Hi all,
I’ve got a few questions regarding the “CSV to Spark” node.
I need to load a normal CSV file, but there’s no chance to see the list of files in the S3 directory I use (the S3 connector has been correctly activated).
I read in the description of the node that I can choose between file and directory, through the mode option. But I can’t see such an option in the configuration page (see picture below).
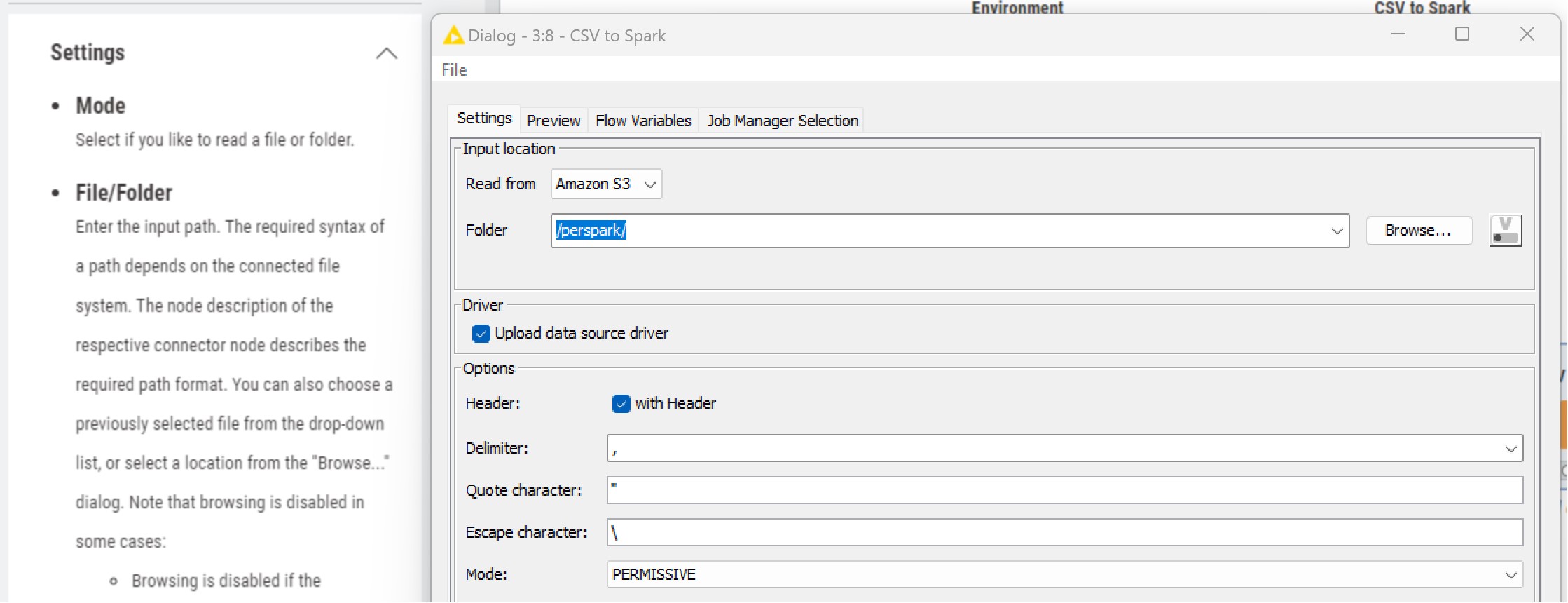
The only working option is to call a directory, but when I run the node I get two types of error.
