one thing has bugged me for quite some time … not having a reliable backup solution for my workspace. Frequently, when travelling, I also have to sync the Knime workspace between my laptop and workstation.
I wanted to share a solution to the entire community and would love to hear your feedback. As follows an excerpt of my blog post providing more details.
One of the great things about KNIME is its flexibility—it’s a tool that allows users to extend its functionality, which is key for developing custom solutions. This is especially important when it comes to backups. KNIME lacks an automated process for workflow backups, and traditional tools like OneDrive can introduce issues like corrupt files or performance problems when trying to sync active workflows.
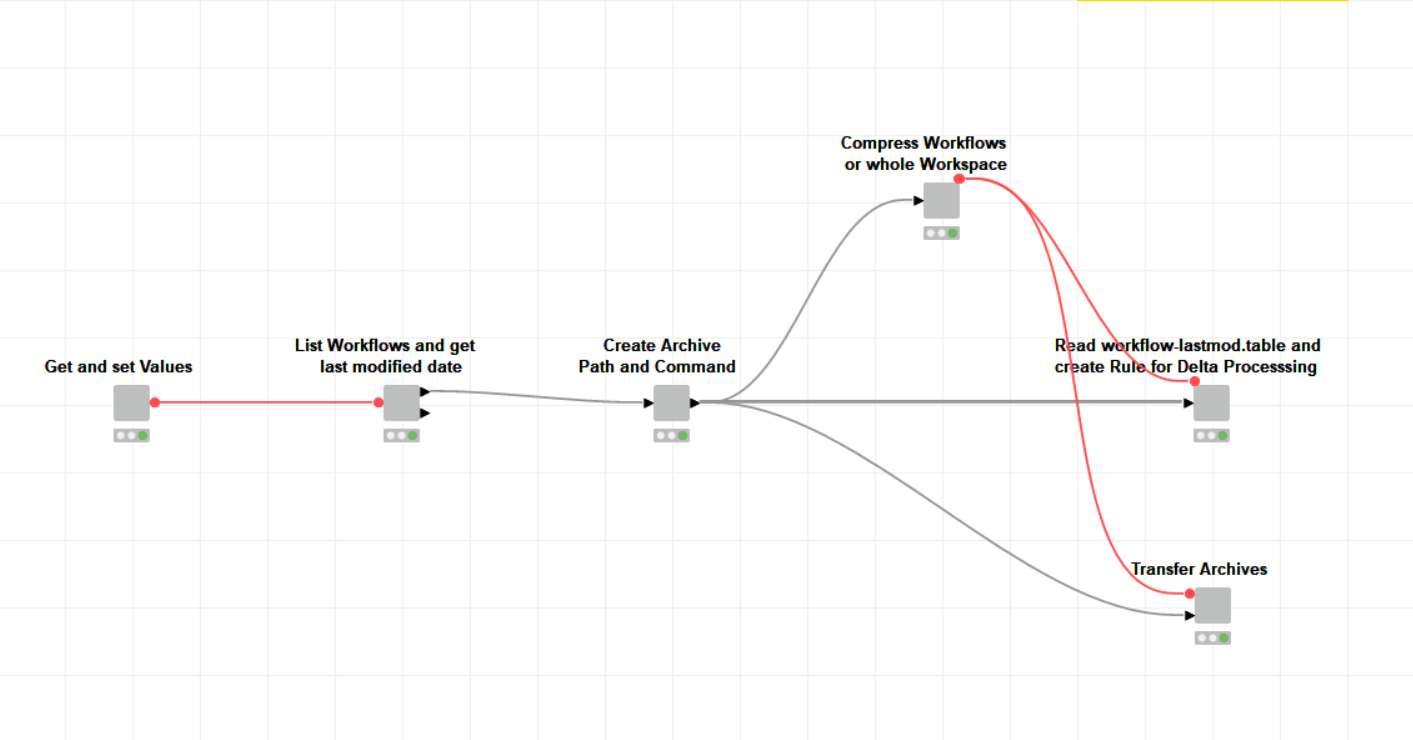
In response, I developed a custom workflow automation system to back up and transfer individual workflows or entire workspaces. The solution includes features such as:
Delta Processing (only backs up modified workflows)
Selective Data Exclusion (excludes large data directories)
This approach helps avoid common issues with traditional backup tools and ensures that KNIME workflows are securely backed up and easy to restore across devices.
