Group Key|Col1
100|C
101|R
101|C
101|…
102|R
102|S
How to filter all those rows, where there is atleast one record each with “R” and “C” in Col1 for a given group key?
What I have done,
Group Loop Start → Removed all duplicates for Col1 …
From here I am able to get if the count is more than 1 using a GroupBy (meaning two unique values in Col1 for two rows).
How do I compare that those values are “R” and “C” one in each row.
I am thinking of using Java Snippet and iterate through the group, and use temp variable to find if both “R” and “C” are found, and filter them. But then it is like a programmer. Any other way in Knime?
I am not sure if I fully understand the output, but I tend to lean on the Rank node to do counts per group. Then you could easily filter down to just the groups containing a requisite number of rows per group (or target individual row numbers per group if you use ordinal)
You can also use your Rank output to drive a group by loop for additional options
Hi @marzukim Thanks for the workflow, but it is picking up those groups where, either “R” or “C” is present. However, the use case requires to filter out those groupKeys where both “R” and “C” are present in the dataset.
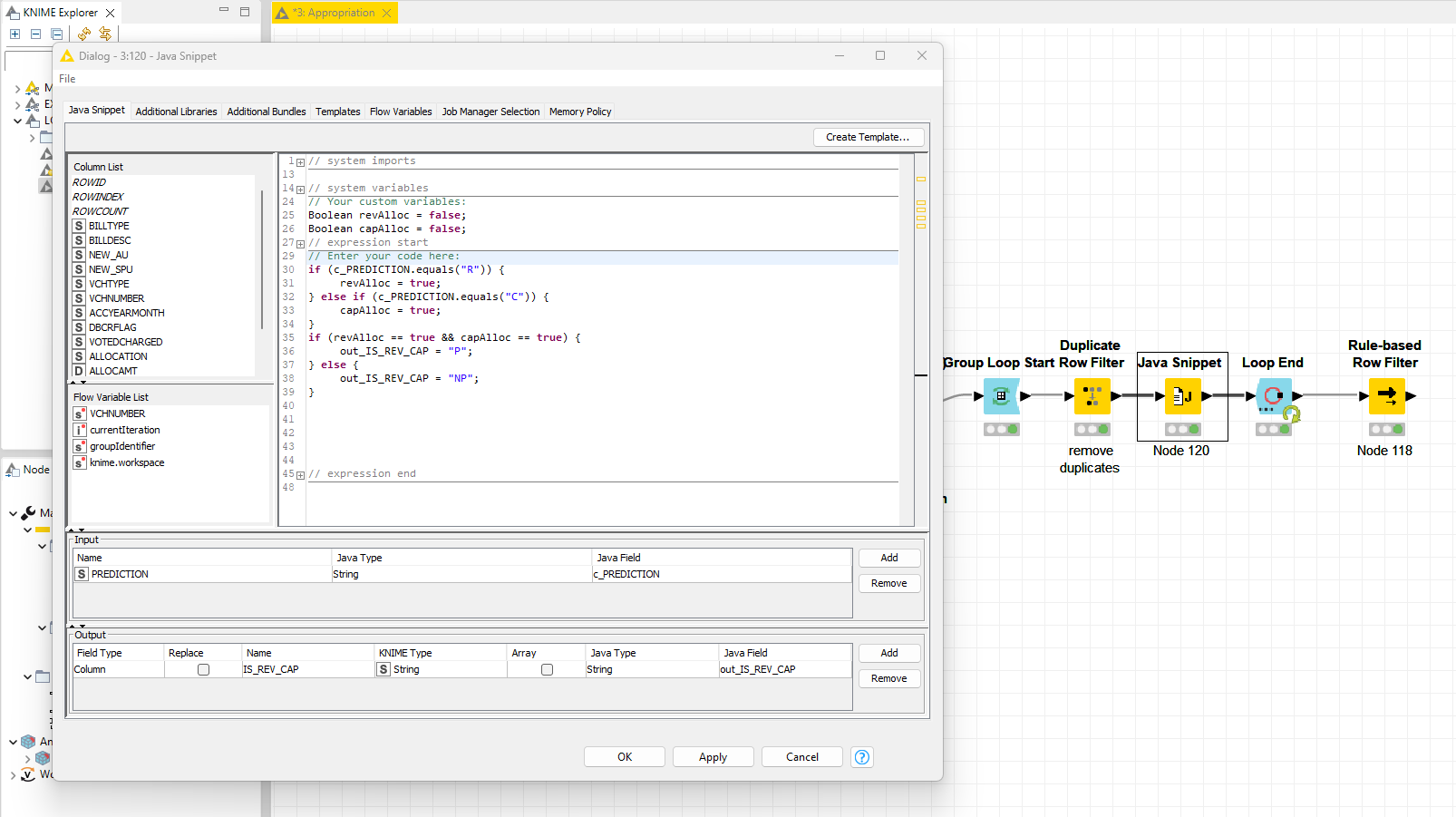
I have achieved the same using Java Snippet this way:
The custom variable in Java Snippet is available at Group scope, I iterate all the rows and set the flags if “R” and “C” are found. Then if both the flags are true, I output some status (ex: “P”). Then filter out all those group keys, based on the status.
if i understand correctly, you want to filter out all the R and C keys. you can do either by using column expression node, the rule-based row splitter node to split the unwanted keys or by reversing the logic condition in the row filter node in my workflow …
@marzukim
Its not regular filter. What I am trying is, the filtered group should contain both the records: one with “R” and another with “C”. If a group is just having “R”, it should not be selected, and likewise, if a group is having only “C” it should also be not selected.
Are “R” and “C” actual static values, or are you just using those as an example of values that could vary by group?
You could just concatenate all of the unique values into 1 column and filter via a Regex match on both of those values to see which groups contain both. Then you could filter out the groups that don’t meet your criteria.