Dear Sir,
On my raw excel data see attached

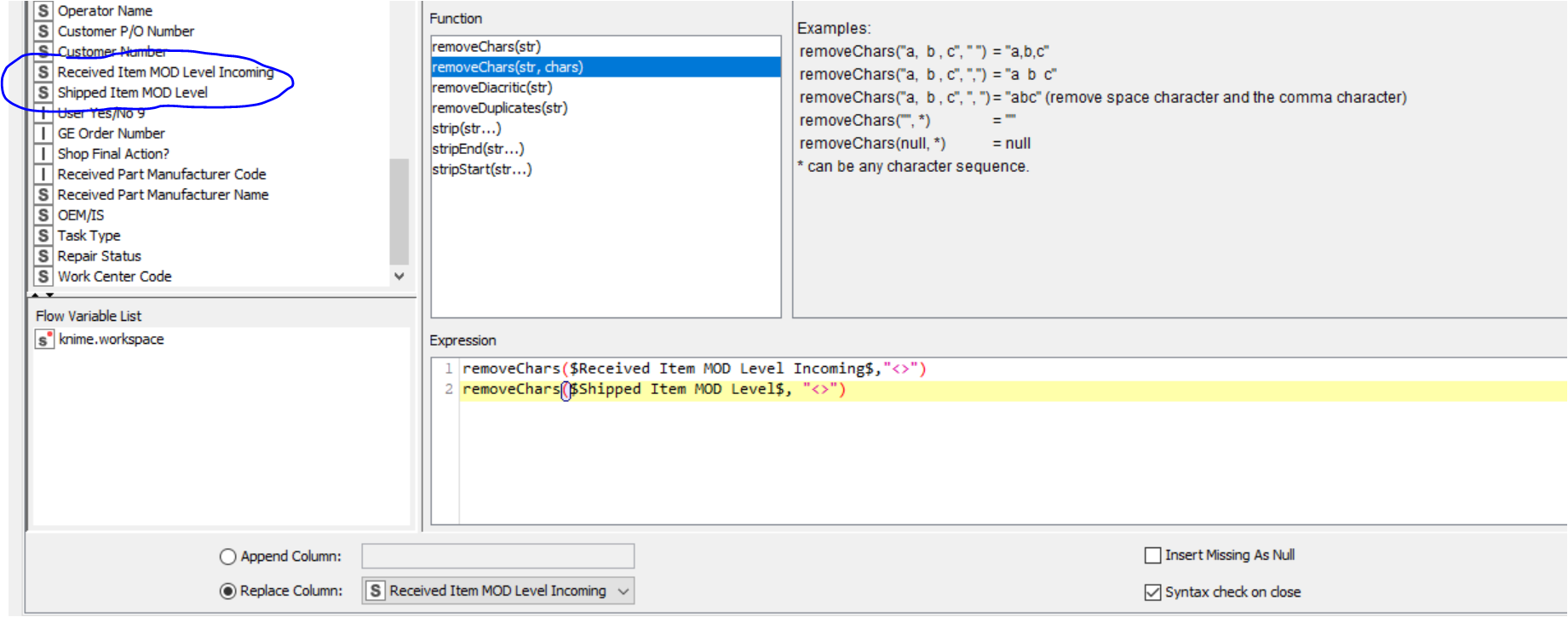
There is < > bracket in the data, I would like to remove the bracket by string Manipulation but I am not sure which function to use. Is there any advise from the experts, please ?
Best Regards
CK Lau
Dear Sir,
On my raw excel data see attached
There is < > bracket in the data, I would like to remove the bracket by string Manipulation but I am not sure which function to use. Is there any advise from the experts, please ?
Best Regards
CK Lau
You are looking for removeChars($column1$,"<>").
Hi ArjenEX,
Thanks . If I have two columns need to do remove the “<>” can I use one String Manipulation node or I need two nodes ?
