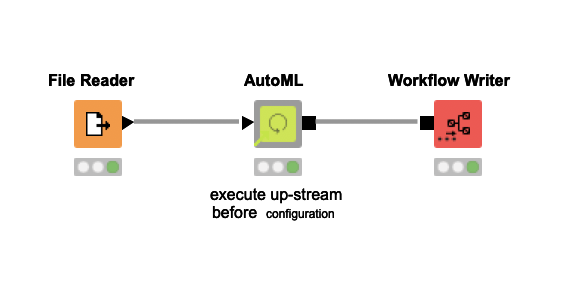
The AutoML component works a bit differently than Learner Nodes do in KNIME. It outputs a workflow instead of a model, hence the workflow executor being used to run it.
If you want to open up the workflow created by the AutoML component you can use the workflow writer node (right after the AutoML output) to save the workflow.
You’ll then be able to open it, check it out, edit it, etc. That’s were you’ll see the specific model being deployed as well as any pre or post processing used.
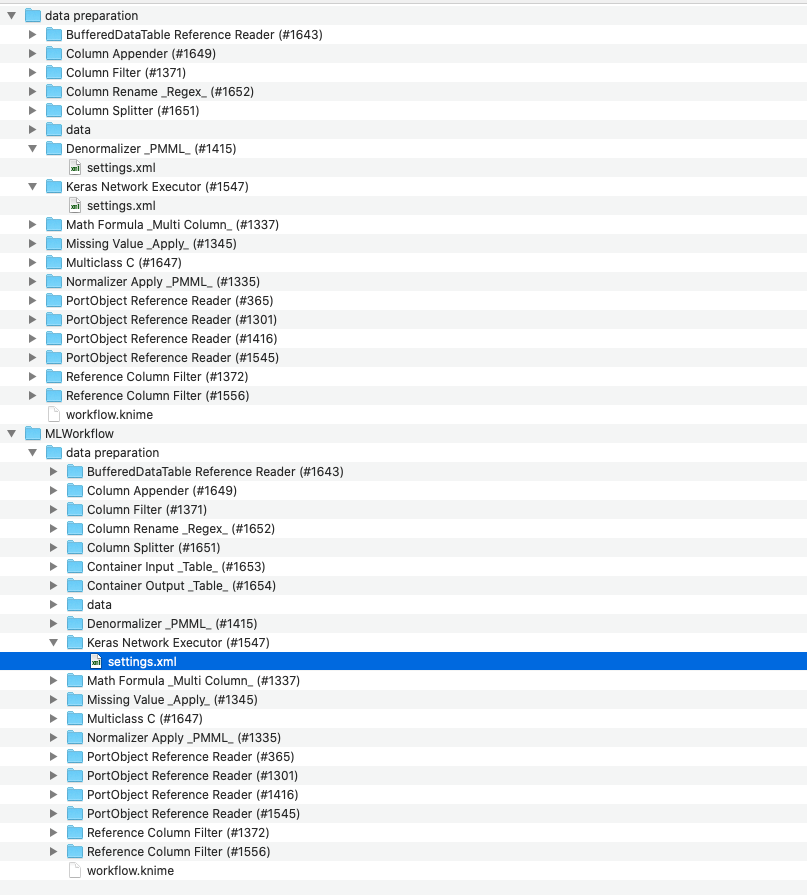
Thanks for the reply Corey! I did note the writer, but it’s not clear where the actual models are saved. For example, when selecting the Keras “Deep Learning” model in the interactive View and writing via the Workflow Writer, below are the file system files. I don’t see where th NN model is written. I see the NN executor, but not the built model, specific architecture, etc.
To truly validate and utilize as a screening tool, it would be helpful to get at the built models, or understand the NN structure and specific settings so that it can be rebuilt outside of the autoML/workflow component.
Hello @smuskal,
Going into your file system like that and trying to inspect the written deployment workflow (that is the output of the Workflow Writer) does not really work.
The only proper way for you to look at the final exported model (after using on the Component output a workflow writer and saving it your LOCAL workspace) is by opening it as you would with any workflow and optionally adding more nodes like Keras Network Writer directly in there to find out what’s needed.
