that is actually a good idea 
I built a workflow that uses your idea and does three imports of an Excel file, one all numeric, one all strings and one guess. For the numeric ones when it might actually be a String there will be a huge number of missings. I do a calculation of % missing and I set a variable (75%) if there are 75% or more missing and the guess suggests a String it is a string.
Obviously if you have date variables you would have to do something different.
Here the results are stored in KNIME tables that are named after the Excel file and sheet and also contain columns with that information.
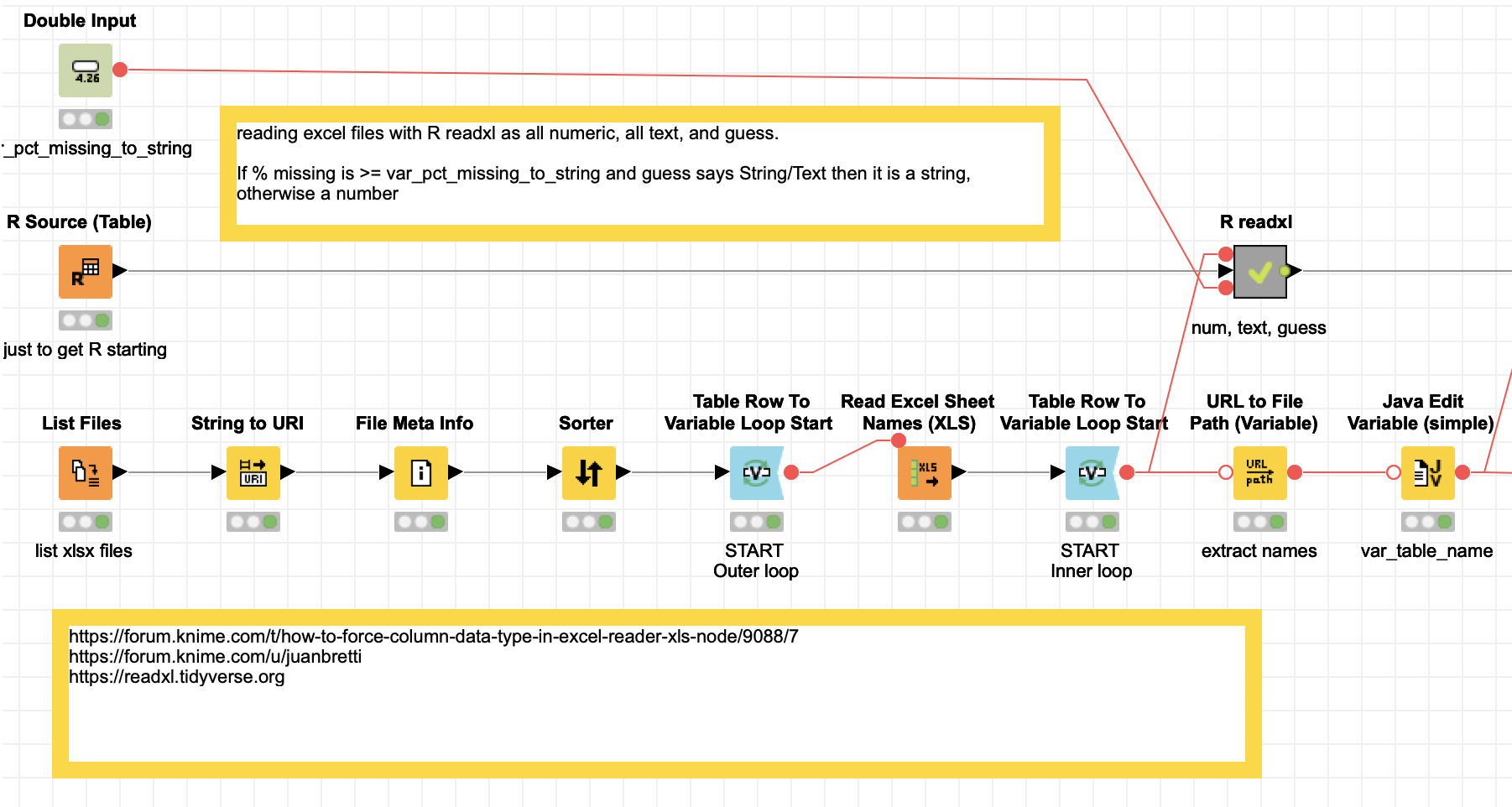
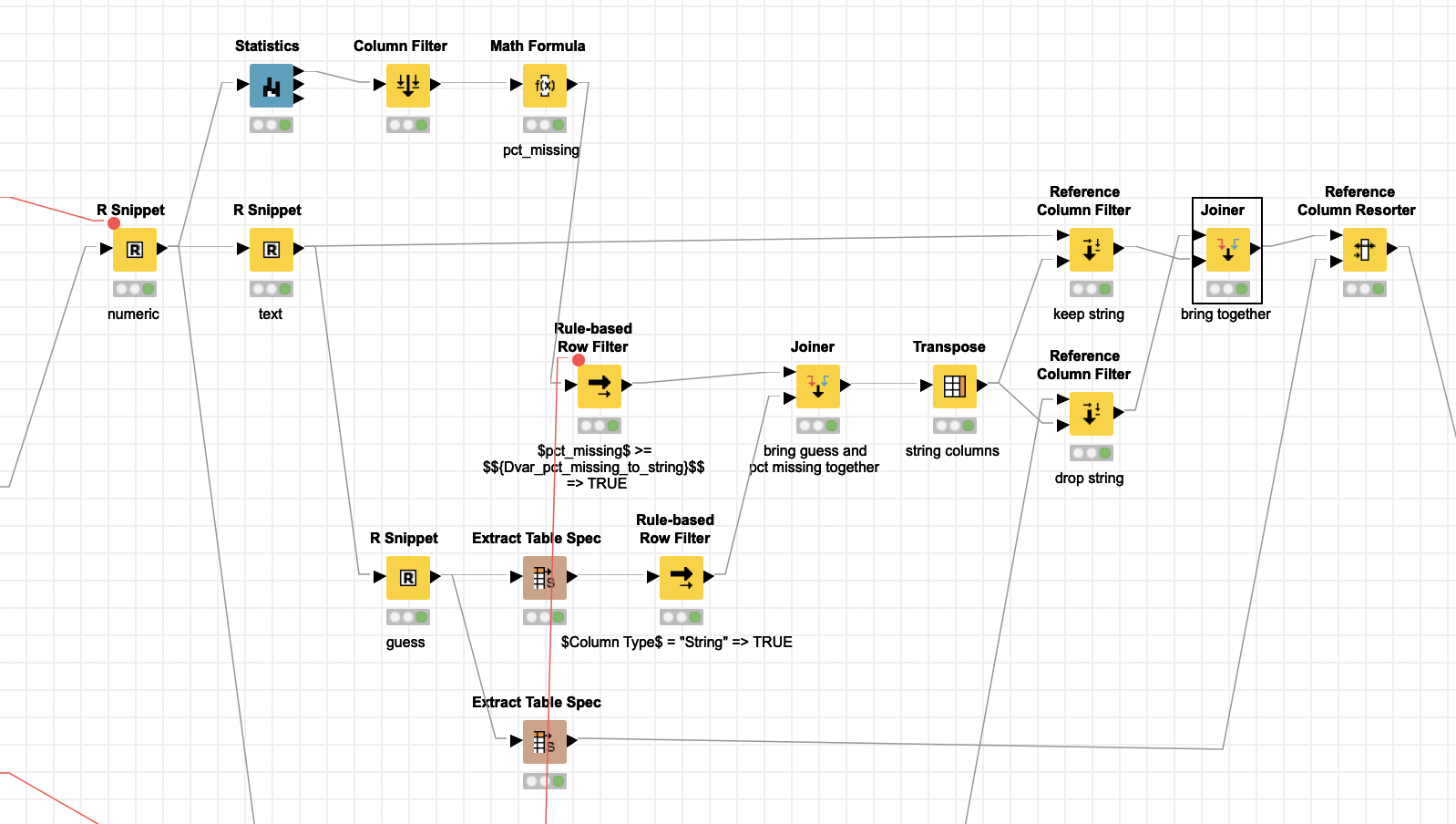
kn_example_r_readxl.knar (179.5 KB)
… hmm did someone say over engineered …