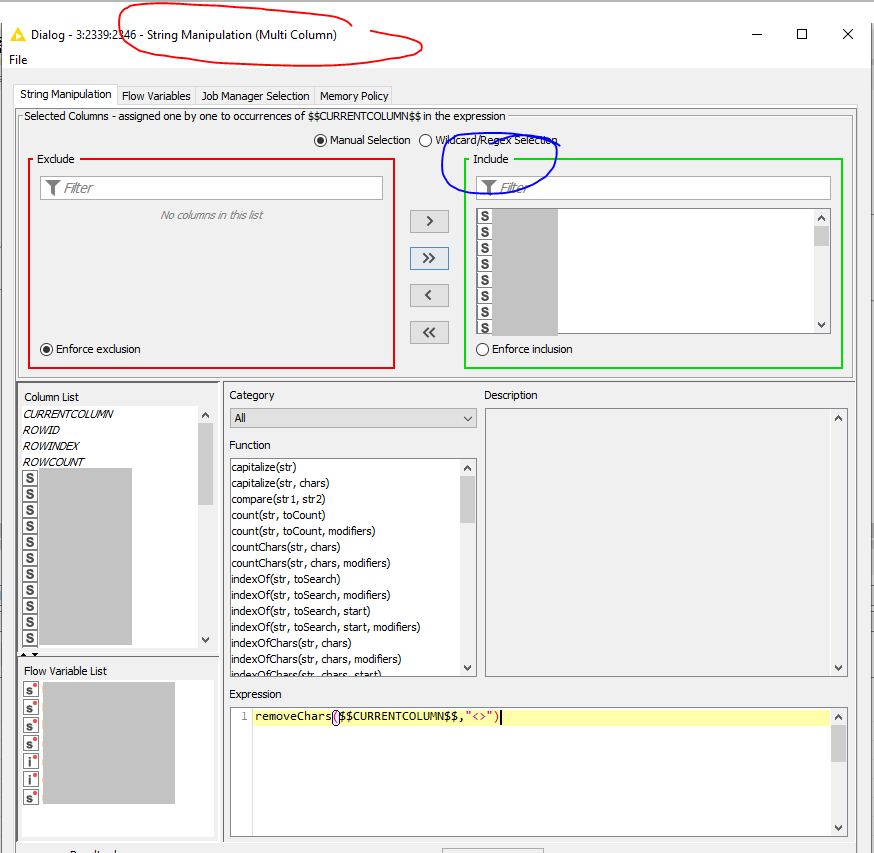
Switch to the Multi Column version of the String Manipulation node and use removeChars($$CURRENTCOLUMN$$,"<>"). All columns that you want to have cleansed should be in the Include section.
Thank very much ArjenEX
Hi Alex,
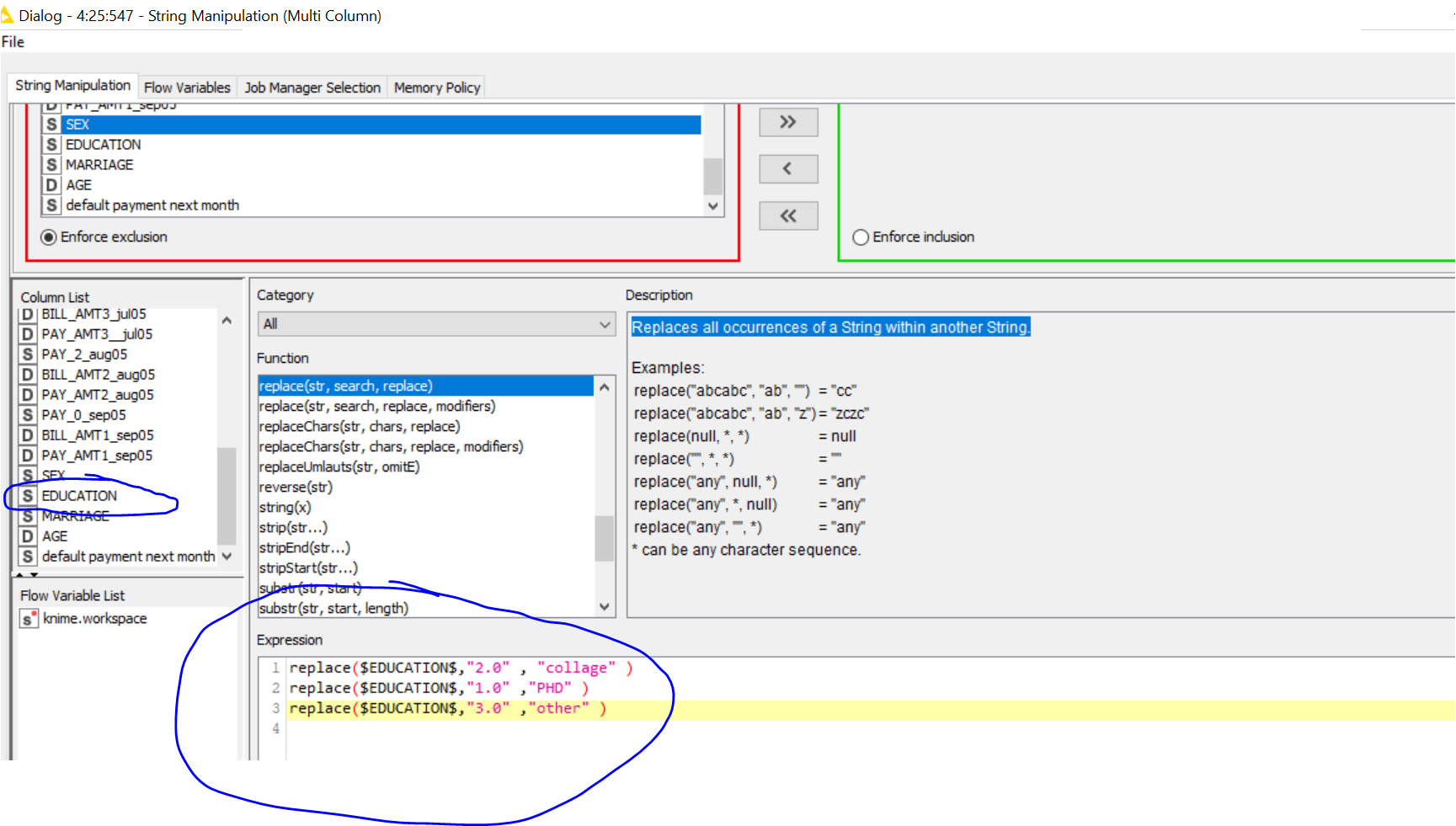
I tried to use you recommendation to use String Manipulation (multiple column). to change the following column “string”
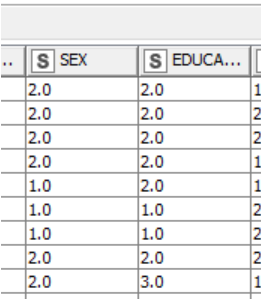
For example “sex” column , I want to change "2.0 "to Female and 1.0 to “Male”
Next column “Education” - “2.0” to “collage”, “1” to “PHD” . However I cannot do it in String Manipulation (multiple column). I would like to seek some advice from you . see the attached
But it dose not change .
Thank you very much.
Hi @SIngpaore_knime , what @ArjenEX and @HansS have given you are the proper solutions to your different questions (though @HansS meant the Rule Engine node ![]() ). However, I think you need to may be take a step back and understand what these nodes are doing, or rather how they work, instead of just using the given solution - I mean do use them yes, but try to also understand why these proposed solutions work.