- If I simply insert the directory in which I have the CSV file on S3, this is the message I receive:
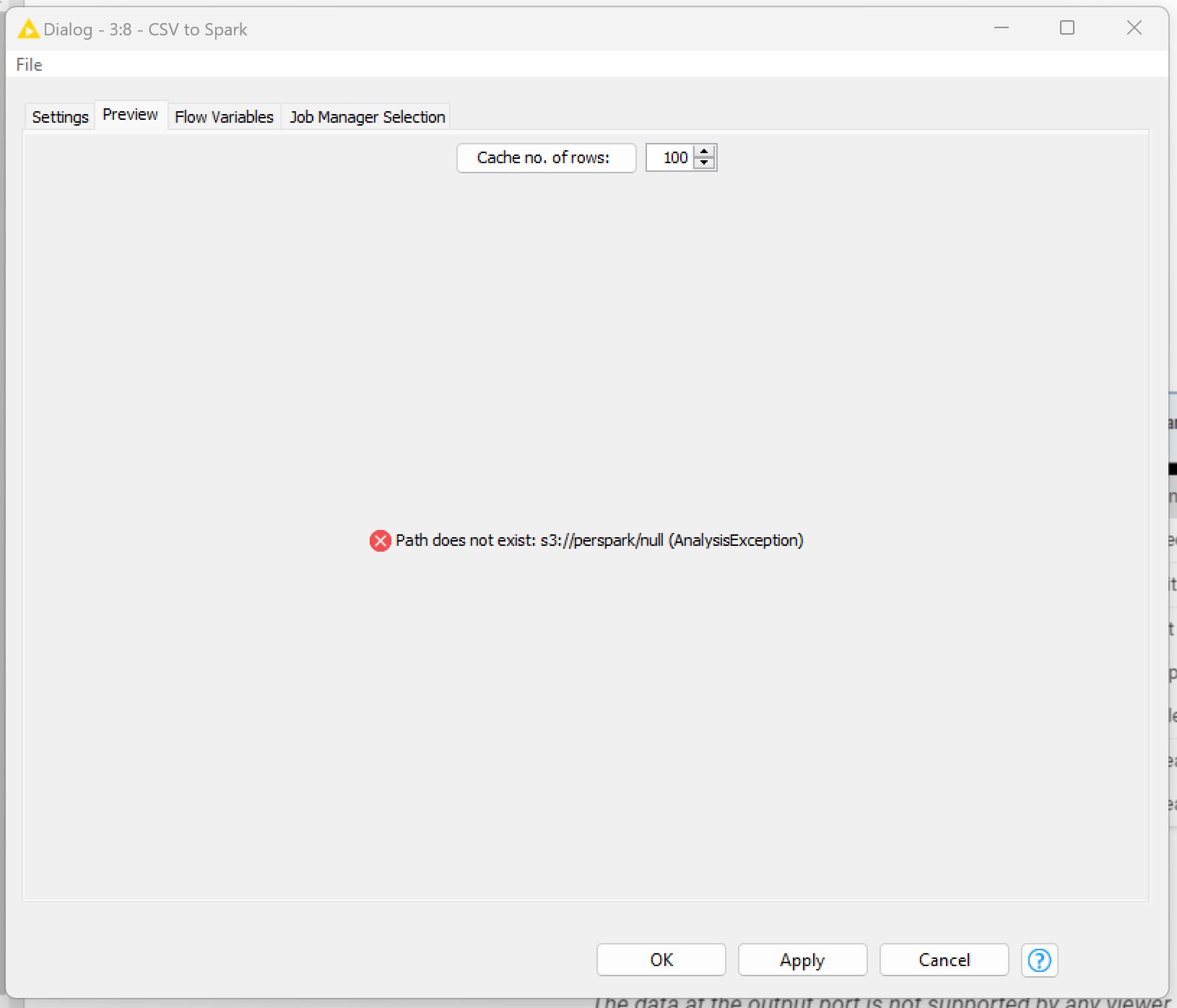
- If I enter the spark directory created in S3, this is the other error message:
