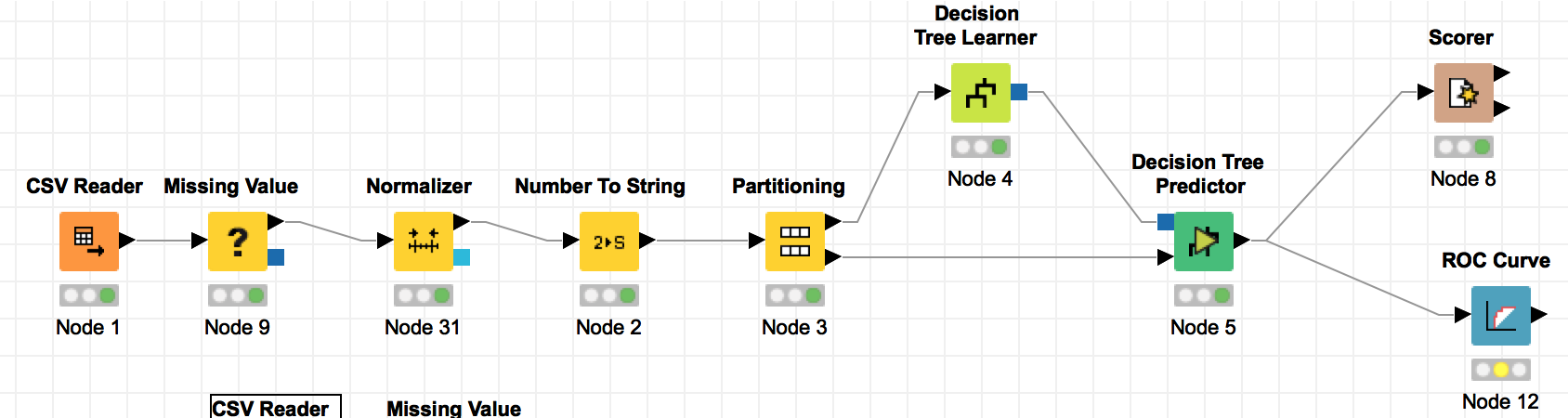
I have a training set and a test set. The training set has the the target attribute whereas the test set doesn’t have the target attribute. I need to build a decision classifier using the training set, then use that classifier to predict and get the missing target attribute in the test set.
How would I go about getting that missing target attribute in the test data using the learner and predictor nodes for any of the classifiers?
What preprocessing techniques would you recommend for each classifier
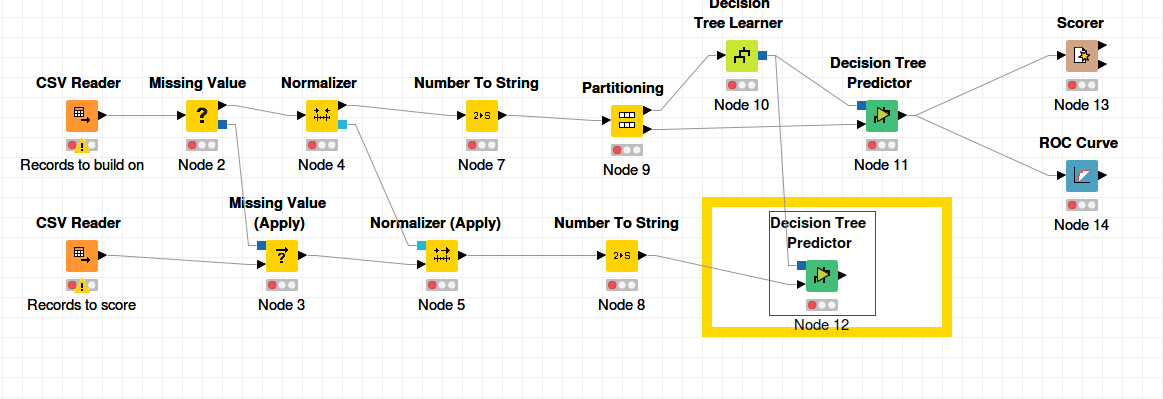
When you make a predictive model in general you have a dataset to build your model on. And you have a dataset to apply your model on and make your predictions.
Your target variable is only in your model-build-dataset. You split the records in this dataset in train-test(-validation) sets. When you are ok with your model (parameters, confusion-matrix e.d.) you apply your model on your dataset with the records you want to predict.
When you start with a robust technique like random forest, you don’t have to worry so much (generaly speaking) on de data-types of your input variables. But always be carefull for missing values and outliers (and their meaning) in your datasets.
Take a look at the KNIME example server with lots of examples how to build models.
Thankyou so much for your help! Real MVP!! I’ve already made my classifier, Im just completely lost on how you would actually apply the model to the data set to get that predicted value to show up? Like what to connect? do I have to append anything?
You can expand your worklow as follows. I add a new “line of nodes” where your records to be scored are pre-processed, and the scored in the DT-predictor. But always be carefull with the choices you make.