Hi @DWJames , there are a few ways to do this, and can be done without loop. But without a loop, it will become tedious to clean up some rows, one column at a time if I process them all at once (Knime process data row-wise, meaning if I have to clean up 7 columns, I need 7 operations, potentially 7 repeating nodes, or eventually use a loop).
I’m actually going out of my way to include the empty rows between the brands ![]()
This is what I came up with:

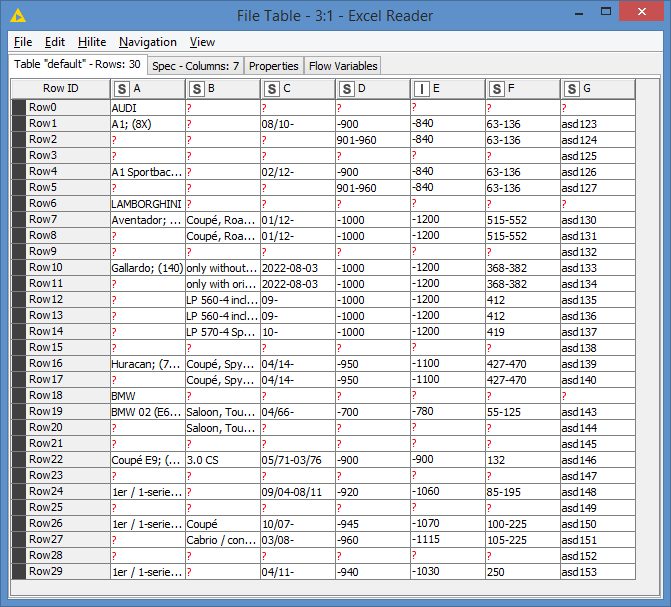
Input data:
Output:
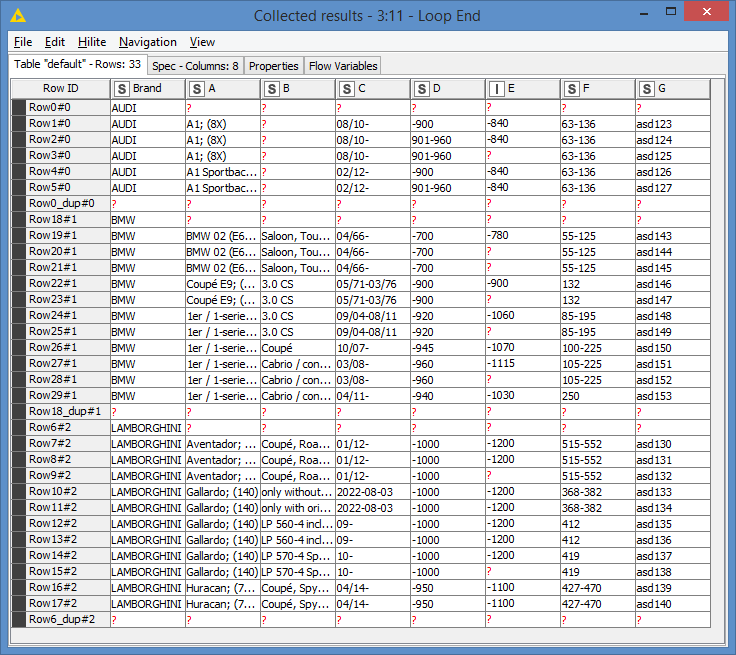
Knime re-organizes the groups involved in the Group Loop, in this case the Brand column, that’s why the data is sorted in on Brand alphabetically. You can always resort if needed (let me know if you have trouble with that, I can help).
Here’s the workflow: Change catalog to spreadsheet format.knwf (40.3 KB)