Hi @Cosmo72 ,
Thanks for uploading the workflow with sample data.
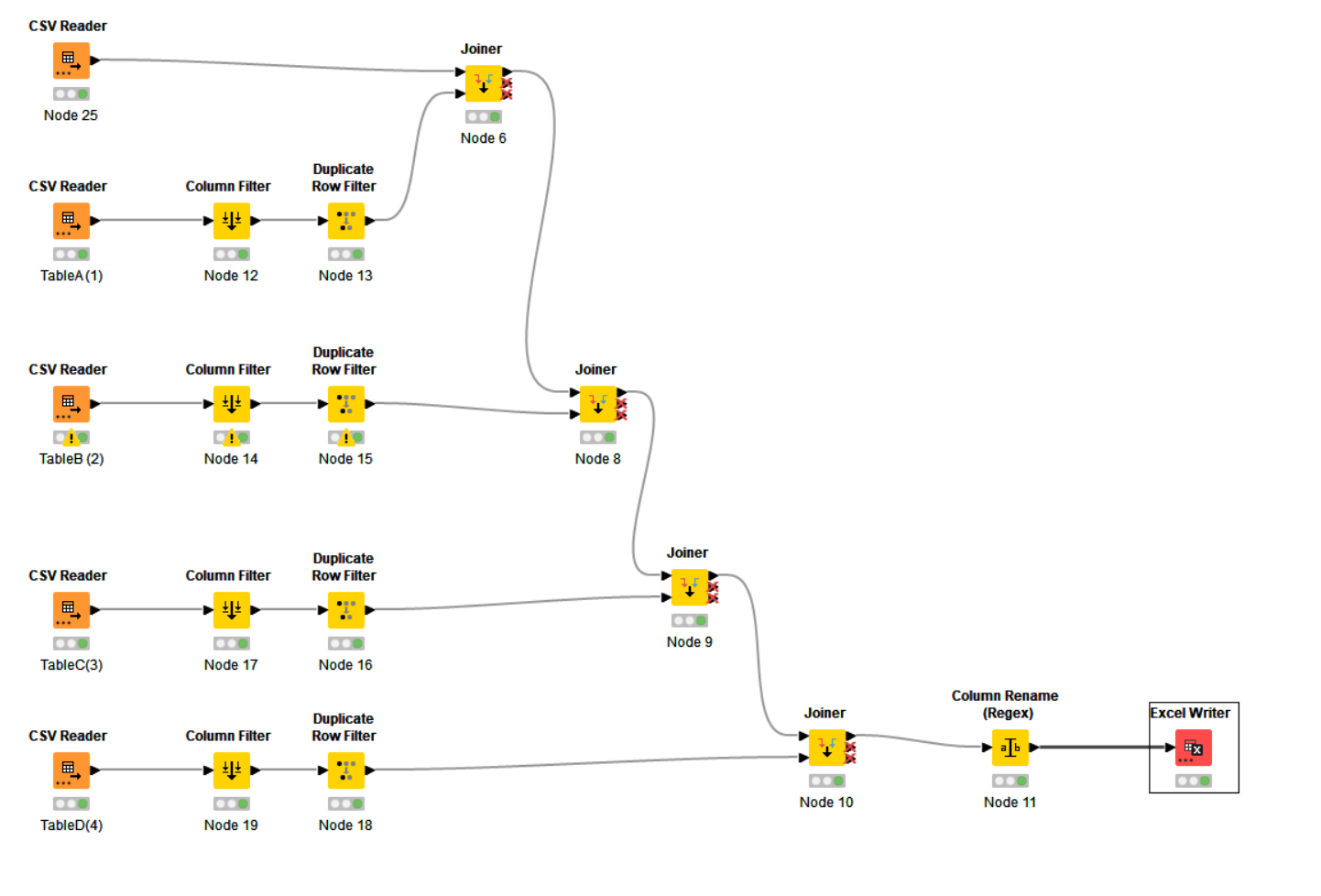
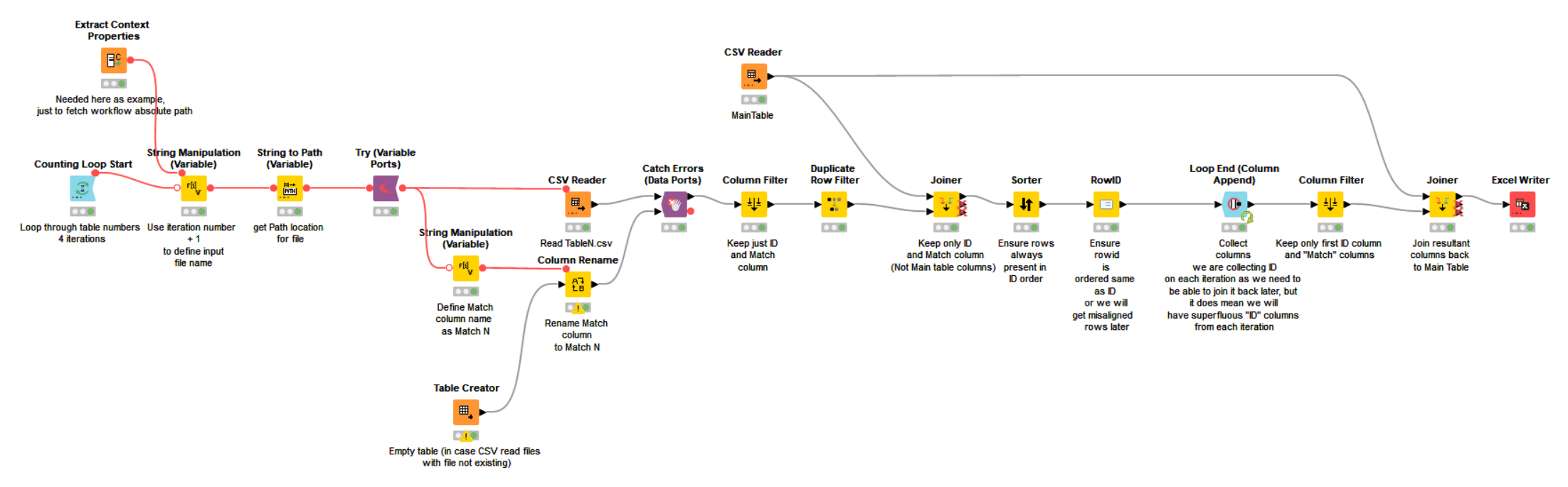
I used the sample data files (stored in the workflow’s data folder) to demo this component which may (or may not) be of interest. I’ve basically enclosed a CSV reader into a component utilising the technique from my previous post.
I may be going wide of the mark here now, as possibly your original workflow doesn’t have csv files, but if that is the case, I still don’t fully understand how you end up with tables “that don’t exist” in your KNIME workflow. so anyway this may give some additional ideas, or be useful to somebody else(!).
One of the problems with component solutions in KNIME though is that they then bury away all the settings of the thing you are trying to encapsulate and whilst some things can be exposed through configuration nodes, things like “file/folder browser” functionality can’t be easily