). However, I think you need to may be take a step back and understand what these nodes are doing, or rather how they work, instead of just using the given solution - I mean do use them yes, but try to also understand why these proposed solutions work.
Basically, these nodes do manipulations on some input/incoming data, and return a result, and I think you understand how to do the manipulation and all, that is to get to the result. What happens after is that you then choose between saving this result in a new column, or saving it in an existing column, in which case it will overwrite the values in the existing column.
So you basically one input and one output, in general that is. Then came the “multi column” nodes, which allowed you to apply the same logic/manipulation, but on a predefined set of columns. Alternatively, you can still use the regular node that treats a singular column, but you will need to use a String Manipulation node for each of the columns you want to manipulate (one input one output). The respective “multi column” nodes simply avoids you having to repeat the same operations manually in several nodes.
The String Manipulation node is not meant to have decisions in it. It simply does manipulation. For your latest question, it looks like you are making decisions ( I want to change "2.0 "to Female and 1.0 to “Male”, Next column “Education” - “2.0” to “collage”, “1” to “PHD”), so you cannot do this in the String Manipulation node. Decisions are basically made from conditions, which are essentially rules - hence why you need to use the Rule Engine node.
IF <conditions> THEN <action>
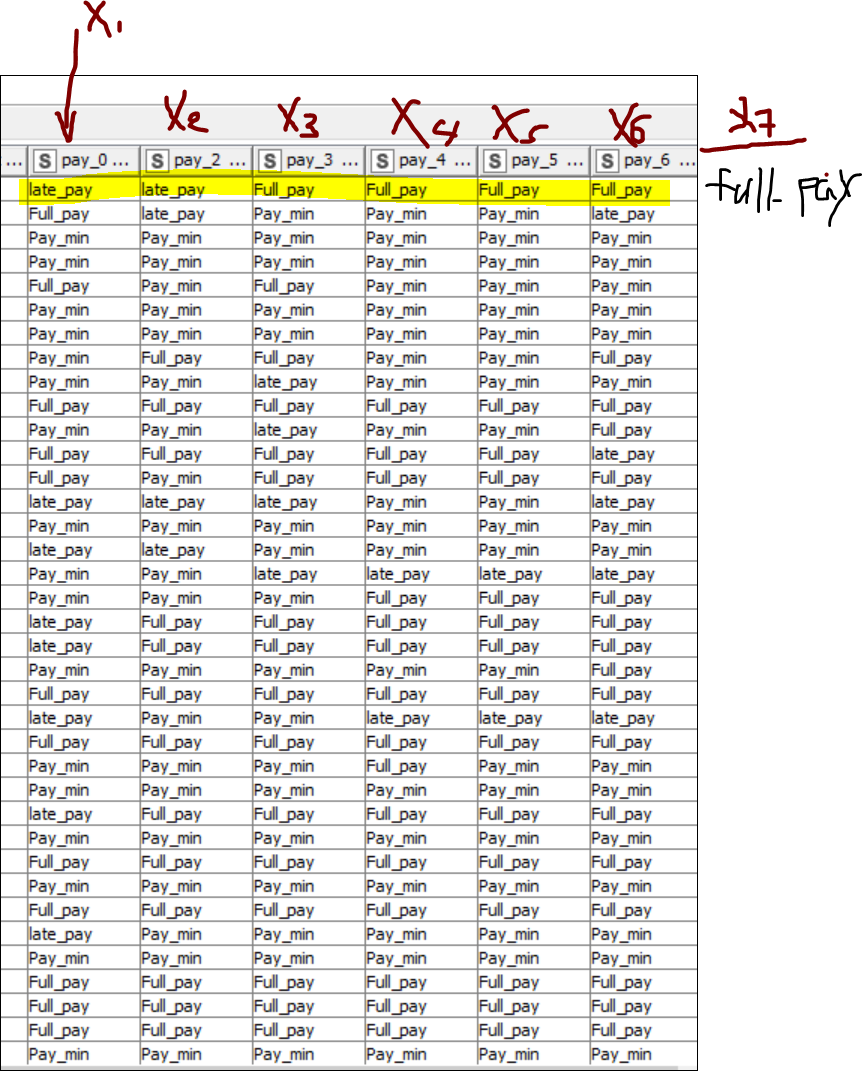
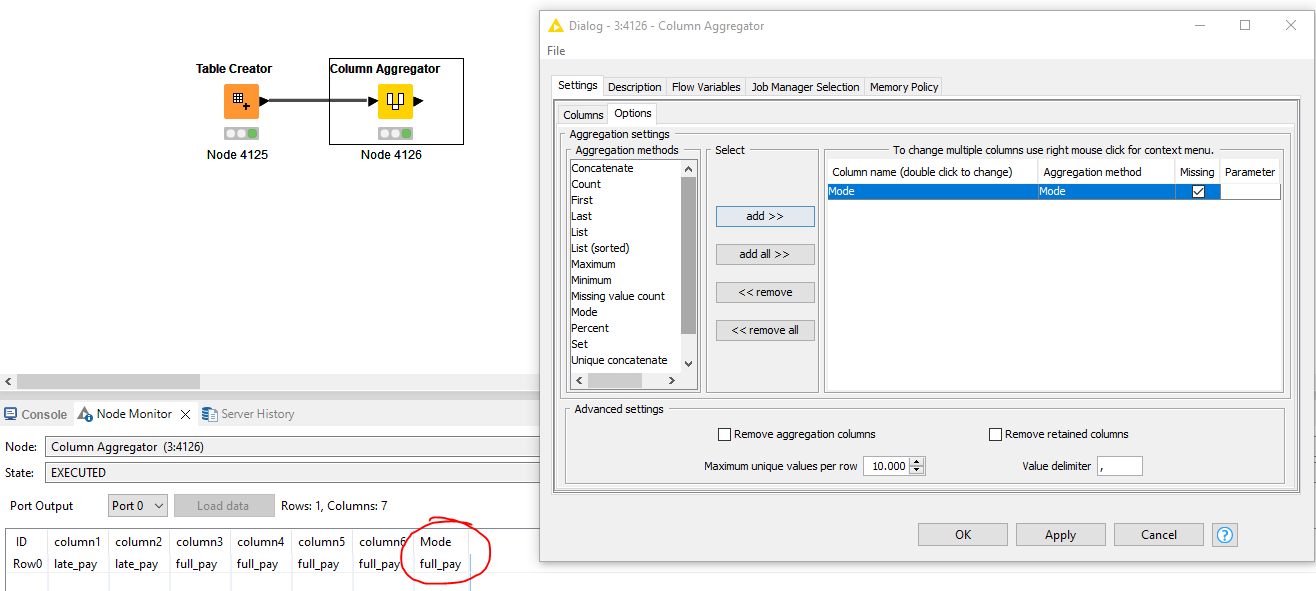
I want to count most frequent occurrence of string in X1 to X6 columns (eg. late_pay, Full_pay in each row ) then the result in X7 (column) . See attached .
I would like to ask any nods can do such functions, thanks
Tip for next time: since this query is unrelated to the first question it’s recommended to create a new topic.
Regarding your question, use a Column Aggregator and select Mode as aggregation method.
Hi Arjen Ex,
Thank you for your advice. Next time I will open an new subject for the query. Many Thanks
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.