So, I want to force the "Excel Reader (XLS)" node to read "Column B" as Double... always.
I don't want the node to consider that column as String, and then I have to do the "String to Number" conversion.
The reason I don't want to do the conversion, I because I loose the decimals in the cell. For example, let's say B2 shows 12.88 because of the cell formating, but the actual value of the cell is 12.8799999. Using "String to Number", I loose the decimals.
There is a reason it is being considered a string instead of double. If Knime can't interpret the number field always as a double, it will conisder it a string. I have noticed commas cause a number to become a string.
One option is to remove the conflicts before loading the file into knime.
Another option is to filter columns twice, first by type (string), then by the column names that you expect to be doubles (as a flow variable), and remove commas or whatever is causing it to be a string, add a "Column auto type cast" node so they are converted to doube, and then reattach the columns to the original dataset.
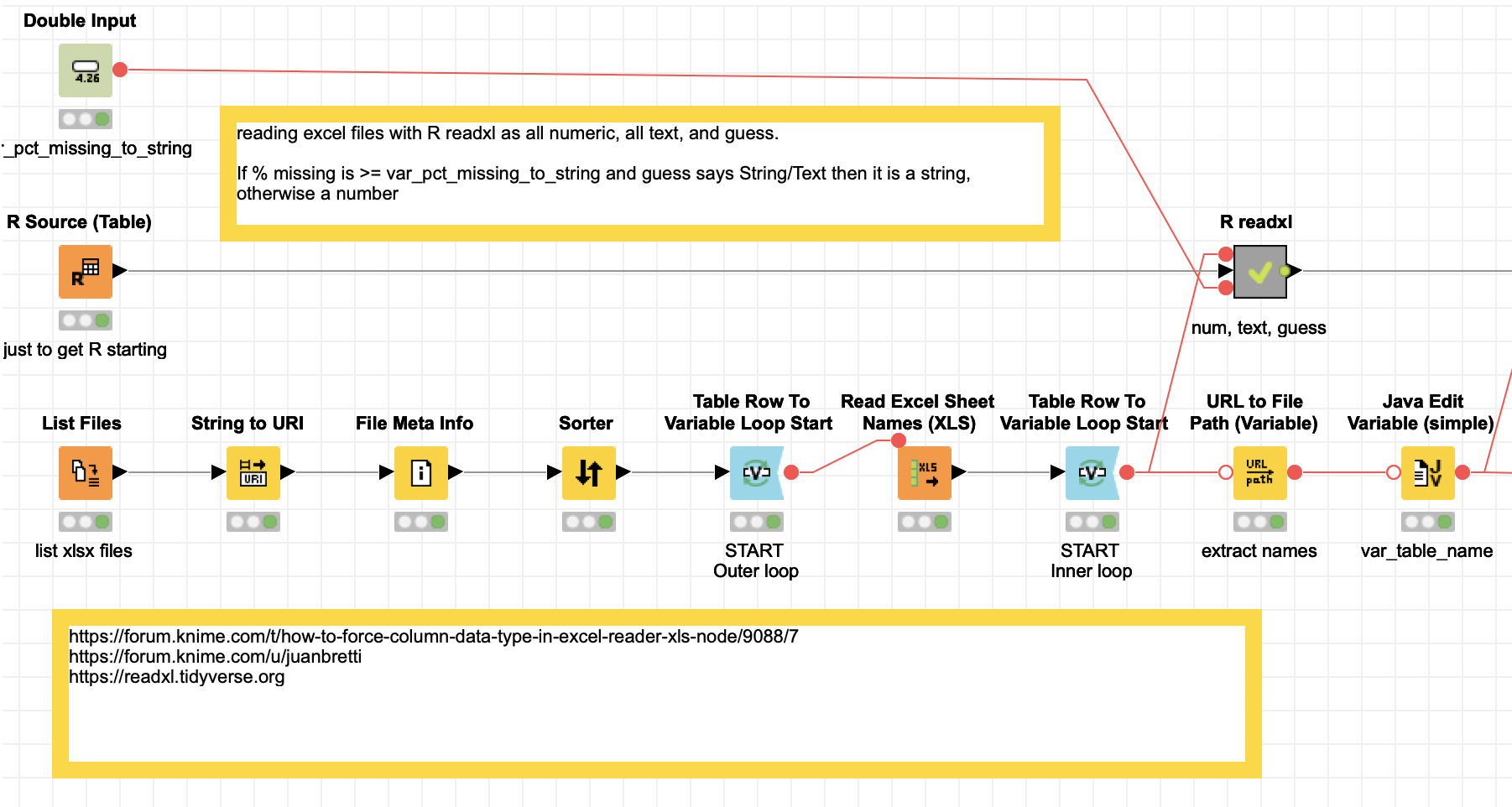
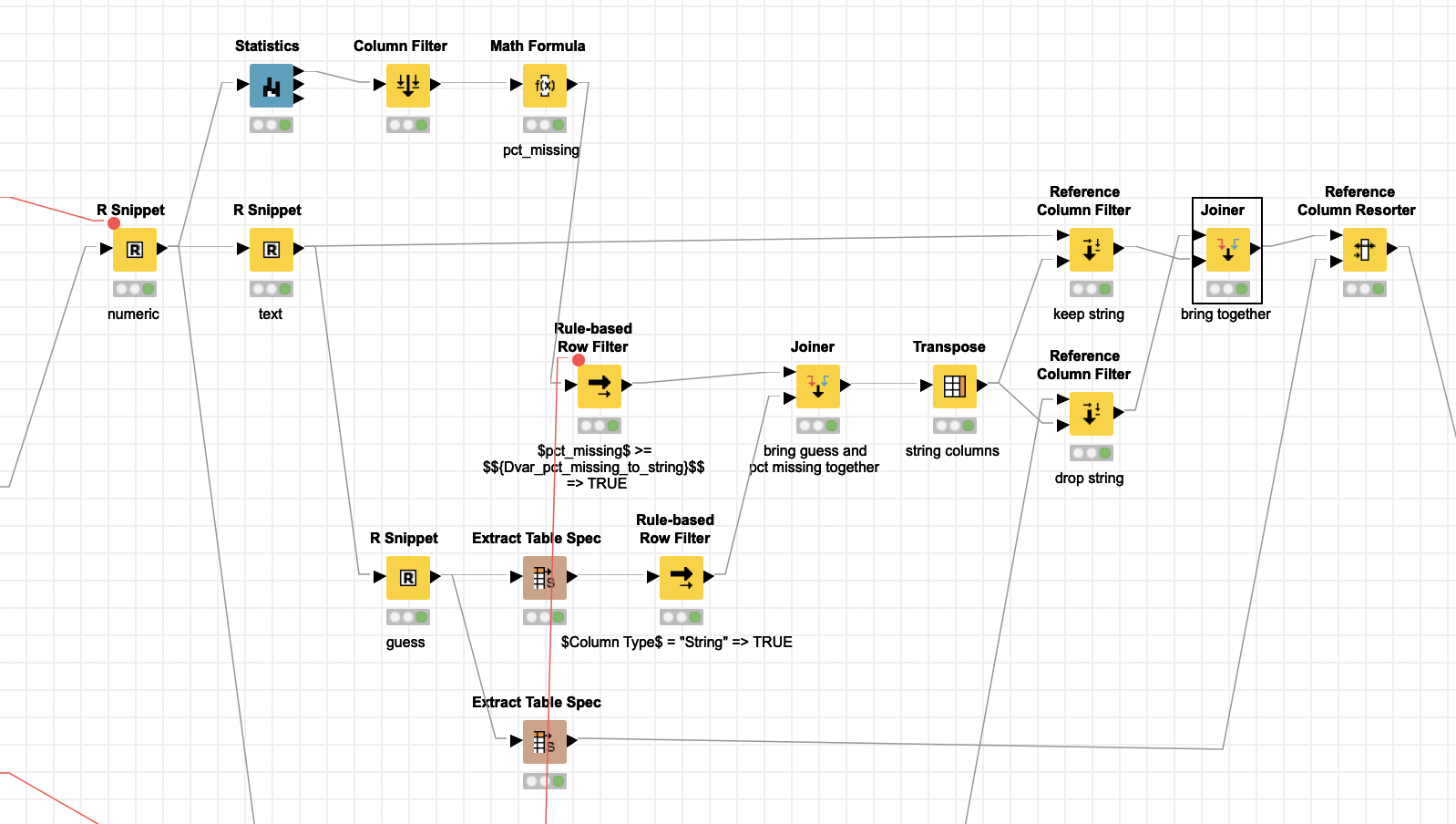
I built a workflow that uses your idea and does three imports of an Excel file, one all numeric, one all strings and one guess. For the numeric ones when it might actually be a String there will be a huge number of missings. I do a calculation of % missing and I set a variable (75%) if there are 75% or more missing and the guess suggests a String it is a string.
Obviously if you have date variables you would have to do something different.
Here the results are stored in KNIME tables that are named after the Excel file and sheet and also contain columns with that information.
the new Excel Reader node available in version 4.3 always reads doubles with full precision, even if there are Strings in the column. Thanks for the feedback!