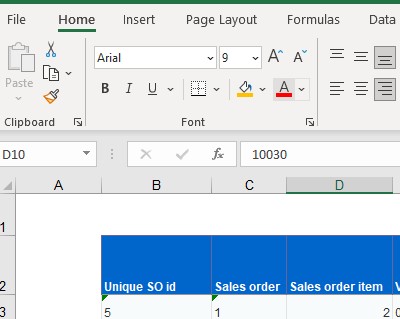
Does anyone know how I can dynamically read in files?
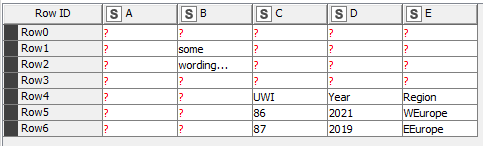
I have a number of excel files where the column headers and data start in different rows and columns (e.g. attached picture for your reference).
These files are sent to me on a daily basis. Unfortunately the position of the column headers and rows change every day… I now manually update the excel reader to fit the excel file.
Does anyone know how I can improve the excel reader so that it dynamically reads the first row and column with data?
The best solution for complex digests sourcing from Excel files is to code it in R. You can control format types, QC, EDA… by using the powerful ‘library(readxl)’
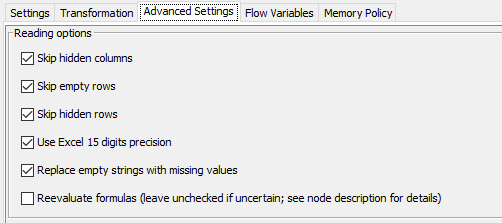
An approach in pure KNIME is by reading the file with the ‘Excel Reader’ node, by applying ‘Skip empty rows’ …
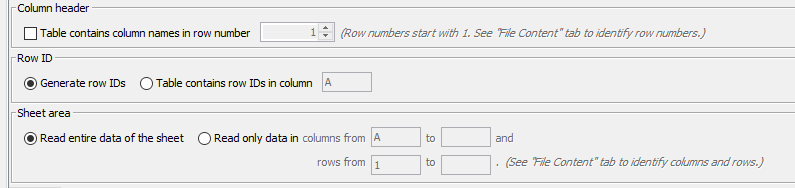
In the main settings, deselecting Column Header Option and selecting to Read entire data.
Here is where the problems start as the headers will force to read all the data in String format. Then depending on the complexity of the data this is something you will have to deal with afterwards. Your data will look something like this:
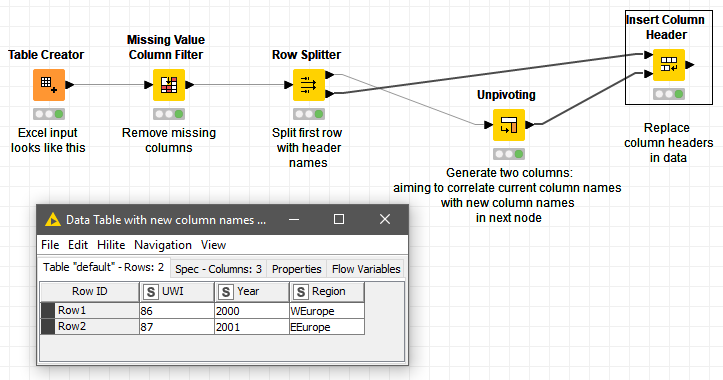
Then you can fix it easily with the following workflow…
Hi @gonhaddock
Thank you for your reply! However I in a number of excel files I have the headers start in col C row 5 but have some text in col b row 2.
If I try your solution, the splitter will use the text in col b row 2 as header instead of the actual headers that are in col c row 5. Would you know how it implement a work-around for this issue? The “random” text in col b row 2 is usually at most one cell.
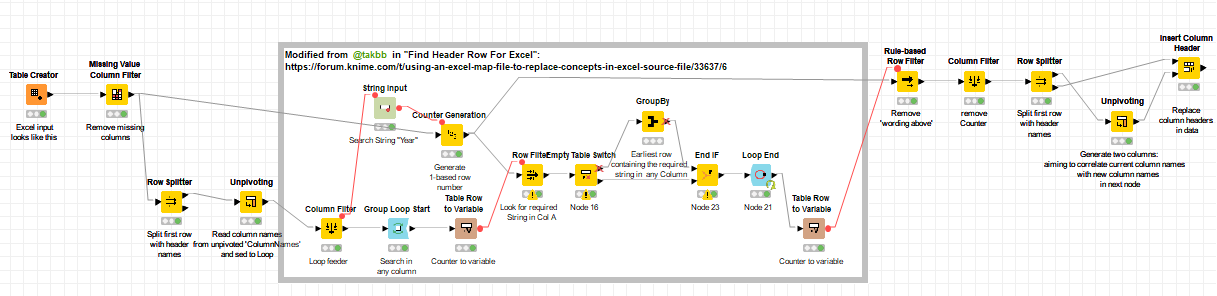
I have modified the workflow with his method of detecting were the data starts, fitting it into a loop, that search for a field name that can be fitted at any column order… to avoid the creativeness of our excel reporter friends.
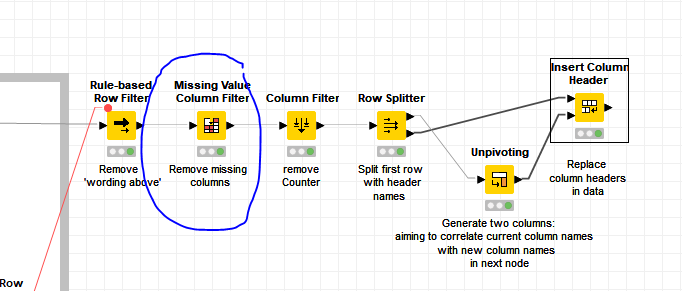
(missed the missing…)
The missing value column filter will need to be repeated or moved to the end in the case that “header wording” is placed in a column before the data starts.