One effective backup solution for KNIME workflows is integrating version control systems like Git. Since KNIME workflows are stored in XML format, they are text-based and can easily be managed through Git. This setup allows for delta comparisons, versioning, and collaboration, ensuring you can track changes and revert to previous versions if needed. By connecting your KNIME projects to a Git repository, you not only secure your work but also streamline collaboration with team members and maintain an organized development process.
Incorporating Git into the workflow would also open up possibilities for automated backups, CI/CD pipelines, and enhanced project management. It’s a robust and reliable way to manage workflow evolution over time.
yepp, I am already working on a 2nd version of the workflow. Though, it isn’t that easy to just put the workspace under version control because:
Open workflows should not be synced
Data-Directories, Port-Data and artefact data should not be synced but that, due to the dynamic folder structure, is difficult to manage using gitignore file
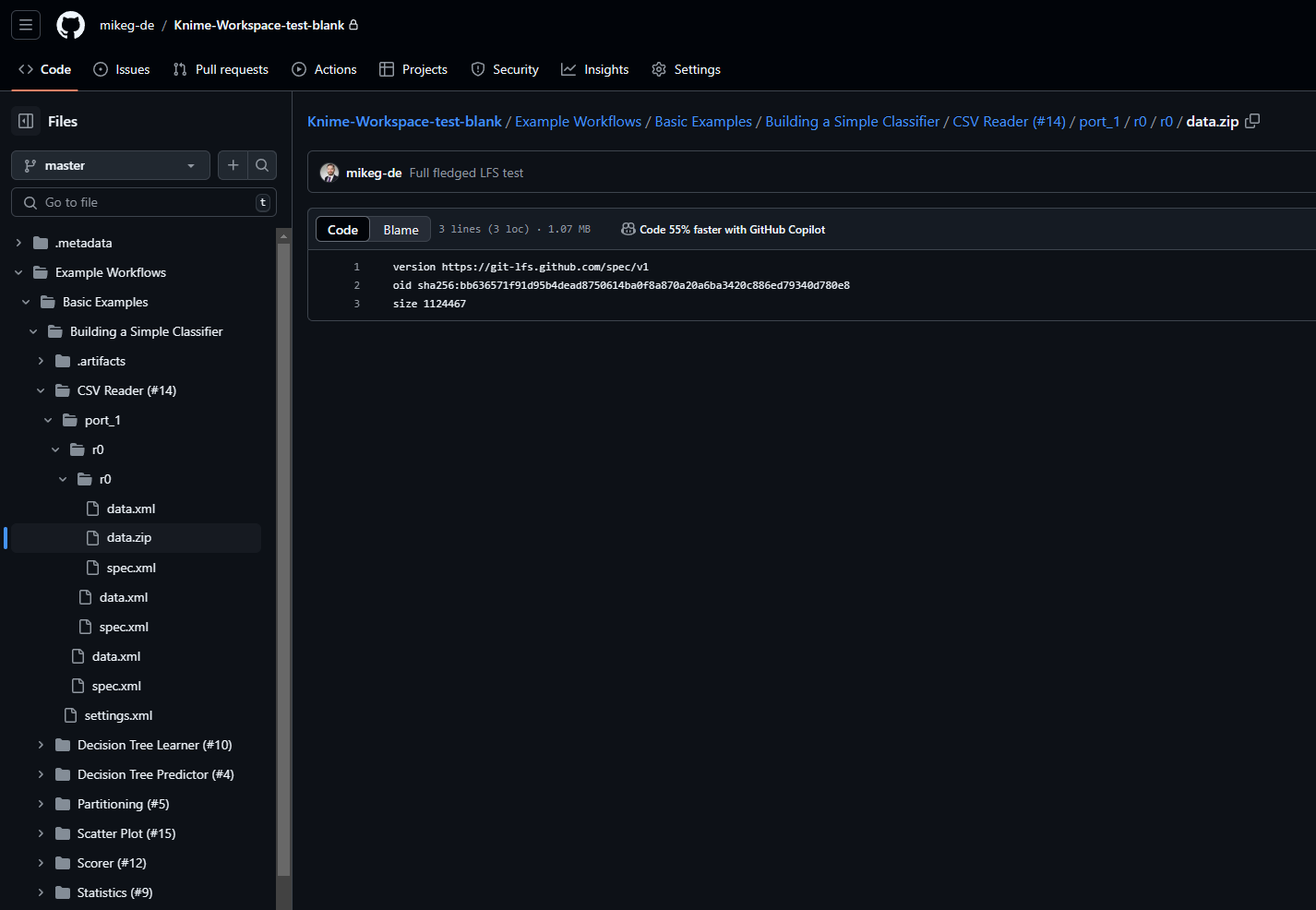
Data storage, for large files, in general should be done using an Large File System Server (read about LFS)
and a few more important details
Work is already in progress and I am confident to provide a “Definite guide to leverage a (git) Repository with Knime” in the near future. In fact I am already beyond POC phase
IMPORTANT - READ EVERYTHING BEFORE JUMPING HEADS ON INTO POTENTIALLY SHALLOW WATER. I AM STILL TESTINGB THINGS OUT!!!