Of course if you want to automate this you would need something less manual. You would like to automatically export from the Component hyperparameters found for the best model. Correct?
If that is the case we can consider adding an additional flow variable for you at the output of the Component with the optimized hyperparameters parameters found. In the case of Keras that would the number of units in the hidden layer and the number of epochs (if I recall correctly). We won’t output any hyperparameter which is fixed and not optimized. Would that solves it?
Please read the node description of the Component (also available in this hub page) to find out how each parameter is optimized.
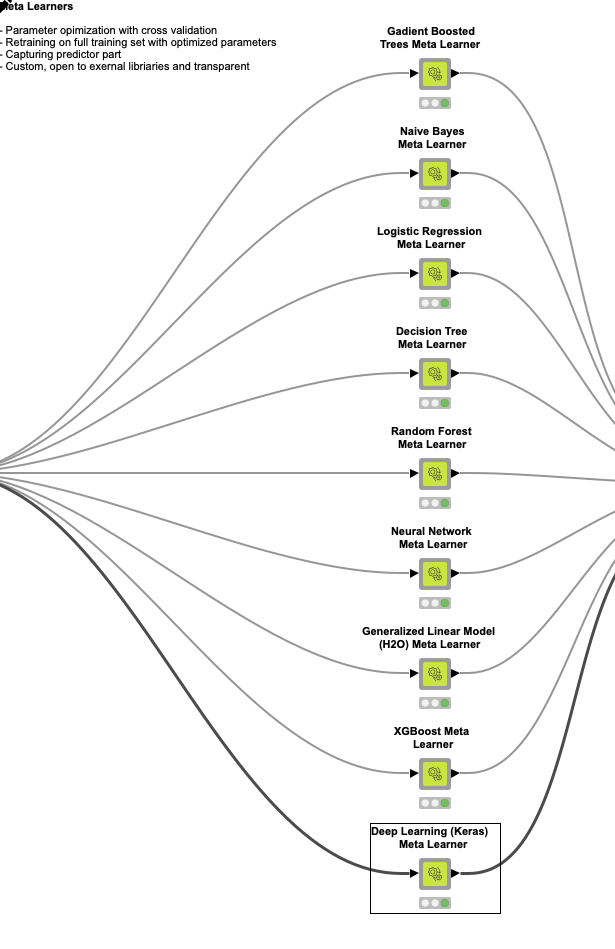
Please feel free to customize the parameter optimization strategy by simply changing the setting of one node: the Parameter Optimization Loop Start within AutoML Learner > any Meta Learner > Parameter Optimization (nested Components). Available customization in there: grid search, random search, Bayesian optimization, hill climbing approach, adding more parameters, changing step size and bounds. To customize the component you would need unlink it first (Right click > Component > Disconnect Link)
Regarding to any other weights (NN, Keras, GLM, LR, …) or splits of trees (RF, GBT, DT, …) optimized during the final training of the models (we are talking of the parameters which define the model itself) we cannot explicitly export those, sorry, it would be too much work to reverse engineer each model port of the different learners node and in most cases it would be too much metadata.
That’s great you found your way around (and inside) the AutoML Component.
We recently updated it to always export the best parameters found for the exported model.
Always make sure the parameter optimization strategy fits the time you want to wait and the computational resources you have before taking those best parameters found seriously into account though!
Hi @whois_rb,
we recognize the fact that our autoML component covers binary and multiclass classification and despite this already covers a good amount of use cases we should do more than that.
Theoretically we should make components also for:
Automated Regression
Automated Time Series Analysis
Automated Clustering
and it goes with probably more.
We’ll keep you updated if any new component comes out on knime.com/verified-components and we will also announce there if any community members is sharing something relevant on the KNIME Hub.
By the way have you checked out the new XAI View published 2 days ago?
Hi @smuskal,
the 100 rows limitations is to avoid people from getting stuck while providing a huge table for the bottom input. Beside the rather long waiting time necessary to explain more than 100 rows (SHAP can be computationally expensive) you also do not want to have too many data points cluttering the visualization.
In this other example (also shared previously we show how to use the confusion matrix to select only interesting data points (e.g. false positives) via a confusion matrix before the visualization (https://kni.me/w/JZbuUdhGKZBEpdoK).