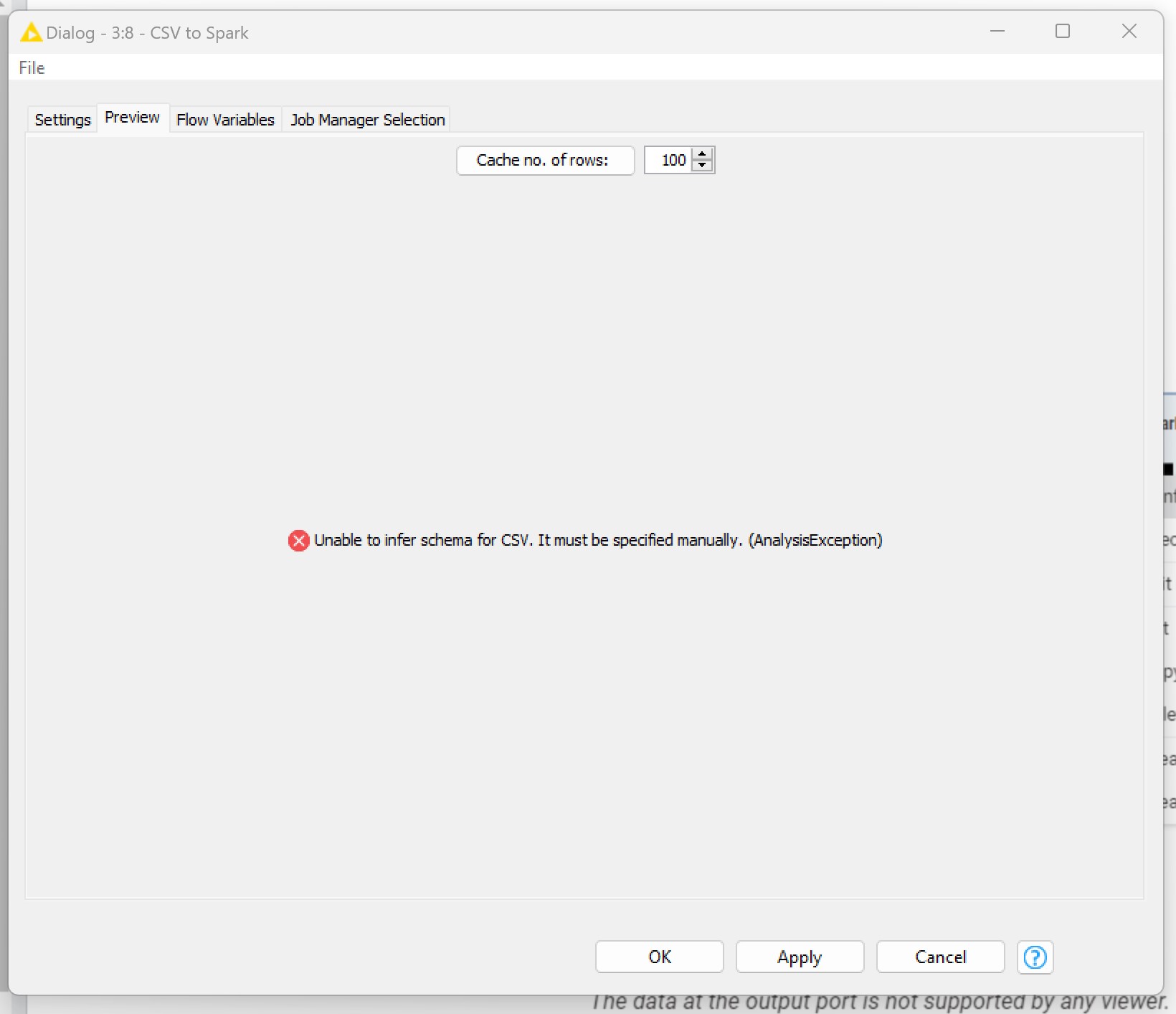
Using a common “CSV reader” node, the file is correctly loaded from S3, as you can see in the picture below:
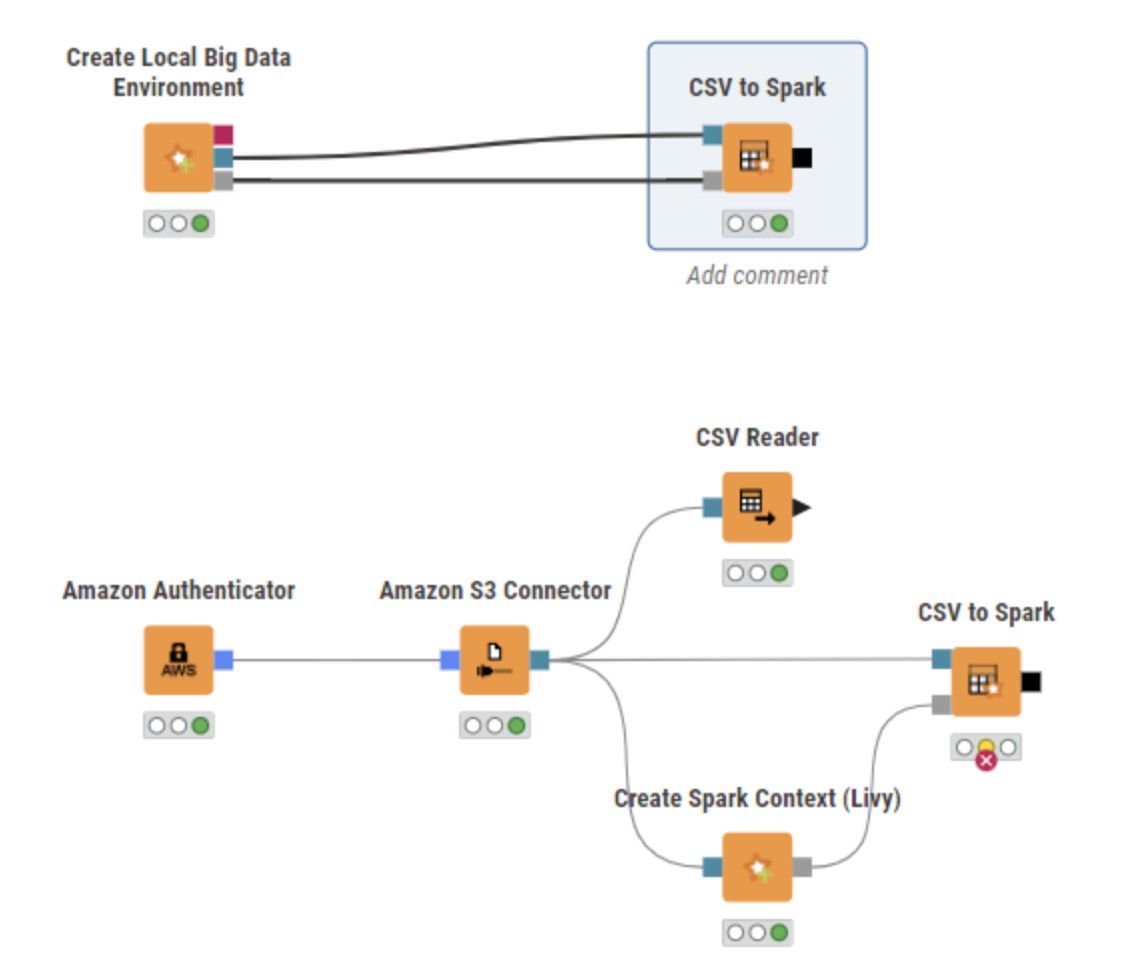
