hi all
i have a excel data with 205 rows and split it in 2 part:
1.201 rows
2.5 rows
now when i write them separately with “csv writer” my row number 201 get duplicated
btw i used append in csv writer to combine them and i don’t want to use concatenate or duplicate row filter node
Welcome to KNIME.
The https://nodepit.com/node/org.knime.base.node.preproc.duplicates.DuplicateRowFilterNodeFactory might help you to solve your issue.
2 Likes
tnx for answering my problem but as i said i don’t want to use concatenate or duplicate row filter
is there any setting in csv writer to do this task?
CSV writer would just append whatever data you sent. If you want to avoid duplicates you would have to do it before.
If you want to refer to an ID you would have to read this back from the existing CSV and increase the number so it would start at the next possible value. Or you could use a database with primary keys that would reject any new entry violating the rule.
Maybe you could give us an example of what you want to do.
From my understand this would be 206 rows so there already would be one duplicate.
1 Like
thank you @mlauber71
first: i wanna read a 205 rows XLS file with file reader ,put first 201 rows limit on it and then convert it with csv writer.
second: read exact XLS file with file reader, put last 5 rows limit on it and convert it with csv writer and save it as same name as first one
the row count of XLS file and csv file should be equal
but i faced duplicated issue and don’t want to use any additional nodes if its possible
I am not exactly sure what this is good for and why you want to do it but this is also possible. You would have to specify the range of the data you want to import in the Excel Reader node correctly.
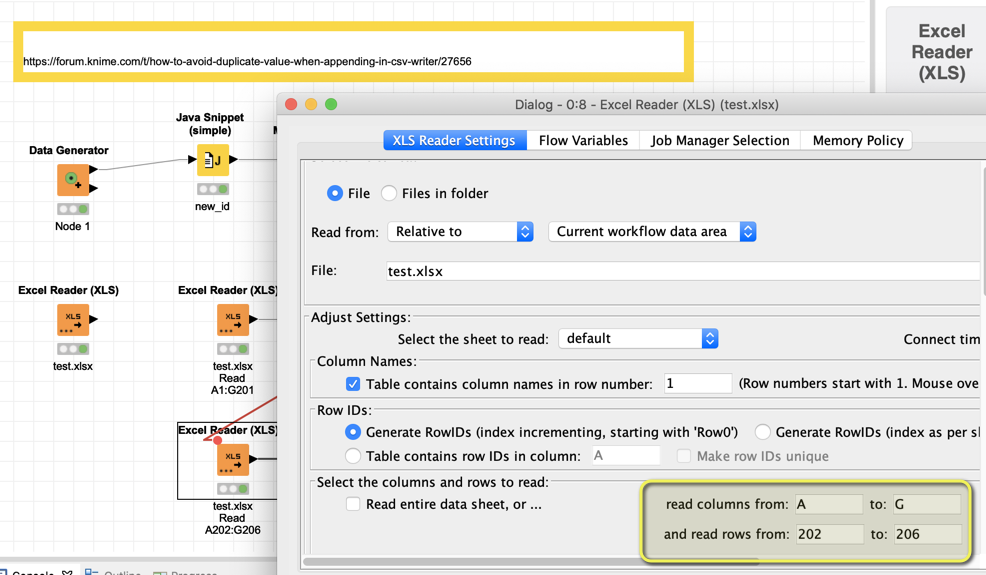
1 Like
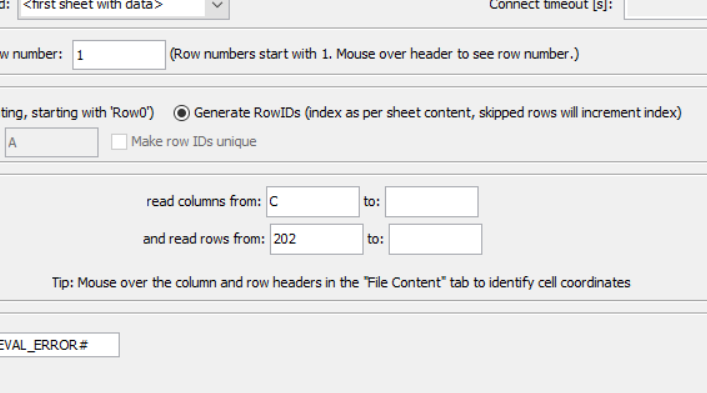
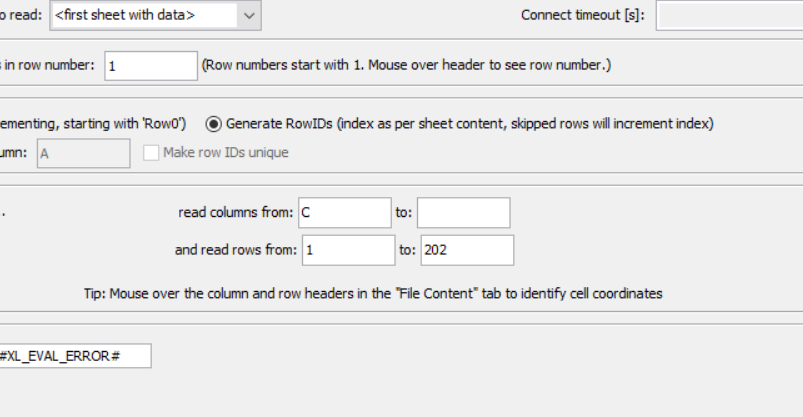
You read the 202 twice don’t you?
1 Like
yess according to the task i have to do this
Hey Mehrdad,
As explained and demonstrated by @mlauber71:
When you are asked to read the first 201 rows of an Excel file and if column names exist in the file, you enter 201 as the last row and you know that the first row contains headers so the imported table contains 200 rows with headers from the Excel file. Now when you read the rest of the rows or the next 5 rows, e.g. 202 to 206, and you still need to read headers, you enter the row numbers and read headers in row 1 so this time your imported table contains 5 rows as expected.

4 Likes
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.