My current workflow load various Excel files. Some columns are mainly numeric values, but the decimal separator might vary: “.” for several files and “,” on other files. The thousand separators can also vary.
For example, I can have 12,365,326.12643 on a file and 12.365.326,12643 on another file. The Excel cells can be formated as a number or as a string.
I would like to convert this column into double type.
Is there an easy way to do it?
Try configuring your Excel input as string, then use the string to number node with the separators configured correctly. It will convert both types of strings to double.
Do you know how to identify the decimal separator (or the thousand separator) automaticly?
Then I could use a variable for the string to number node.
I forget to mention, but this is not very important: these columns can also contains text, like “no sales”. The string to number node might delete these values, which is perfect.
I have the feeling that, if I defined “,” as decimal separator and “.” as thousand separator, or “.” as decimal separator and “,” as thousand separator in the string to number node, I will get the same result, and I don’t really need to distinguish them.
Is it true?
If true, then I don’t really need to define it with a variable
There are probably a dozen ways of addressing your issue. Attached is a simple approach using your number formats and a non-numeric string. The missing values from the string to number nodes are either set to 0, or the row is removed.
Sorry, that doesn’t help me as I load several files with a single Excel reader node.
I’ve attached an example that simulates the load of 2 fictional files, one using the comma as decimal separator and the second one using the point.
This workflow fails to recognize 123,3264 in the first case or 123.3264 in the second case (only one is properly recognize). String to Number_Example.knwf (13.6 KB)
I’m afraid you can’t upload all files with the same node if you want to detect separators, because formats get mixed up and it’s difficult, if not impossible at all, to get them on a single value basis.
I’ve made a workflow that tries to fix the problem.
My assumptions are
a) Only one pair of separators is used in each spreadsheet
b) All the columns of the spreadsheet that contain numbers are formatted in the same way: either all strings or all numeric
The files are examined one by one and a column is taken as an example to try to determine which pair of separators is used in the spreadsheet. These chars are passed as parameters to the “String to Number” node.
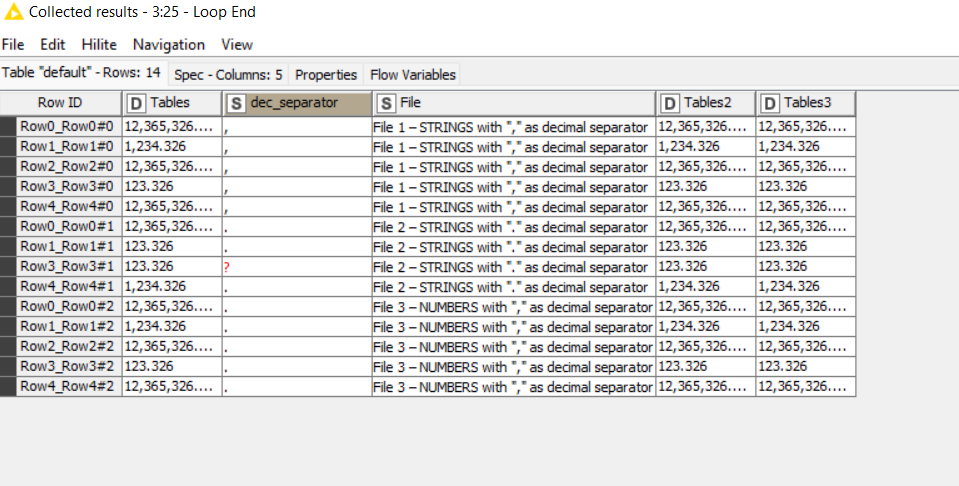
This is the result.
Input: three files with 5 rows and 4 columns each. The first two files have the same string columns and different separators, the third has numeric columns and a comma as a separator for decimals. I’ve found that when Knime reads the columns as string, it transforms automatically the original values, e.g. 12365326,12643 becomes 1.236532612643E7, but 1234,326 becomes 1234.326
Here’s the workflow. To try it you just have to change the first node String to Number_Example.knwf (35.2 KB)
If my assumptions are not correct, an inner loop must be introduced to work on each column of the spreadsheet.
If inside each single column there can be both numbers and strings, I can’t think of a solution
Please let me know if the wf is of any help