Regarding the issue you are having. It should not happen and we do apologize. Can you please let us know which of the two examples you are running or it is some other model created with another dataset? did you use the AutoML component? It should work no matter what, but it would be then easier for us to fix the component and update it.
@smuskal my assumption is that you are explained a model you captured with integrated deployment which does not satisfy the black box requirements.
Those requirements are (also in the XAI View description here):
BLACK-BOX MODEL REQUIREMENTS
We recommend using the “AutoML” component to test the “XAI View”, but any model could be explained by the component as long as it behaves as a black box and it is captured with Integrated Deployment. Precise requirements are listed below.
The model should be captured with Integrated Deployment and have a single input and single output of type Data.
All features columns have to be provided at the input.
Any other additional columns that are not features can be provided at the input.
The output should store all the input data (features and non-features) and present attached the output predictions columns.
The output predictions should be one String type and “n” Double type, where “n” is the number of classes in the target column.
The String type prediction column should be named “Prediction([T])” where [T] is the name of your target class (e.g. “Prediction (Churn)”).
The Double type prediction columns should be named “P ([T]=[C1])”, “P ([T]=[C2])”, …, “P (T=[Cn])”, where [Cn] is the name of the class that probability is predicting (e.g. “P (Churn=not churned)” and ”P (Churn=churned)” in the binary case).
Additionally, if you are not using the AutoML component, you need to provide a flow variable called “target_column” of type String with the name of your ground truth / target column in the top input of the XAI View component.
If you edited in some way the AutoML component it might be that your model is not simply attaching predictions to the input table but it is instead removing any input column that is not a feature of the model or not the output of the model. In other words your model used by SHAP is scoring predictions but also removing the column “SHAP Order ID” necessary in the SHAP Loop.
thank you @paolotamag - these 3 would be a terrific start.
I think it would be great to create parity in the capabilities across both regression and classification. I agree that you have to start somewhere, and probably classification is the right one.
But as someone who has more regression needs (including time-series) than classification, I have been and will be super excited for more on that front.
Thanks for the reply. Yes, I am using the AutoML component with a subset of models to explore: I selected the Deep Learning in the interactive AutoML summary. I connected AutoML to your XAI Viewer, pulled the dataset sent into the top of XAI and a portion (i.e. 100 examples) into the bottom.
The data set are rows of doubles (about n=1000 features) and one string class I’m trying to model. I see your black box model requirements expect a specifically named output column. My string column name is called “Class.” Am I correct in saying it needs to be renamed to “Prediction (Class)?” I renamed (prior to going into AutoML), but still get this error: Execute failed: Can’t find the order column SHAP Order ID in the prediction table.
If you did not edit anything in the AutoML or XAI View components then you should not need to rename anything as we took care of all those black box requirement for you. Black box requirement are to be taken care of only if you are doing something custom when training and capturing the model with integrated deployment.
Please make sure you have the latest version of the automl component (while the workflow is opened go to knime toolbar and select “Node > Update Metanode Links”. KNIME will then check for you the latest components updates.)
For more documentation about Shared Components you can check here:
you did not edit anything in the automl or the xai component and neither in between them by adding nodes to the data ports.
it is not the deep learning model that you are exporting
Then maybe we might have a model that was not captured correctly by our team and is discarding the SHAP Order ID column when it should not. We are now testing through the other models you trained and will let you know.
While we do that please download this workflow:
Execute it and open the XAI view. Does it work? Please let us know.
I was trying to reproduce this bug by selecting different models in the AutoML dialogue and then using XAI view, but the XAI view worked in every case.
