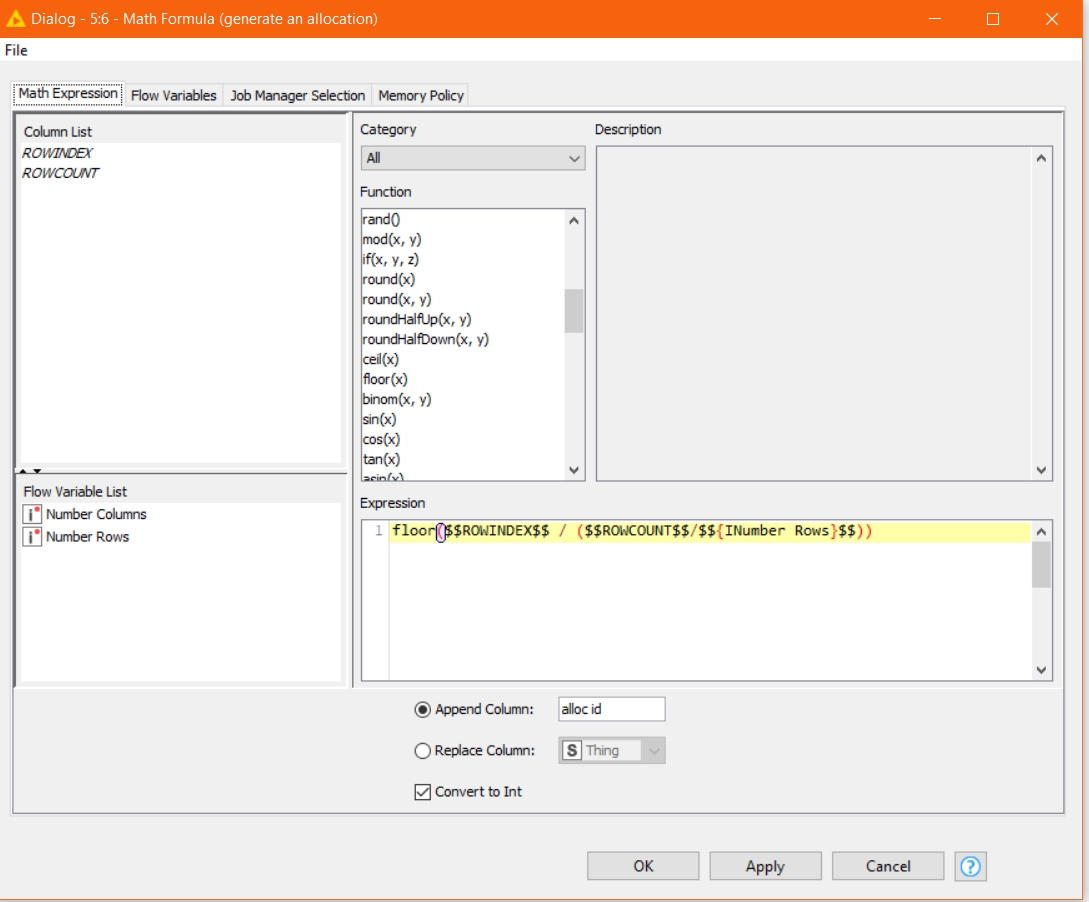
or
You then join the output from the Math Formula nodes with a joiner, based on the alloc id generated by the above nodes.
Here is an example.
Apportion rows for table join.knwf (20.3 KB)
If you need further help, using your data, please upload your data in textual form (e.g. as an xlsx or text files) so that it can be copied without having to retype.
@takbb Thanks for this. this one really works.
I would also like to ask if it’s possible to limit the allocation of datas depending on the employee capacity. Let’s say it takes 15minutes each invoice to be process, so technically each employee will have to work 60mins to finish all the invoices, however employee 10003 can only work for 45mins therefore he/she can only process 3invoices and the remaining one will be unallocated. Is it possible?
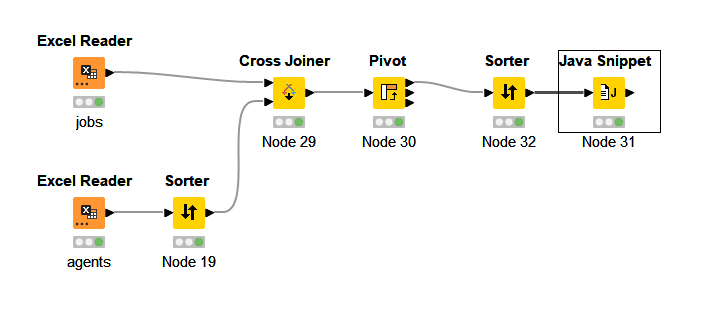
I’ve taken a simple approach—IMHO—by incorporating the Auto-Binner node to provide an alternative solution.
Attached are the screenshots, sample data, and workflow for your reference.
Hope this helps! Let me know if you have any questions.
