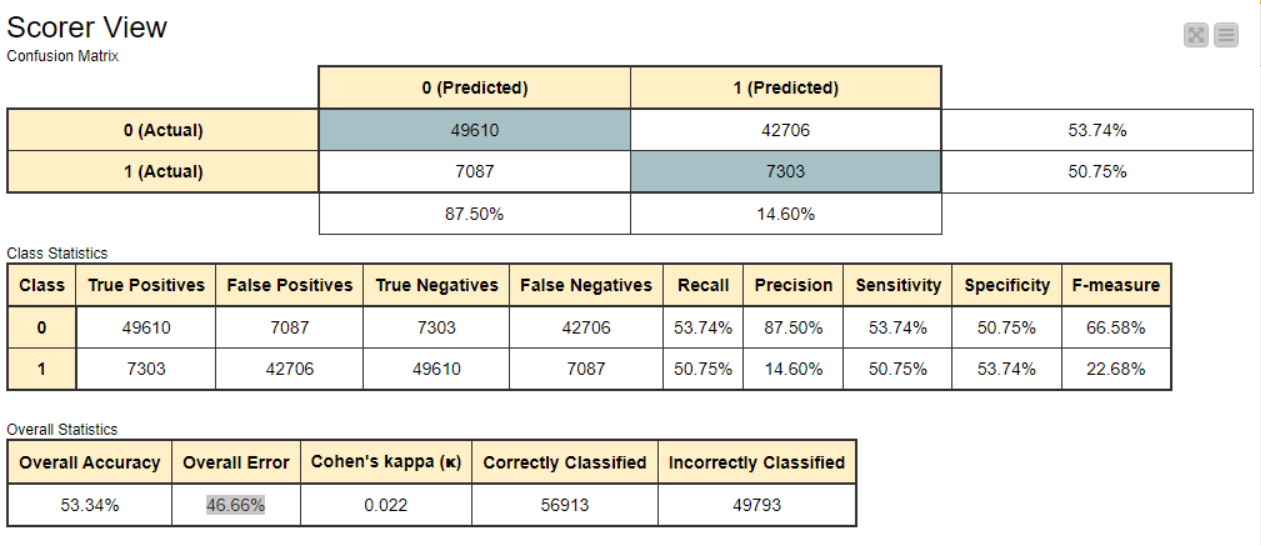
My team and I are developing a workflow to predict e-commerce fraud. Our dataset has 5% of transactions classified as fraud and we want to train a Fraud prediction model based on Non-Fraud Transactions. Using the Keras Neural Network we obtained the following results but we would like to know if you have any suggestions on how we can improve our results.
Thank you so much for posting on the forum. The dataset is highly imbalanced but such is the reality in real-life. While others may have very strong opinion or even disagree with what I am about to write here - here are my suggestions:
One approach would be to trim down the majority class. This could involve dropping rows with missing values. Since you are swimming in non-fraud class then loosing some data there is not big deal (assuming that you have several thousands of rows in the dataset). This will ensure that you use pristine dataset for training, validation and testing. If above approach does not decreases the imbalance then maybe you can do some synthetic row sampling (on majority class) such that imbalance is significantly reduced. KNIME provides a bunch of nodes for row sampling.
I am assuming you already have tried that and reached the posted figures above.
Next, what I normally do in imbalance cases is to establish a baseline. That is, without actually doing any sampling or trimming of the dataset, use the dataset to create stratified sets (stratified on target variable) for training, validation and testing. Train the model and establish that as the baseline model. After doing under-sampling/over-sampling on the dataset, create trainining, validation and testing sets again. Retrain the model and observe the Cohen’s kappa, in the screenshot shared, the value of coefficient is relatively low, however, closer the value is to 1 much better or rather “generalized” the model is. You can read more about its application here.
How well your new trained model do? You can compare it with the baseline and specifically check other variables, especially Cohen’s kappa.
Please note that my recommendations are more data centric and not model centric. Yes, you might be able to push the figures by toggling the Autoencoder architecture:
This can involve increasing the size of latent space.
Training on larger number of Epochs
Using multiple hidden layers
… and so on.
Hope the recommendations are of help to you. While this is a very iterative process, there is never the best approach to it.
@LBSleonor to be honest from my perspective this model is not very good if you have such a sensitive and small target. What you can do is work on the data preparation and hyper parameter tuning to get somewhat better results and also try H2O.ai AutoML to cover several modeling approaches.
You can find an overview of models here. And maybe use AUCPR as the target statistics