I am “used to” inspecting the source code to find a good xhtml tag to “attack” but the problem is that this approach does not work (at least I don’t know how) right now as this autosuggest list disappears the moment I click e. g. on inspect.
hmmm. That didn’t work for me. Whenever I click anything in the DevTools, the autosuggest list immediately disappears.
Somehow I can get css class but I simply cannot extract the “popup” (so to say) which also makes sense because it is not shown / not there in the Selenium driven browser. It only appears once the user has made an interaction with the website, so source code extraction also does not work.
The timing and order really matters. Here’s an example:
(here should be an animated GIF which I cannot upload because it’s too big - I’ll try again later)
If this still does not work, try to use the suggestion with the setTimeout. First, paste the code and hit return, then interact with the page to show the popup and wait until the timeout triggers. Then it should stay open.
However, I simply cannot extract the data from Google, because whenever I go through it multiple times I get an empty list except for the first entry in my keywords list.
I guess Google / YT is a little bit to sensitive regarding these automated scraping approaches
I am a little bit hesitant to always ask for a help because - quite honestly - this sounds a little bit like something I “should know” (if only i dug deeper).
However, all your feedbacks always provide great insights.
Here’s the workflow. I’ll try to find a way as well…
during a long ride I had some time to play with the workflow.
Generally: Really a cool idea scraping these search suggestions, approximately 1,238,236 ideas what to do with that came to my mind
Some specific recommendations regarding the workflow:
I noticed that when executing the workflow, sometimes the suggestions would show, sometimes not. Likely it’s due to the fact, that automaton “types” too fast, and thus the suggestions are not always triggered. There seems to be an easy fix for that though: Pushing the cursor down button explicitly triggers the menu. You can simply achieve this by adding another Send Keys node after the one which enters the query and which sends the key combination \uE015 (this code denotes the button – see the node docs)
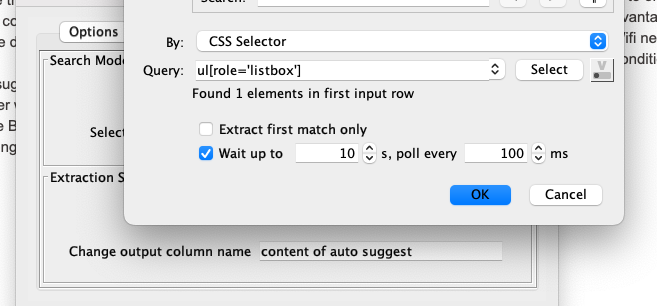
You had a Wait node to ensure that the suggestions are opened before taking the next step. “Dumb” waits have the disadvantage that you either wait for too long (b/c the results are there earlier), or not long enough (slow Wifi network, hello Deutsche Bahn). You can make this smarter by remove the Wait node and setting a conditional wait in the following node:
This will resume execution immediately, no matter if the suggestions appear or style.
I changed the CSS selector in the Extract Text to grab the suggestions from the auto-generated one to just ul[role='listbox'] which might be a bit more robust if the page structure should ever change.
I definitely like the idea of using the HTML Parser just to extract the results “statically”.
Here’s my modified workflow:
Did you have any success with the counterpart for Google, @kowisoft ?