Best,
Alpay


JobAssignment.xlsx (13.8 KB)
JobAssignment 1.knwf (20.6 KB)
Hi,
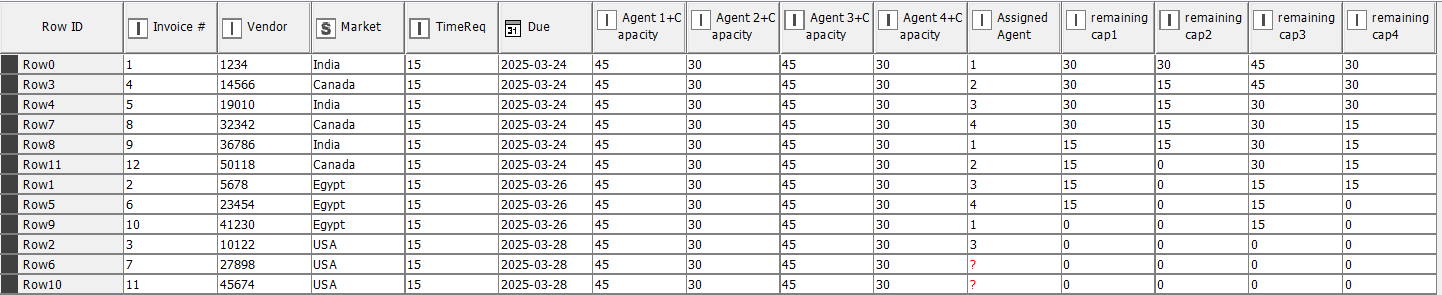
This approach requires us to track the balance between agents and their corresponding capacities, making it a type of balanced weight assignment problem. I used a Java Snippet node after assigning capacities to agents. The logic selects the first agent with the required idle capacity, assigns the task, reduces the remaining capacity of the assigned agent, marks the agent as busy, and then moves on to the next available idle agent for the next job.
For your convenience, I’ve attached the workflow, sample data, and screenshots.
Hope this helps! Let me know if you have any questions.
Best,
Alpay
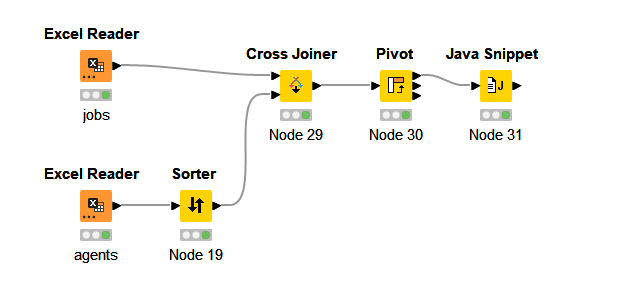

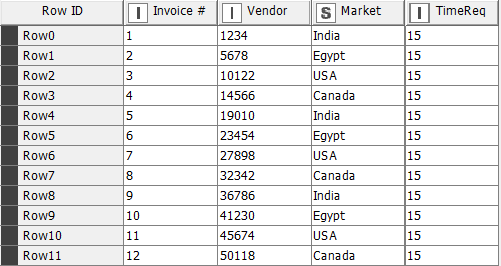
JobAssignment.xlsx (13.8 KB)
JobAssignment.knwf (35.5 KB)
thanks for this.
Also would like to ask is it possible to do this.
Here’s the input
And I need the output to be like this. Allocate the datas based on the capacity and prioritize the due today and the remaining unallocated will just have blank.
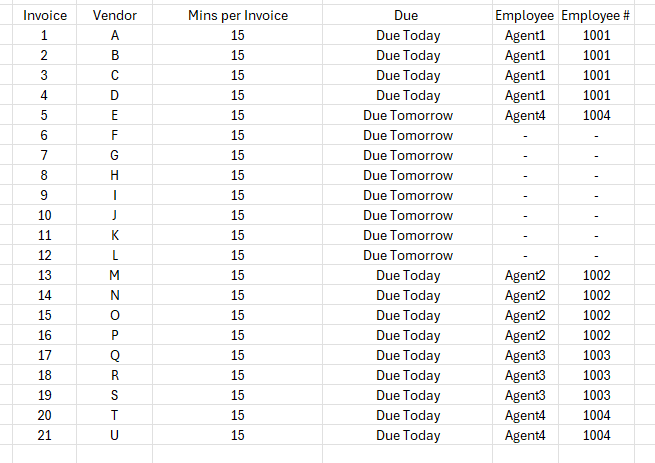
Thank you
Bitte.
I believe sorting based on date and invoice number (in that order) will give you the desired result.
When I reduce the last agent’s capacity below the total capacity required to complete the jobs, somes jobs remain unassigned, all lucky jobs proportionally distributed among the agents based on their capacities.
Let me know if you need any further clarification.
Here are the screenshots, sample data, and the revised workflow.
Best,
Alpay
JobAssignment 3.knwf (19.2 KB)
JobAssignment.xlsx (14.0 KB)
Hi,
I’ve revised my flow to provide a better assignment solution based on:
Hope this helps! I really enjoyed working on this case. ![]() @Elaine_Presa Below screenshot, data and revised worklow provided.
@Elaine_Presa Below screenshot, data and revised worklow provided.
Best,
Alpay
JobAssignment.xlsx (14.0 KB)
JobAssignment 4.knwf (27.5 KB)
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.