Hi @Safak , this isn’t that easy to answer for a couple of reasons. Firstly,I’ve had to just make up some data, and so maybe this will be nothing like the form that your data takes. Also from the example you’ve given, you would expect “pops out” to match with “pop” which means that it would maybe also match “population” with “pop” too, which probably isn’t what you’d want.
There may be some nodes that are better suited to this task for stripping phrases out but I’ve gone for “simple” at least as a starting point…
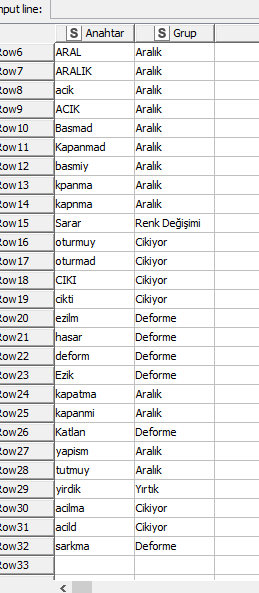
Here is my sample data:
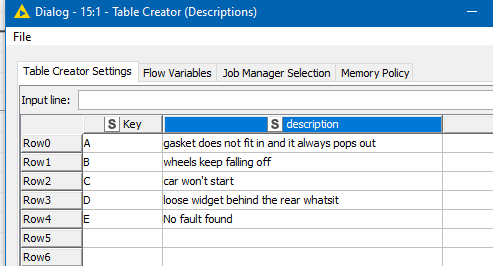
and here is a list of “phrases” and “categories”
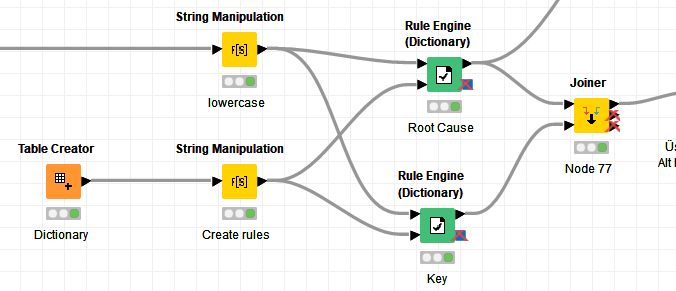
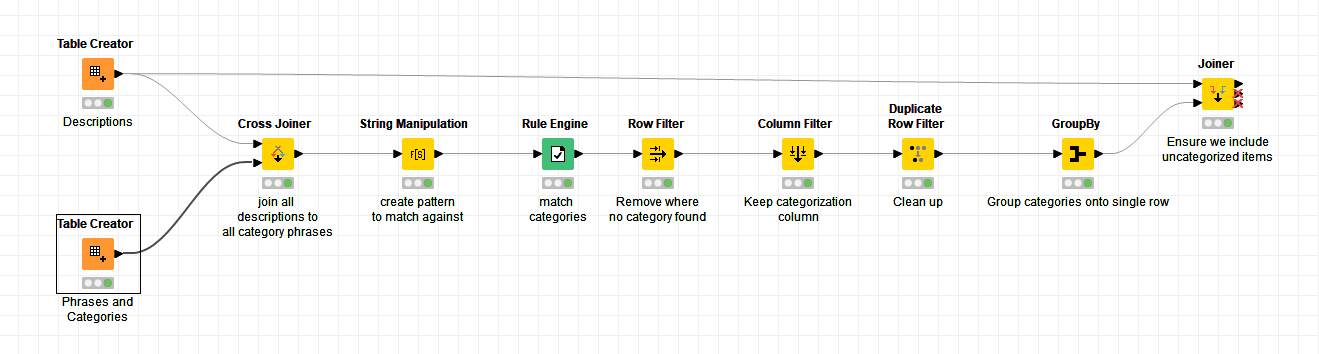
This is my workflow
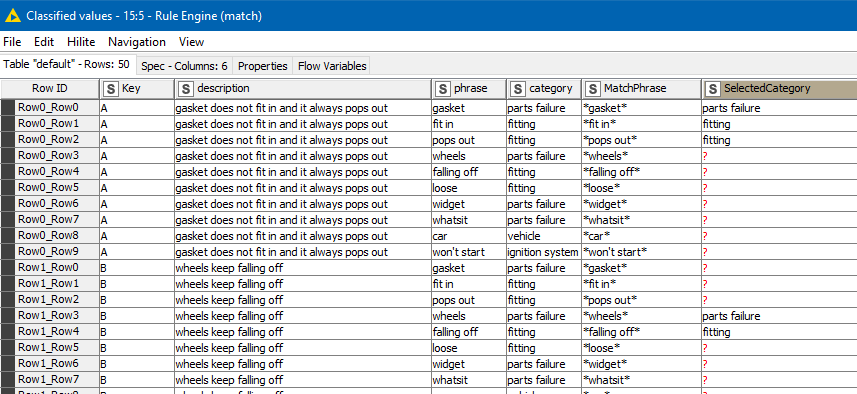
What it does is place every phrase/category row alongside every description row using a cross joiner. It then uses a Rule Engine to pattern match the existence of the phrase, inside the description, and if it is present, outputs the category:
Row filtering to remove where no SelectedCategory was returned, and then removing duplicates and finally grouping back into single rows, plus left-joining back onto the original table to retain anything for which no categories matched, we get this:
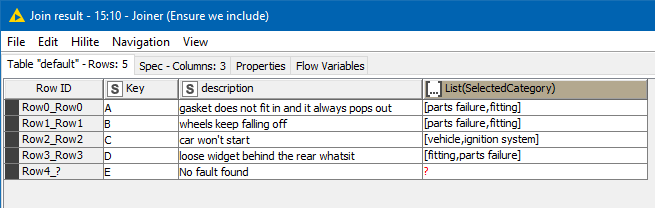
I don’t know if any of that can be worked into your own solution, but maybe it can give some ideas. There are plenty of holes in my approach, not least being that it doesn’t necessarily match entire phrases respecting word-boundaries, or word-stems, but perhaps its a start?
Keyword Categories.knwf (25.8 KB)
This could be adjusted to use regex instead of wildcards. Replace the text of the String Manipulation node to:
join(".*\\b",$phrase$,"\\b.*")
and then replace the text of the Rule Engine to:
$description$ MATCHES $MatchPhrase$ => $category$
and this would then ensure that phrases matched on word-boundaries, which possibly slightly improves its functionality.