I.e. when testing the process on my production workspace I encountered two issues which I added in the notes section at the very bottom.
Update
While proceeding to commit part or my entire workspace I encountered a significant perform regression in staging files. This seems to be relates to LFS and data being copied to local cache. I am investigating.
Summary
It was actually quite straight forward after I sorted out the permission hustle and had gone astray about using a reverse nginx proxy with certbot. Worth to note, I had much already set up like GitHub, AWS and Docker saving quite some time.
I am consolidating all information with screenshots and more in one or two blog posts – one for causal (local only) and another for business / enterprise (with fancy AWS S3) users. Here is the “executive summary” in case you can’t wait and want to get started.
All in a nutshell
Full versioning of the entire Knime Workspace
Use GitHub Large File Storage LFS to store data which shall not end up in the repository
Works independent from Knime
What it does NOT do (yet)
Identify open workflows to prevent them from unintentional sync
IMPORTANT Test before utilizing this approach on your production workspace. This also helps identifying possible mistakes of mine, local customizations (i.e. security measures) but also makes you familiarize with everything!
Create a new workspace
Knime will / should automatically insert the example workflows!
Preparations
What you need for the fancy business / enterprise solution:
GitHub Account and GitHub installed (I opted for sourcetree)
AWS Account, a IAM user for your app with credentails (Access and Secret Access Key)
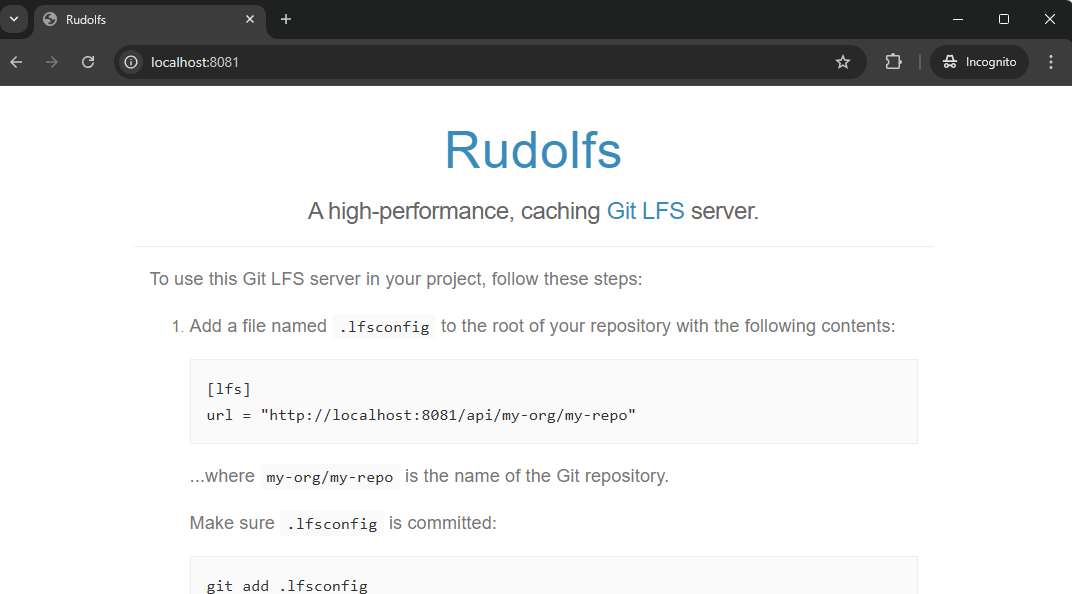
Rust installed (literally a five minute job: Install Rust - Rust Programming Language) as it’s required by Rudolfs in case your want to store data locally or for testing purposes
About LFS_MAX_CACHE_SIZE, I chose a value that resonates with my disc size and actual workspace data consumption. Adjust as you see fit.
