I am fairly new to KNIME, so apologies if this is “obvious”. Was not able to find any references thus far:
I am trying to implement a simple text processing pipeline, leveraging the sample workflow “19_Analyse_and_Visualize_Job_Postings”. As input, I replaced the table reader with a Tika parser. So far so good.
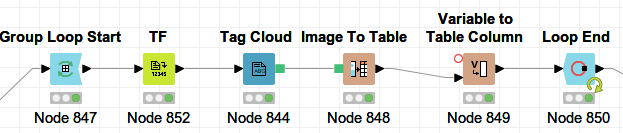
However, at the end of the pipeline, I would like to create one tag cloud per document, instead of one tag cloud over the entire set.
The last node before the tag cloud node, a Frequency Filter, contains each a row for each relevant term and it’s frequency by document. What I am now trying to do is instead of displaying a tag cloud for the entire output of the Frequency Filter, create tag clouds by document. I looked at chunking, but that seems to have only number of rows as a parameter. Equally, group-by also does not seem to work, as it changes the structure of the data.
Any help how to achieve this would be greatly appreciated!