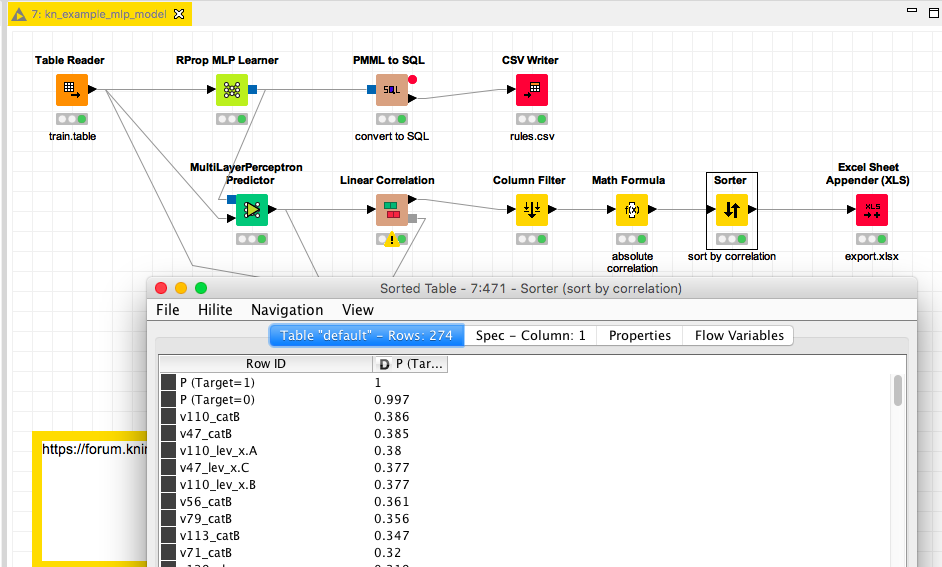
I was thinking about feeding the prediction of the model back to a correlation node (linear in this case) and then use the absolute value of the correlation to determine the strongest correlations towards the predicted Target.
The data is from a Kaggle competition (BNP Paribas Cardif Claims Management | Kaggle) with some transformations and only 500 random cases. So the numbers are just there to demonstrate the nodes. The calculation can be quite costly.
kn_example_mlp_model.knwf (1.3 MB)