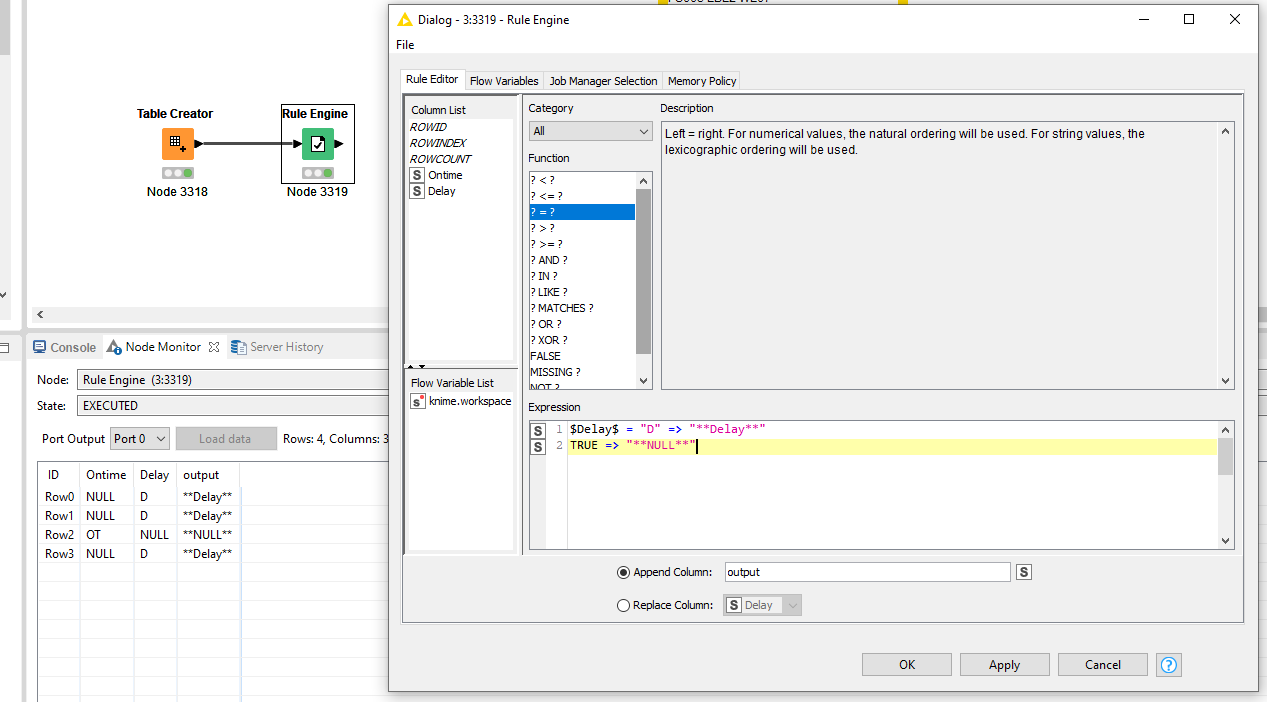
I am trying to create a new column which it combines the 2 columns (already existed in the xlsx data).
The first column is “ontime” which includes value NULL and OT. The second column is “delay” which contains value “NULL” and “D”. If a row has the value NULL from column ontime and D from column delay then the new column should show the value “delay”.
Ontime Delay **NEW COLUMN**
NULL D **Delay**
NULL D **Delay**
OT NULL **NULL**
NULL D **Delay**
Is it possible to exclude the two “old” Columns and only leave the new created column.