Disable file encryption (read note #1 below!) by modifying the file docker-compose.yml, comment line in the “environment” section containing LFS_ENCRYPTION_KEY as well a in section “entrypoint” the lines containing key and ${LFS_ENCRYPTION_KEY}` right thereafter
Docker App
Open Shell/PowerShell and navigate to the folder where Rudolfs is stored like cd 'E:\git\rudolfs'
Start the docker image by executing docker-compose -f ./docker-compose.yml up -d
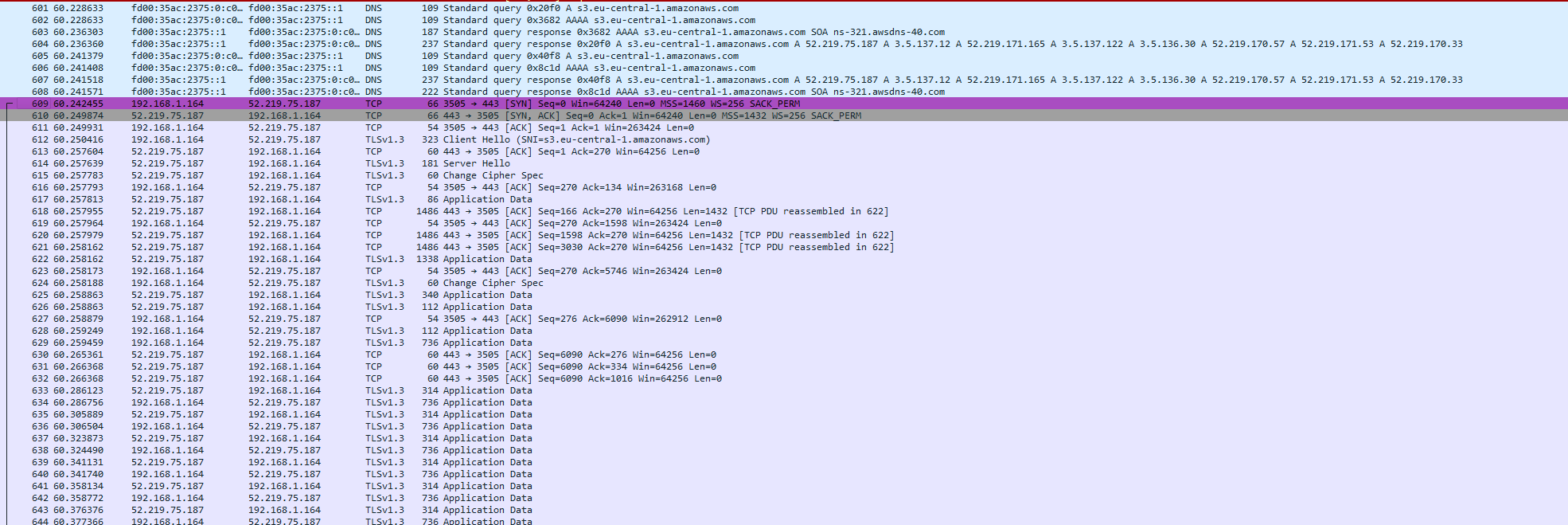
Notes #1 - File Encryption in Rudolfs
I chose not to for testing purposes on one end but also confidence, because I knew but also verified again, in data being encrypted during transmission and storage anyway. See my wireshark capture below.
It is likely going to take some time to get everything sorted and double verified but I feel quite confident that an average user should be able to follow the steps above.
I am also still thinking about the implications of synchronizing open workflows whose data I being generated. I got to test this later on. In the mean time … happy Friday!
#2 - Git error “Error open Filename too long” - Enable long file path support
In “6. Execute these commands” a command was added to enable long file path support ass I encountered this error “Error open Filename too long”. Mode details here:
#3 - Git error “LF will be replaced by CRLF the next time Git touches”
It seems Knime is not using the systems default line break character (on Windows) resulting in an influx of these warnings “LF will be replaced by CRLF the next time Git touches it”.
The implications are uncertain at the moment and I am still TESTING if Knime and Git would permanently interfere. Worth to note, my Workspace was once created on OS X. Read more here:
Let me know if anyone has any question. Feedback is always welcome!
Hi @mwiegand, that’s a great tutorial. I’m just curious, what do you use to manage secrets for APIs and user passwords used in KNIME nodes to avoid syncing those to GitHub?
KNIME has a secret management function in the server version and I believe the KNIME team is working on bringing this capability to the Team version (Cloud) but I don’t know what would be the best way to handle it until add it to the cloud version.
great question. First, expect that credentials are not saved in clear text. Which, as long as you don’t hard code them, should be the case. Sometimes, though, it is better to not blindly trust but verify.
I set the AWS credentials in the backup workflow I shared in the first post of this topic and verified no clear text data is saved by checking the config and port data saved on the disk.