replicated. However, something like this may suffice. Obviously the CSV Reader node has a lot of configurable options on it too, and not all of that could be replicated in the component. I have not tried to replicate any of the other settings, as it would be quite a painstaking (probably unworkable) exercise. If other settings on the CSV reader are required, then the best option would be to clone the component and adjust the settings to those required, and then reshare it yourself. If this solution is generally workable and you want more info on what I mean by that, then please ask and I’ll try to explain more fully.
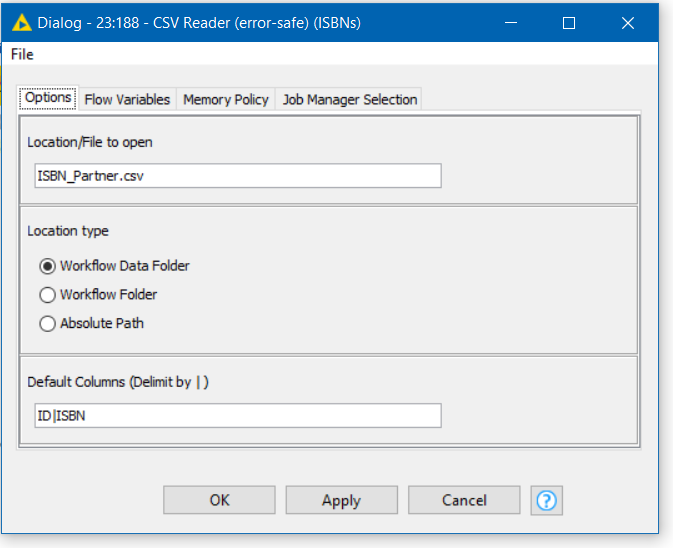
So basically the component offers the following minimal settings:
Where the user can simply type in the name of the file (including the full file path if “absolute path” is chosen. Alternatively the file can be located relative to the workflow by choosing, as in the demo the “Workflow…” location options).