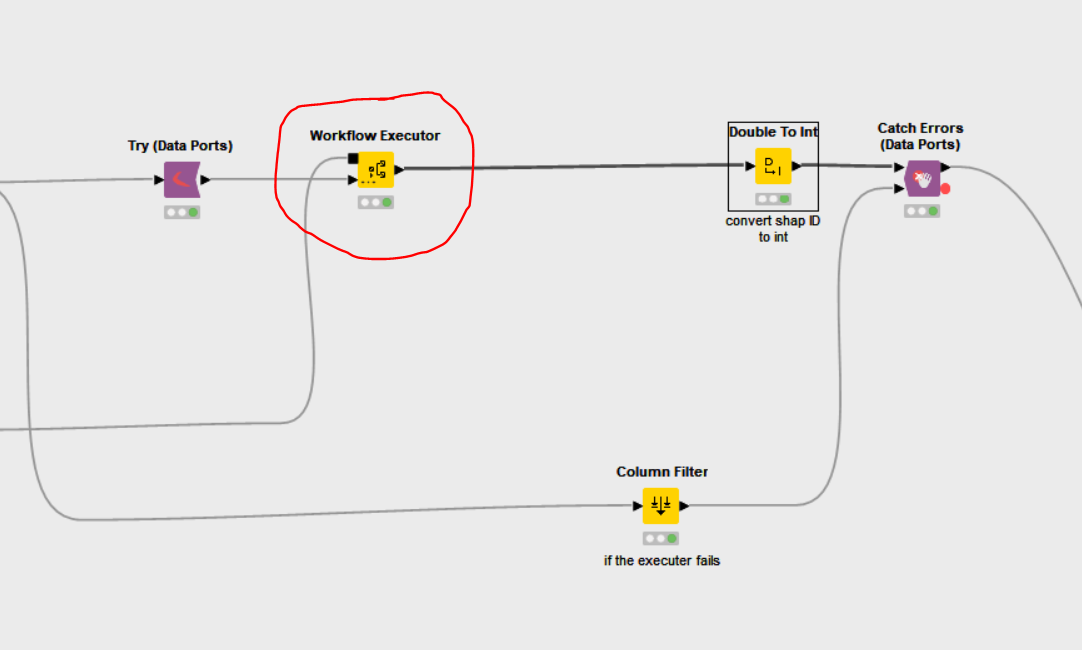
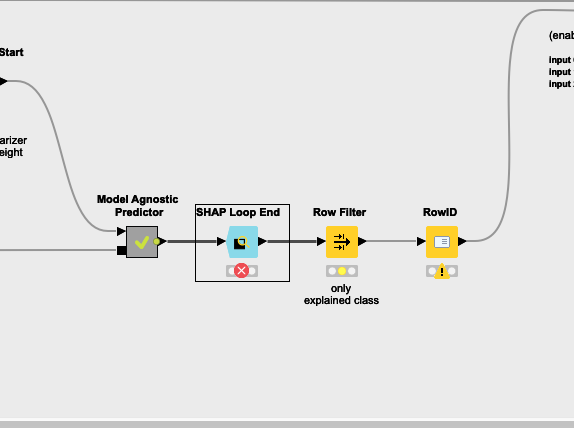
Looking at the error screenshot posted by you, I hypothesize that the issue could have been the failure of the “workflow executer” node in “Score Data” metanode in XAI view>Shap value/PDP> Model agnostic predicter(image attached)
Please check this and see if the issue is with the failure of the workflow executer and if it is the case, feel free to post the screenshot of the workflow executer error here, we can further debug it.