Since “Onetime” and “Delay” contain similar information. (When the order is ontime then its not delay)
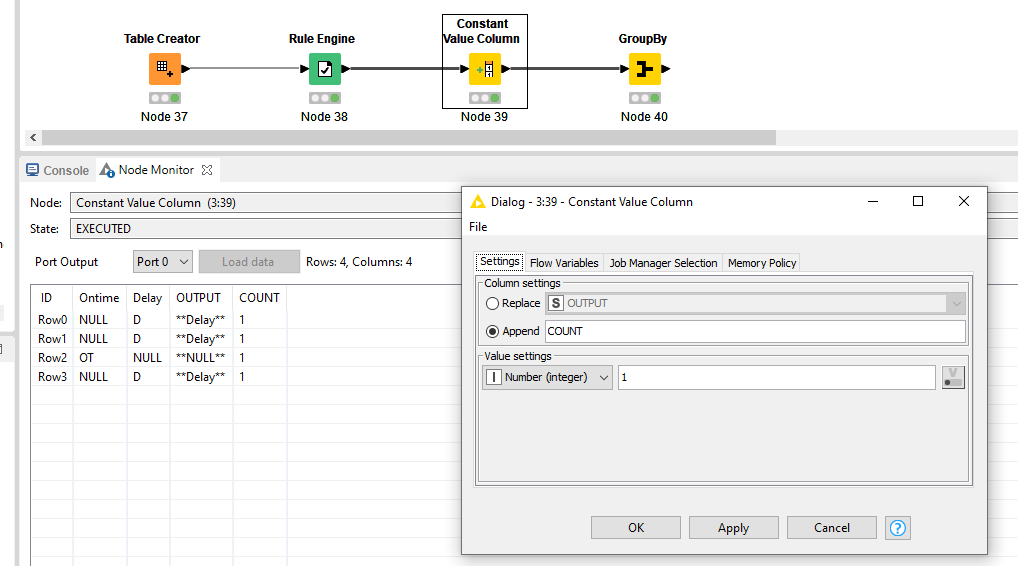
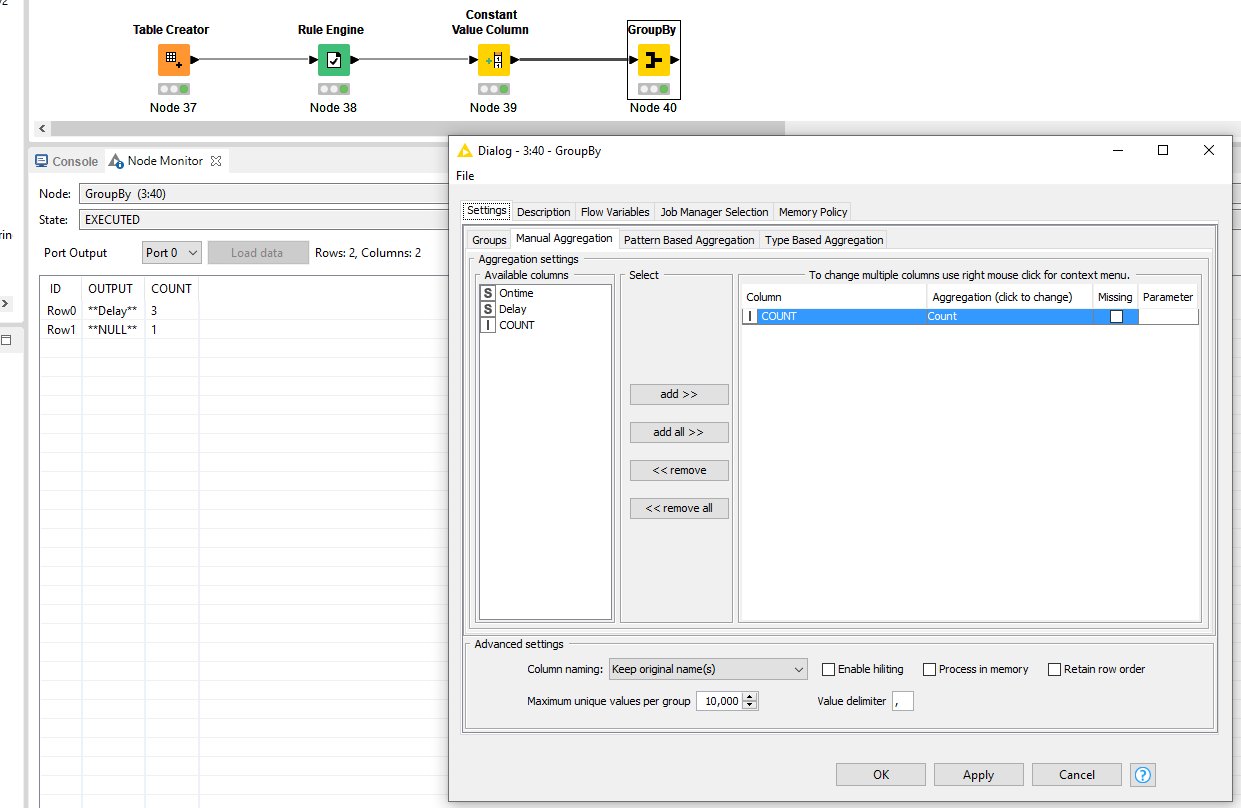
if I would like to count the rows which show only “Delay”, which Node should I use? I tried the Group By Node but I came out with the output with alle counts.