I have 254378 excel files
How to count the number of rows including column header using grouby node
How can I do it??
You want to determine the number of rows in 254378 separate files? Try using the Extract Table Dimensions node in a loop which reads in each file.
3 Likes
This seems like the easiest way to be able to just calculate it by the GroupBy node.
Hi @Ashok121, do you mean you want the row counts per file, including header?
I’m assuming this is a follow on from having read all of your excel files into KNIME. If so, yes you can then use group by for the total for each file, by grouping on the path (assuming you pulled in the excel path for each row), then choose any other column for the count. You’d need to add 1 to each value (e.g. math formula node) to include the column header.
In KNIME 5.1, you can use the Row Aggregator. Choose “path” as the “category column”, and “Occurrence count” as the aggregation. You still need to add 1 though.
@takbb Thank you for the Row Aggregator
but I have one more challenge.
there 214 files with data & 178 files with no data all has same column header.
Below is the sample format
is there a solution
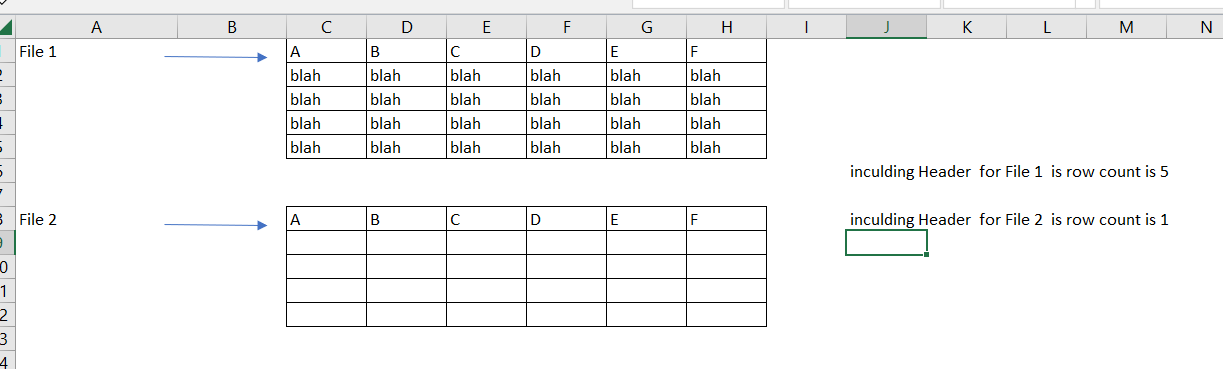
What about reading the files and uncheck “has header” option.
Then just count
br
yes i can do that but problem is again i need to run these excel file & Create Batches
it’s double task
i am trying to count number rows for each excel and creating batches.
is there any way apart from uncheck header.
Hi @Ashok121,
So the additional complication to your problem is that some files contain no data rows, and so won’t appear in the consolidated table, and thus cannot appear in the output of the Row Aggregator or GroupBy.
I’m assuming you are reading the files in a loop as per your other question at
You could adapt that, and count the rows as you go, so this will then also include the “empty” files.
The additional processing counts the files and generates a row for each xlsx consisting of path and row+header count. This is then output to the additional data port added to the Loop End node, so the lower output will be a table of row counts.
I have made modifications to the original workflow in the error handling branch, and added this additional processing (marked in red) and uploaded to the hub. Here is the updated version which includes row counts.

As this process was also dealing with moving “corrupted” files, these still get included in the counts but an additional column identifies if a failure occurred.
1 Like
I suppose you could also join back on a sting of the all of your file paths to see which ones were not present in the concatenated table, then assume a count of one for each of those missing file names. That only accounts for empty tables in the files though, not corrupted files that can’t be read…
1 Like
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.