I have a dataset in which daily receipts are recorded in the following fashion
Date / Customer ID / Receipt Number / Sale Amount
I want to find out which date had the maximum sales and which date had the minimum sale amount regardless of the customer.
My current flow is to use “Group By” to use Date as group column and sum(Sale Amount) in Aggregation. I have then used 2 Math Formula Nodes with the following conditions,
COL_MAX($Sum(Total_Sales)$) == $Sum(Total_Sales)$
and the other one is
COL_MIN($Sum(Total_Sales)$) == $Sum(Total_Sales)$
I have then used a Joiner class to merge the results.
Hey @msusmani Thanks for posting about this topic.
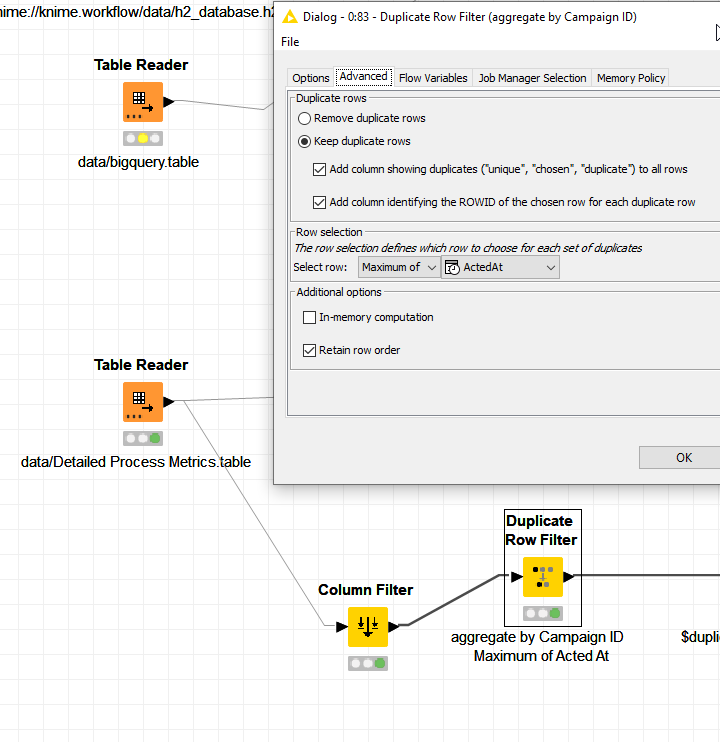
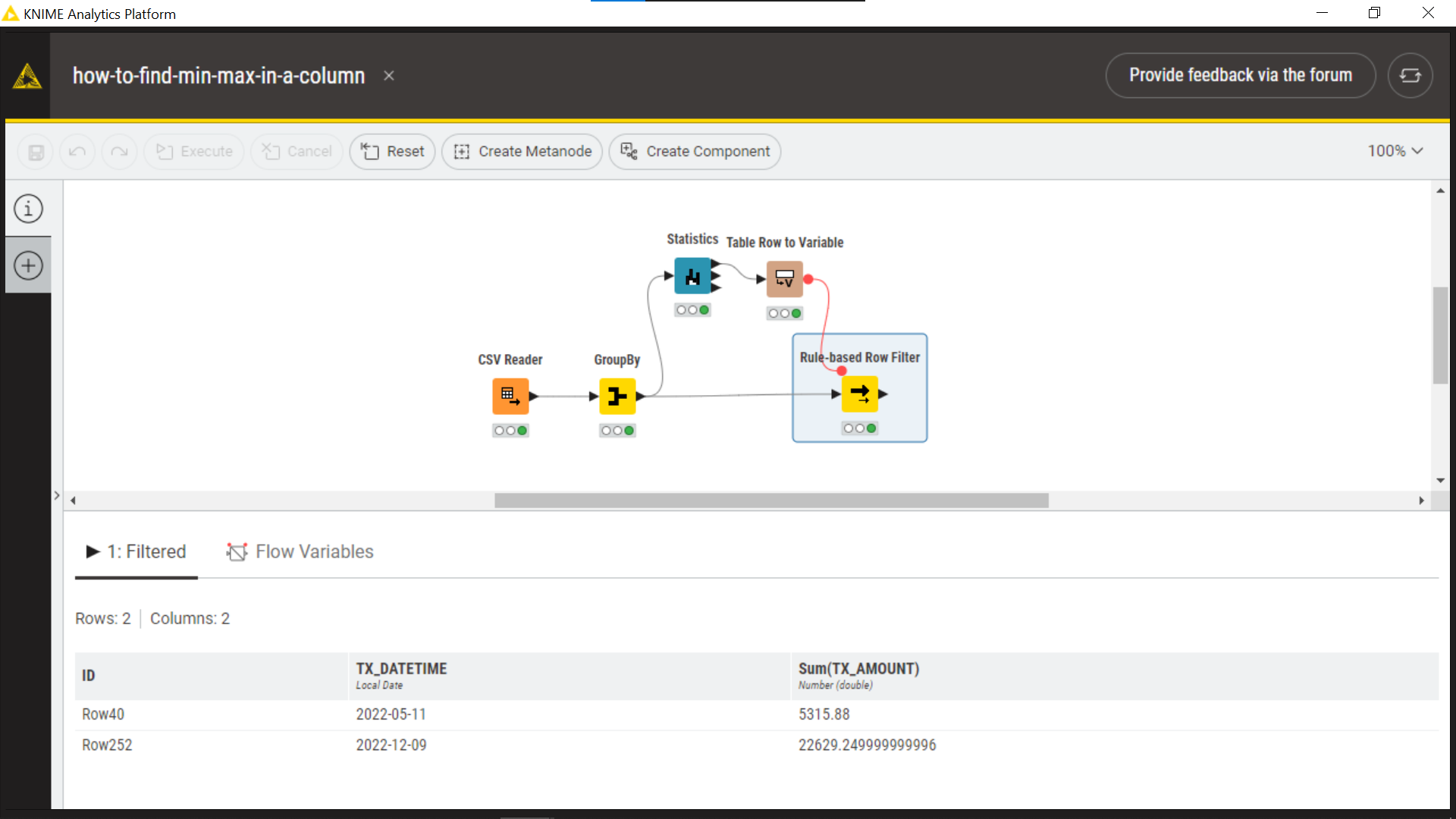
If I understood correctly your goal, it could be accomplished using a Statistics node, that returns some statistics for your “Sale Amount” column, as the Min and Max.
Then you can convert these values in flow variables and use them in a Rule-based Row filter, see screenshot below