In short, if permanent storage of credentials was chosen Knime stores them securely in the KNIME workflow repository. These credentials are encrypted when saved. The encryption ensures that sensitive information is protected from unauthorized access.
Going one step further I checked the repository:
I searched through it but the data is too much to provide a solid answer. This is more a question a developer would be suited to answer. Hope that helps.
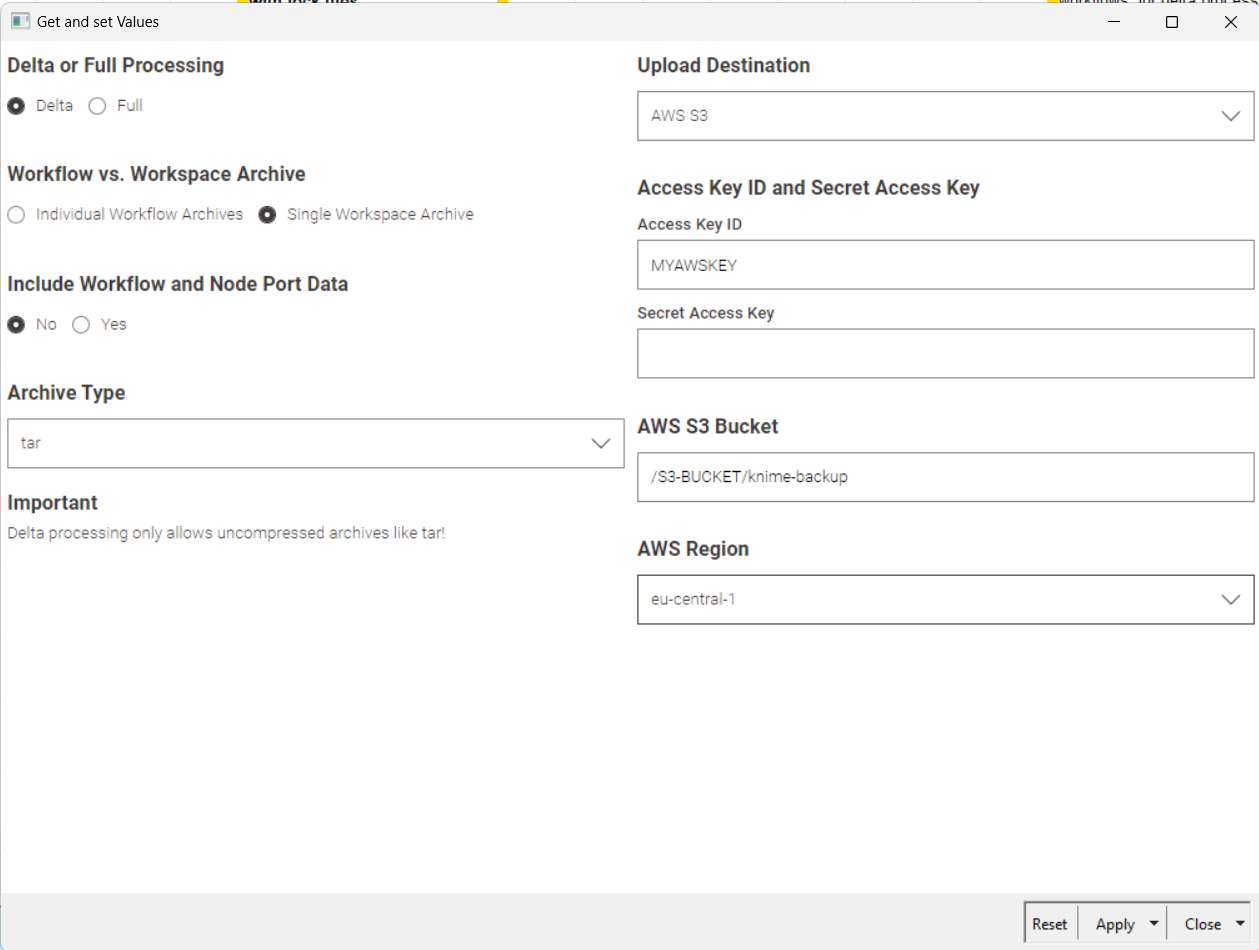
as an early Christmas present I am proud to let you know the release of version 2 of my backup workflow, introducing a wealth of new features, including but not limited to:
Biggest change: Restore Feature (Restore from AWS S3 WIP)
Chose between backup locations Workflow Data Directory (default), Local (can be a network or thumb drive) or AWS S3
True delta Processing even with enabled compression
Ability to set a password
CRC Checks by default to ensure data integrity
Compression level can be selected to balance size and speed