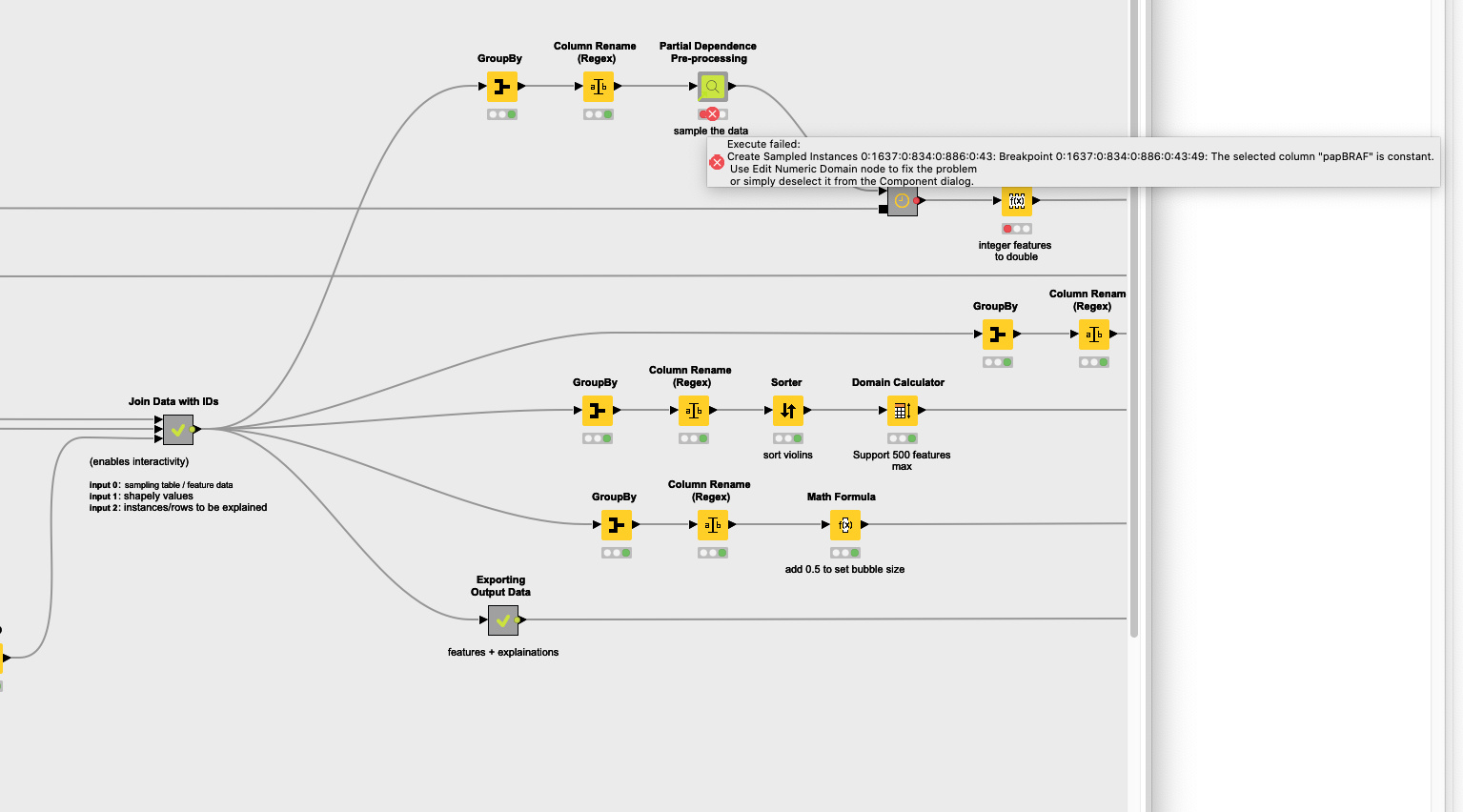
Thanks for digging further. I think the first issue was that I was using Deep learning, which seems not to be supported by the XAI view. Using Random forest, the error is here:
Thank you @smuskal for posting the error message. The issue here, is that your sampling table has features that have constant values across all rows. The XAI view has PDP component that create a coalition of features, but if a constant feature is supplied then the PDP won’t be able to create coalitions. I suggest you provide the sampling table with features that do not have constant values for all rows. Hope this helps!
I am not sure I follow - each row is an example and each column is a different feature. I don’t think I have features that are the same for all rows. I think I included the expected class (a string) in the set sent to the bottom port, so perhaps that is the issue?
We might fix the XAI view to do this automatically but right now this is the quickest workaround, sorry about this
Case (2) The AutoML was supplied with non-constant columns, but the sampling table(top input of XAI view) which was a sample of the input data supplied to AutoML, has a column with constant value across all rows (in your case I suppose the "papBRAF " column)
Solution: Make sure the sampling table(top input of XAI view) has all the features used by AutoML and this table has no constant columns.
We are fixing the XAI to do this automatically but right now this is the quickest workaround, sorry about that.
Hope this resolves the error, if this doesn’t help let us know, we will look into it and provide a solution asap.
