I would like to extract a number from a text-column which contains many other numbers.
Example => Date: 01.01.2024 / 11:55:22 submitted by example company XY 123/456/789 80 1.111.111,50 81 222.222,22
Number to extract => 1.111.111,50 & 222.222,22
I always need the number following ‘80’ and ‘81’. But not all columns contains that numbers.
Does it work with the ‘column expression’ node?
Welcome to KNIME Community.
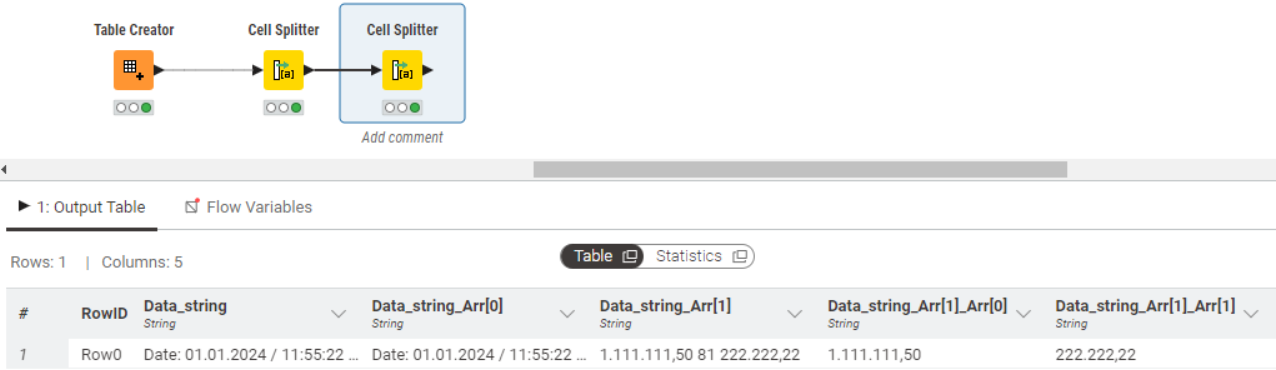
I’m not sure how your database and all expectations look like, thus I used ‘Date: 01.01.2024 / 11:55:22 submitted by example company XY 123/456/789 80 1.111.111,50 81 222.222,22’ string as the input data. Then, I have used Cell Spitter nodes twice with:
'80 ’ (please mind the space following 80) as delimiter referrring to input data column;
'81 ’ as delimiter referring to the very last column, created after cell split.
Thank you for helping me.
I’ve already tried the cell splitter, but sometimes the string is longer or shorter that the example or there are more numbers before the first ‘80’.
At the end the columns are filled differently.
In the above proposal, lenght of string and lenght of sub-strings are not important, so '80 ’ and '81 ’ delimiters splits the string. Spaces at the end of delimiters ensure that just ‘80’ and ‘81’ numbers won’t split cells.
Well, small improvement: you could use ’ 80 ’ and ’ 81 ’ with leading and following spaces to be more precise.
thank you for your help.
It works very well, but if there is more text after the numbers, it no longer extracts the numbers.
Example => Date: 01.01.2024 / 11:55:22 submitted by example company XY 123/456/789 80 1.111.111,50 81 222.222,22 xyz 12345 xyz
Does it also work in the case of a negative number? (Example 80 -12.345 → Result -12.345)
Hi,
You are right and it is weird, because according to regex101, a very helpful online tool for regex, it should work: regex101: build, test, and debug regex.
Let me investigate and come back to you when I have more info.
