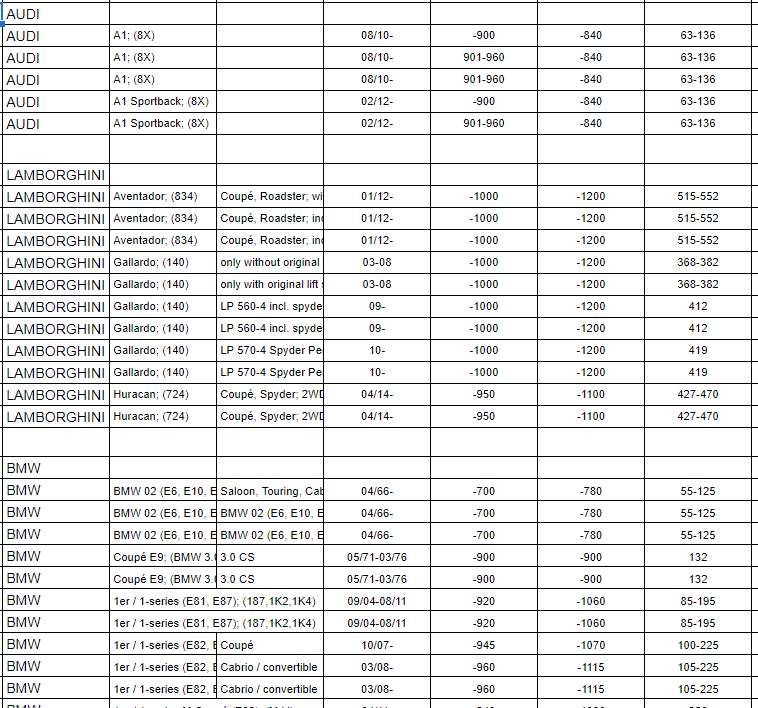
Hi, we get a lot of data in this format where the supplier has ‘helpfully’ formatted a spreadsheet so that if you print it out, you get a nice catalogue for a human to read, but we don’t want this, we just want the data from it.
Here’s what we get
I know we can use the MISSING VALUES node to fill in all the empty cells with the data from the cell above, but how can we convert these yellow data rows that only contain a car make value into a new column value that applies to only the rows until the next one is hit ?
Any clues gratefully received
thanks,
James
Hi @DWJames , it would be nice if you could provide the data. We can’t copy and paste the data from the image. And I don’t see why we would have to manually type the data to help come up with a solution
For AUDI, why are there 5 entries instead of 4? I only see 4 from the input data, unless the empty row is counted as the previous row?
And to answer my previous question, it does seem like an empty row takes the same values of the previous row. It’s doing it for each of them in each of the car brands
EDIT: Sorry, file is good, I just did not expand the sheet properly.
Can you please confirm on the behaviour for the empty lines?
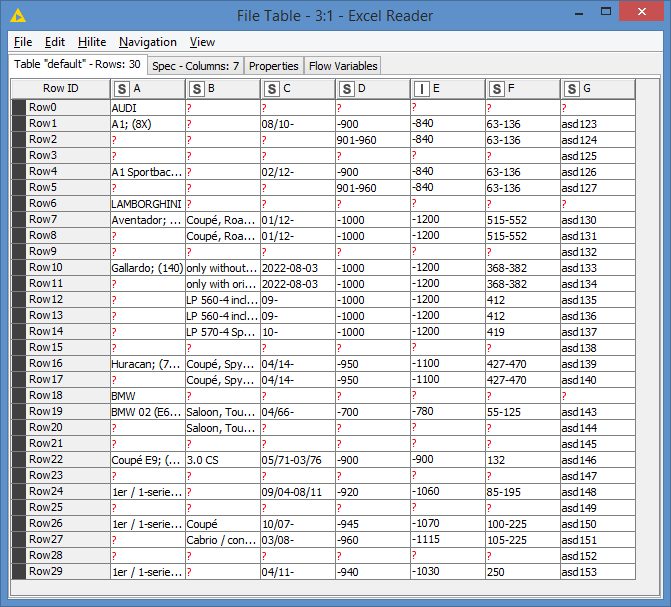
in the original data, further on the right hand side there are more values for part numbers, so we must always copy down these first few columns via ‘MISSSING VALUES’ node. car-data-sample2.xlsx (11.6 KB)
Here is a second data example to replicate this behaviour of the extra part number column.
Thanks for the second file. I see, so they’re not actually empty lines. It seems like all empty cells within a brand should be taking the value of the cell from the previous row (except for the Brand Header row). Is that correct?
Hi @DWJames , there are a few ways to do this, and can be done without loop. But without a loop, it will become tedious to clean up some rows, one column at a time if I process them all at once (Knime process data row-wise, meaning if I have to clean up 7 columns, I need 7 operations, potentially 7 repeating nodes, or eventually use a loop).
I’m actually going out of my way to include the empty rows between the brands
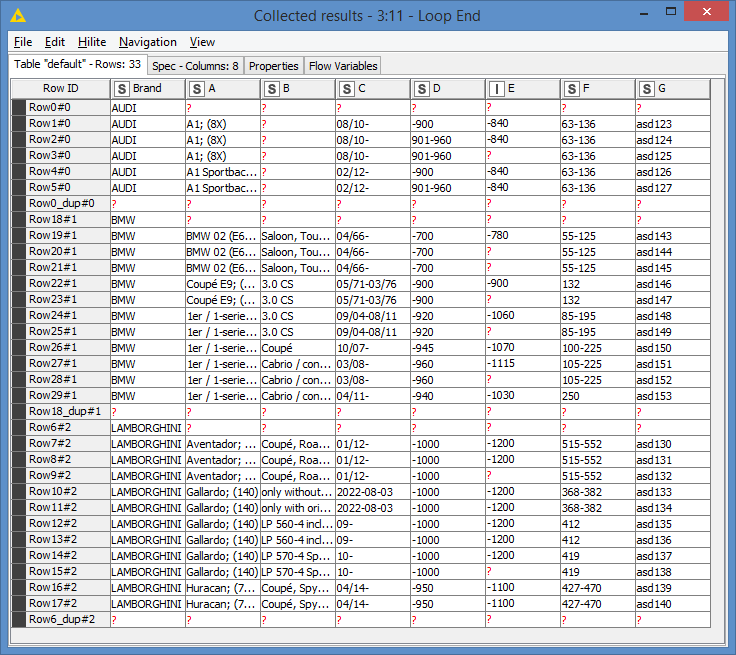
Knime re-organizes the groups involved in the Group Loop, in this case the Brand column, that’s why the data is sorted in on Brand alphabetically. You can always resort if needed (let me know if you have trouble with that, I can help).
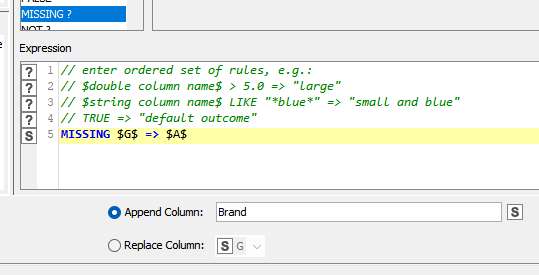
So, in this Rule Engine, this states ‘if column G empty = true, then place column A into new column Brand’? That’s cool, and as with most things we found with KNIME, it can be quite elegant and simple once you know how
Now for stage 2, I have to work out how to pivot the rest of the data, but I will make a separate post for that