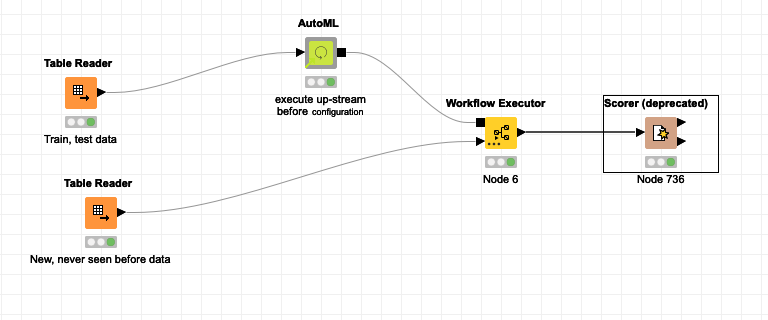
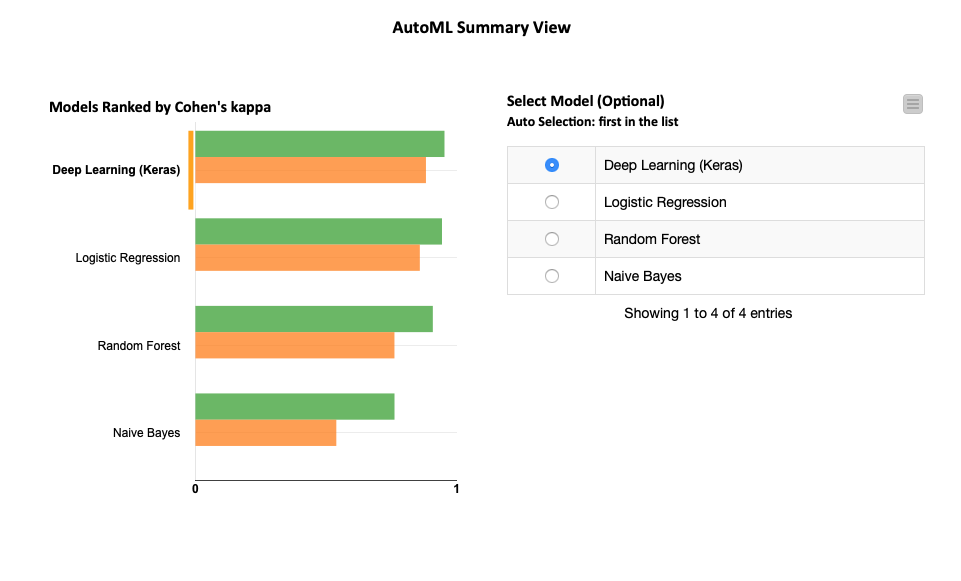
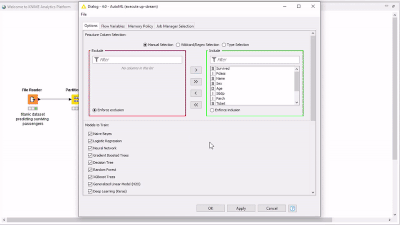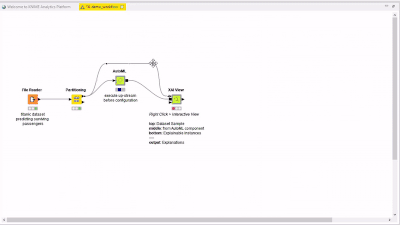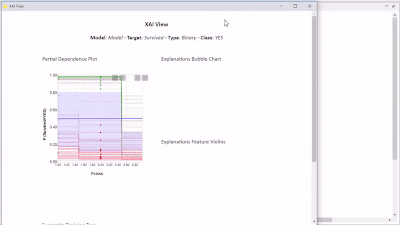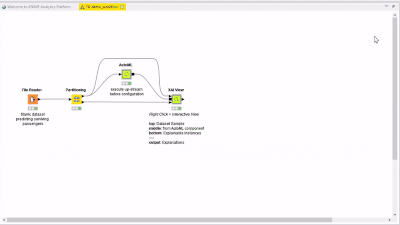
 I selected the Deep Learning in the interactive AutoML summary. I connected AutoML to your XAI Viewer, pulled the dataset sent into the top of XAI and a portion (i.e. 100 examples) into the bottom.
I selected the Deep Learning in the interactive AutoML summary. I connected AutoML to your XAI Viewer, pulled the dataset sent into the top of XAI and a portion (i.e. 100 examples) into the bottom.