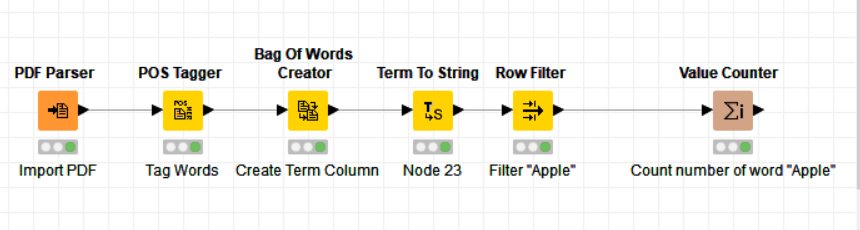
Hi, I am very new to KNIME and would like to use KNIME to count a specific word from several PDF files. For example, I have 3 PDFs named PDF1, PDF2, PDF3 and I would like to count how many word “apple” in these PDFs. Ultimately, I would like to see a result which show something like PDF1: 3 words, PDF2: 10 words, PDF3: 1 word. Would appreciate if anyone can help.
Currently I use PDF Parser then Bag of Words Creator then Term to String then Constant Value Column, then GroupBy, then Row Filter, and then Value Counter.
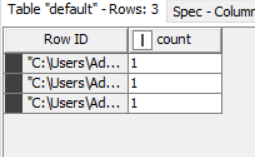
But it seems to be wrong since my result would show 1 word for each PDF. I am not sure which tool do I need to use to be able to extract and count each specific word.
@elsamuel
Please find attached. I cannot upoad PDF here but all I have in PDF is a word apple along with other words. In PDF 1, I have 3 words of apple and so on. The result I got is wrong as it only show 1 count for each PDF.
@armingrudd Thank you so much! That works really well!. Do you know how to count it without case-sensitive? Like I would like to count all “Apple”, “apple”, “APPLE”.
you can add modifiers to count() function. For ignoring case modifier is “i”. For more you can check description of function in node itself when you click on function