Dear All
I have about 1000 features inputted into the MLP model, I would like to extract the Top 100 important features from the model output, is there any way of doing it?
Thanks
Lawson
Dear All
I have about 1000 features inputted into the MLP model, I would like to extract the Top 100 important features from the model output, is there any way of doing it?
Thanks
Lawson
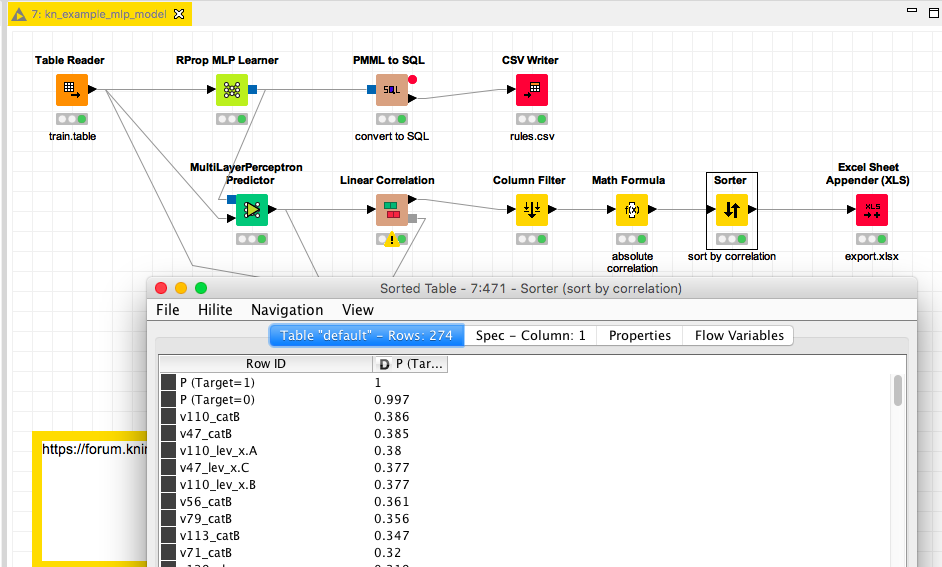
I was thinking about feeding the prediction of the model back to a correlation node (linear in this case) and then use the absolute value of the correlation to determine the strongest correlations towards the predicted Target.
The data is from a Kaggle competition (BNP Paribas Cardif Claims Management | Kaggle) with some transformations and only 500 random cases. So the numbers are just there to demonstrate the nodes. The calculation can be quite costly.
kn_example_mlp_model.knwf (1.3 MB)
I’m gonna argue that that is not possible as DNNs have to be considered as black boxes and this specific issue, eg. their interpretability is one of the main issues with DNNs.
What makes Deep learning superior in certain areas, mostly image stuff, is the fact that they build their own internal features.The actual learning isn’t done on the input features but the internally generated features. Of course the generated features depend on the inputs but the actual relation of input-> output through all the layers is rather difficult task if at all possible.
I quote:
Or to repeat myself the strength of a DNN is to see very complex connections between features that can’t really be explained in such a simple way. Example: feature A is very important if feature X has a value of 10 but else it’s completely irrelevant. This can’t be explained in a simple “Feature importance” table.
Even with random forests I’m kind of skeptical of Feature importance as being useful as a connection outlined above will also be completely missed. After all we actual use such models to detect complex rules / combinations hidden in the features.
Thanks for your explanation.
Is there any other way to “describe” which variables are relatively useful ?
Thanks for your illustration, but it seems not directly related to ANN, i.e. it is only a proxy approach, am I correct?
Yes you are right it only takes the results/scores and tries to indirectly guess which variables have a high correlation (either positive or negative)
I would ask why? This is my personal opinion but you don’t see all that much the reason to know feature importance especially when using a ANN. For example what’s the importance of a single pixel in an image?