How to Filter data
let say I have rows 1 million row data,
each has 8 digits unique ID.
I want to filter 1000 rows based on the unique ID.(random)
Row Filter or Rule-based Row filter allows only filter data based on 1 condition, but here I have 1000 of condition
Row Filter or Rule-based Row filter allows only filter data based on 1 condition, but here I have 1000 of condition
You can add as many rules as you want to the Rule-Based Row Filter.
You can filter 1000 row random with the Row Sampling node.
gr. hans
1 Like
I have a list of sample, So its not an exact ramdom samples.
I don’t how a “list of sample” looks like (in KNIME), but maybe the Reference Row Filter is a way to explore.
gr. Hans
@elsamuel I will try this.
how can I filter data.
Eg.
My certain Unique ID ends with “RF”.
I want to filter out those IDs Which ends With “RF”
I will try this 
This is a sample of data. note ID does not have the same length, And I want to filter data based on the last 2 letters.
Ledger
YMPR752RF
YMPM844RF
YUPA1940RF
YMPR1303RF
YR1S492RF
YMPM213RF
YAPS502RF
YWBP200RF
YMPM397RF
YMPS859RF
YRJS460RF
YRJV376RF
YMPB356RF
YGJM594RF
YMPM404RF
YKAV368RF
YMPA438RF
YDLP234RF
YGJG145RF
YMHN1054RF
YMPN548RF
YDLK157RF
YAPP248RF
YUPR900RF
YR1S585RF
YMPV267RF
YMPH150RF
YHAM261RF
Hi @ganeshpawar,
you can use the row filter node and set Matching criteria “use pattern matching” to “*RF” (without quotation marks!). Furthermore you have to enable “contains wild cards”
BR
2 Likes
Thanks, @morpheus It worked for “RF” but what if I have a 100 ID that does not have any common parameter for filtering.
how can I filter data in that scenario?
I have used Reference Row Filter but can you suggest another way.
Hi @ganeshpawar , when applying rules, we try to recognize as much common patterns as possible, and that does not always cover all cases. You need to then recognize other common patterns and create other sets of rules or exceptions.
If you will need multiple rules, you can use the Rule-based Row Filter instead. It’s basically a mix of the Rule Engine and the Row Filter nodes, where you can add multiple rules like you can in the Rule Engine, and it will filter (filter in (include) or out (exclude)) rows like the Row Filter, but based on the rules that are set.
For example, I have this input:
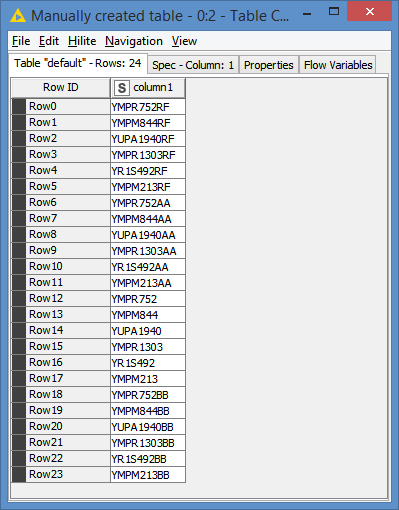
They’re basically the same 6 records where I changed the RF to AA, to and to BB.
The rules that I am applying are as follows:
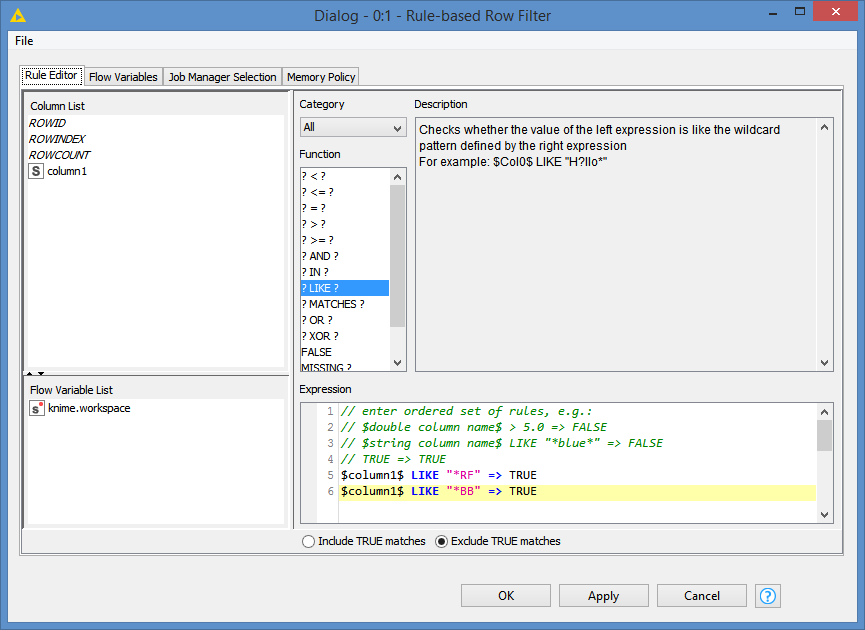
So, I’m basically define what I want to exclude, in this case I want to exclude anything that ends with “RF” or with “BB”.
Results:
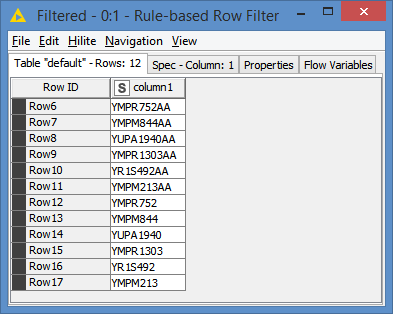
You can also use regular expression with the operation MATCHES in the Rule-based Row Filter that can cover multiple cases in one operation.
If you are struggling to translate the rules that you want into the node, you can just tell us the rules that you want to implement and we can help translate them into Knime.
Here’s the demo workflow:
Filter data via Ruled-based Row Filter.knwf (6.8 KB)
2 Likes
You could also try out Rule Engine Dictionary, but this gets sometimes quite confusing for me especially with wildcards and a lot of escape backslashes so Rule Based Row filter might be easier.
br
3 Likes
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.