Hi,
i have a requirement to extract the output of the data in PDF Format.
I have atleast 100 columns and 10000 records.
i have tried to many nodes report pdf writer or table to PDF or Data to Report (BIRT).
Table to PDF not getting data displayed in correct size of columns.
and report pdf writer is displaying only few columns rather than all the columns.
can i get some help here how to achive this ?
attached is sample data with 50+ columns and need this data in on PDF report where all the columns can fit here and display.
people.csv (770.0 KB)
Forget the PDFs for a moment. Is there some good reason why your data has so many duplicate entries? By eliminating the duplicates I was able to reduce the number of columns in your sample data from 54 to 9 without losing any information.
Hi ,
I have Just shared the dummy data because i can’t share even sample data which has some sensitive information.
but my original workflow have two output one have 50 column output and another have 100+ column output which need these output in pf format.
is this something possible to achieve ?
You didn’t answer my question. Does you real data have duplicate columns? If you provide dummy data which isn’t representative of your real data its difficult to do anything.
no, my original data doesn’t have duplicate column , let me get representative of my real data and give to you.
I’ll take a look, but I’m skeptical that we can do anything. The number of columns displayed in a pdf written by the Knime reporting nodes are limited by the page size. I don’t think there’s anyway to provide for horizontal scrolling.
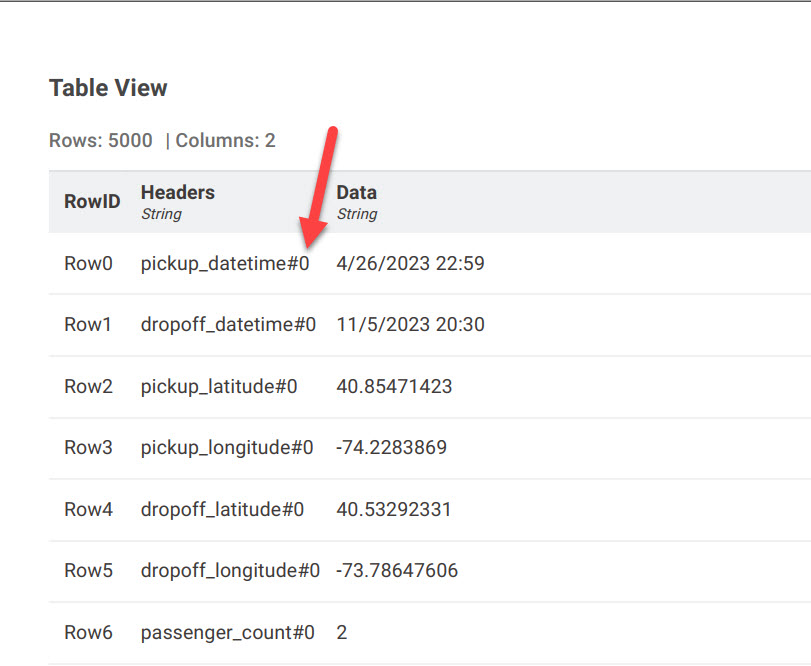
ok, i also came to this conclusion cannot render so many columns in PDF. but i am sorry can’t share any data original one or look alike , but NY taxi data i am attaching if we can replicate or render in PDF format.
nyc_taxi_data.csv (57.0 KB)
thank you for all your help .
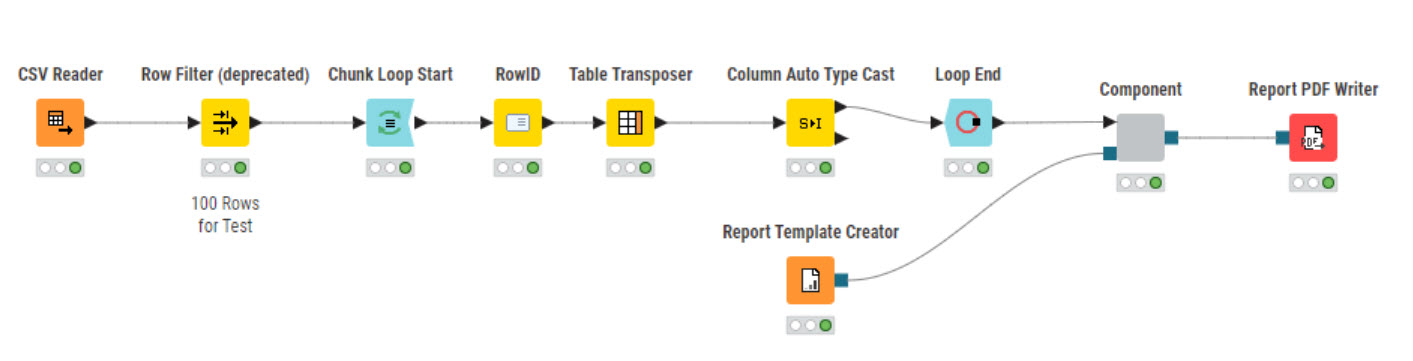
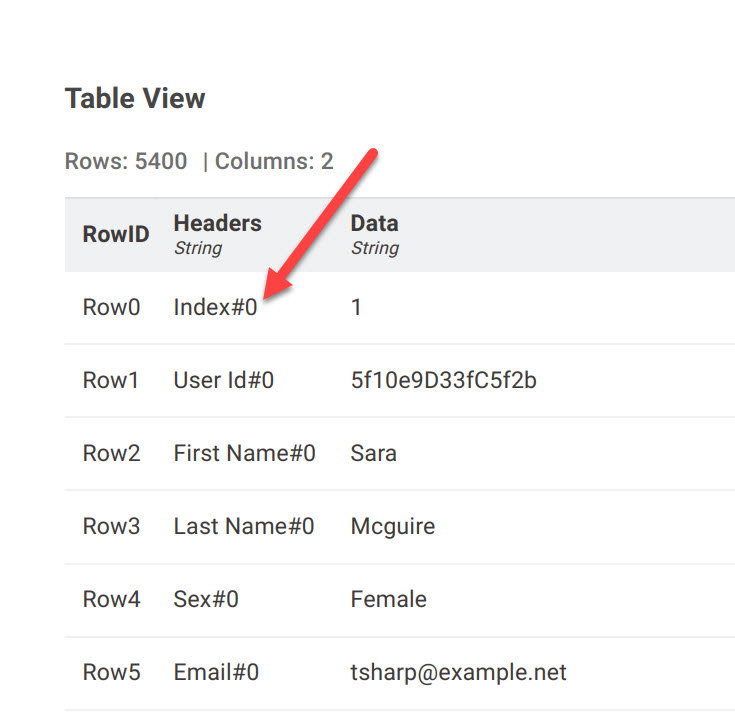
Here’s a workflow that will store tables with >50 columns in a single pdf. To get around the page size problem it stores the headers and data in single columns. If the headers are too long they need to be truncated which I’ve done for the taxi data. Each row is indexed as you can see in the screenshots below. You’ll have to judge how practical this approach is. The pdfs are in the data folder in the workflow.
2 Likes
I need multiple texts and tables in the output pdf. For this, i have used data to report BIRT node. So, i concatenated all the tables in one table into the BIRT and added text. Now, i need to add a page break after few records(Like page break where column=wwid) Can you please suggest me any solution for this.
Maybe someone else can help. I don’t use BIRT.