In the following (last) picture you can see the parameters of the “CSV to Spark” node:
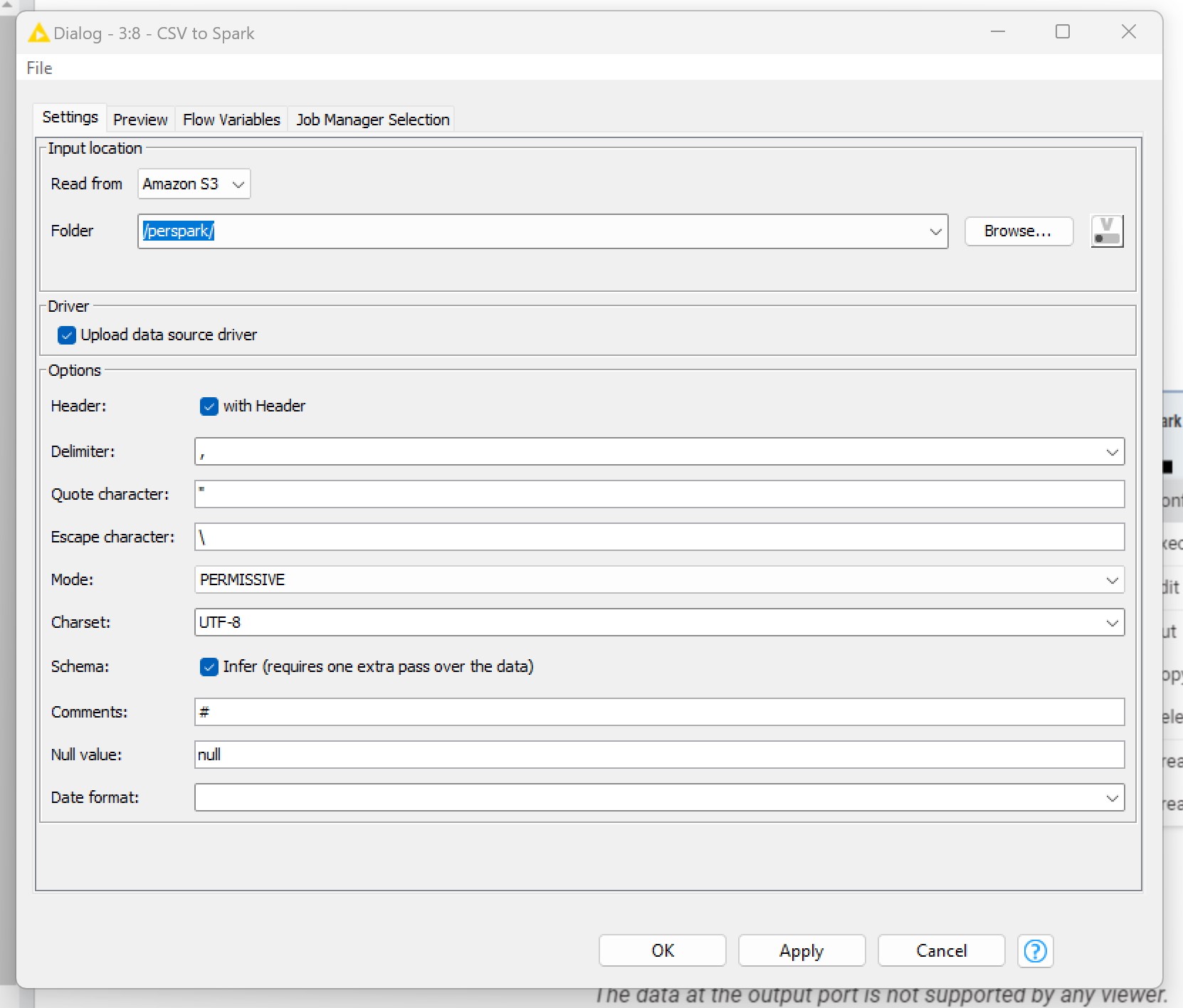
So where’s the problem? Why I can’t read a CSV file? Any clue?
Thanks for your patience,
Alberto