I have 2 collection columns both containing a list of words.
I want to find a list of words which exist in both of these 2 lists.
Example1:
column A: [good, bad, very, apple]
column B: [banana, ball, bad, chair, apple]
The column I want: [bad, apple]
Example2:
column A: [good, bad, very, apple]
column B: [banana, ball, chair]
The column I want: [ ] or missing value (?)
Node 1 is your input data-set with the two columns, Node 2 is a simple join where you select Column A and Column B as the respective joining columns.
For Example1: this will list the value that exist in both data-sets in the first column of the Joiner output.
For Example2: this will create an empty table since there are no matching values.
Sorry Medzi, I think I have expressed my question weakly. Let me try again:
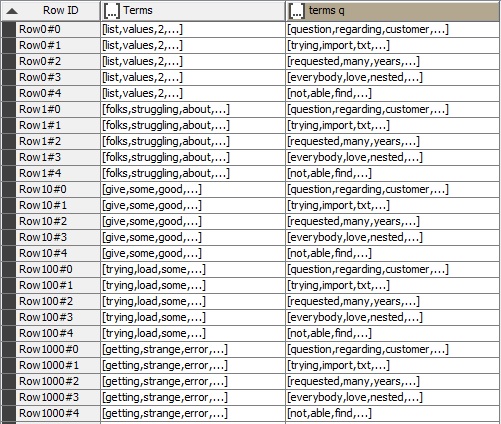
I have a table including 2 columns that their type is collection.
That means in each row of the table I have two lists of words and I want to find the intersection of these two lists in each row.
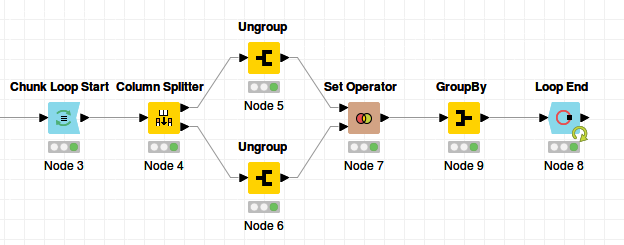
I have tried using Set Operator and Subset Matcher nodes but I couldn’t get my desired result.
Here is an image of the table:
PS: I also tried to ungroup and match the terms one by one. But unfortunately the size of the table exceeds my system resources when the Ungroup node is at 4% of the progress.