Kind regards,
Alexander
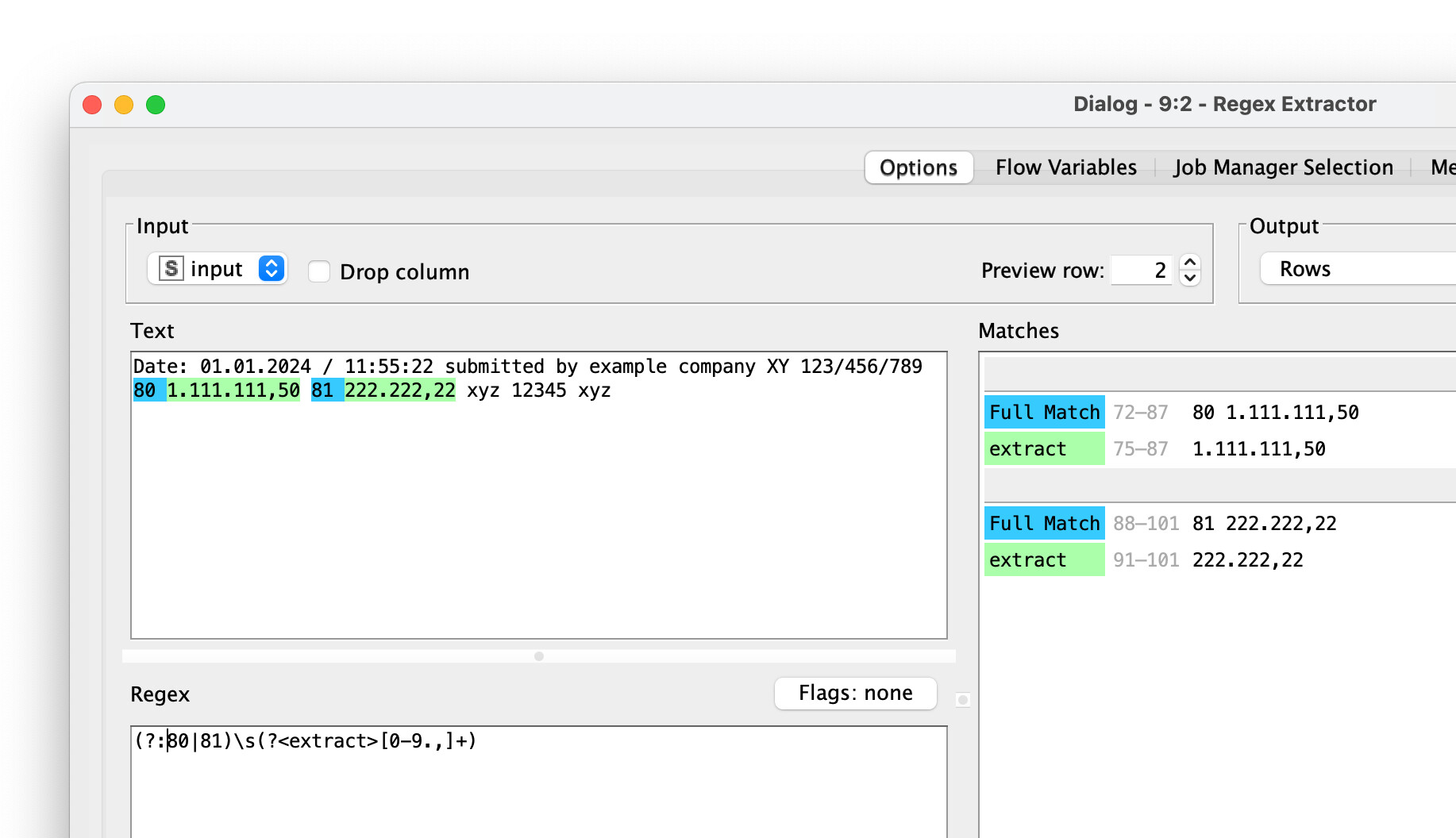
@awanninger This is a perfect case for the Regex Extractor which I built for the Palladian Nodes. You can edit and preview your regex right in KNIME with your actual data and immediately see the results - no tedious trial and error and back and forth:
Hi,
A colleague gave me a hint. You can use .*?(?:80 (-?\d+(?:\.\d+)*(?:,\d+)?))?+(?: ?81 (-?\d+(?:\.\d+)*(?:,\d+)?))?+ as the regex and that works.
Kind regards,
Alexander