The other setting is the “Default Columns”. This is the minimal required set of columns that the component must return as an empty table if the file does not exist, or no file is specified. They are delimited using the | character.
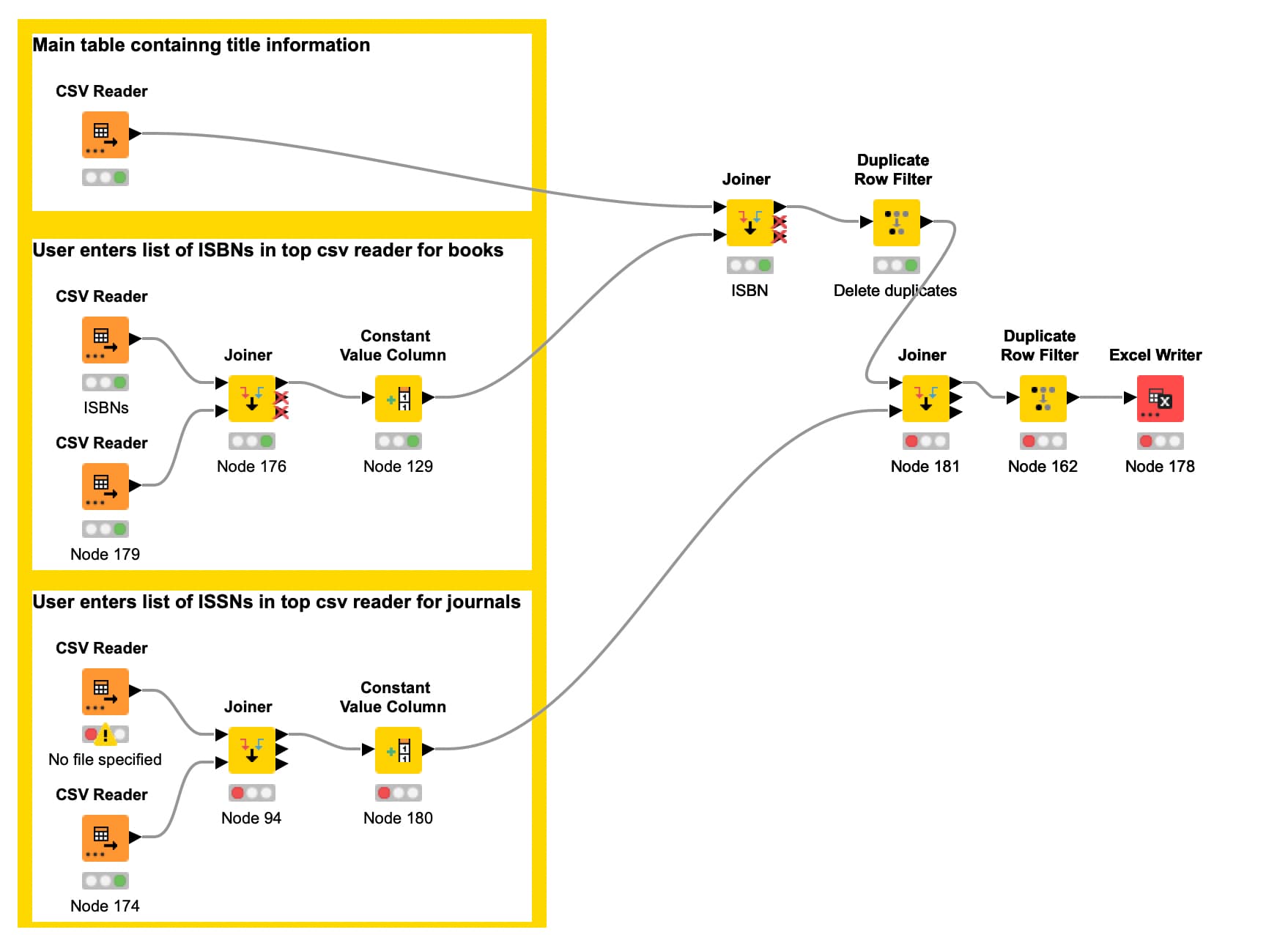
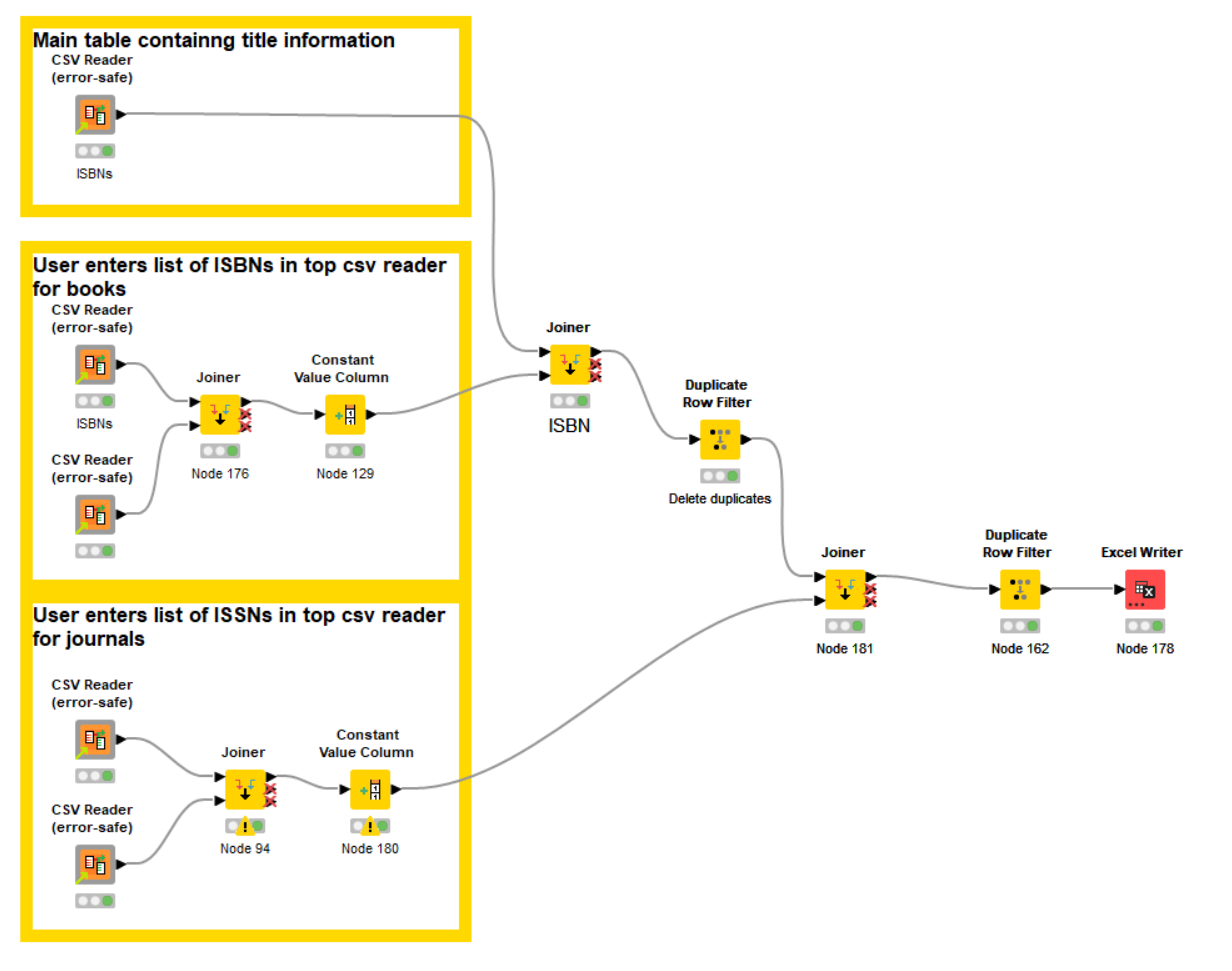
This component can then be included in your workflow like this, which keeps things reasonably simple:
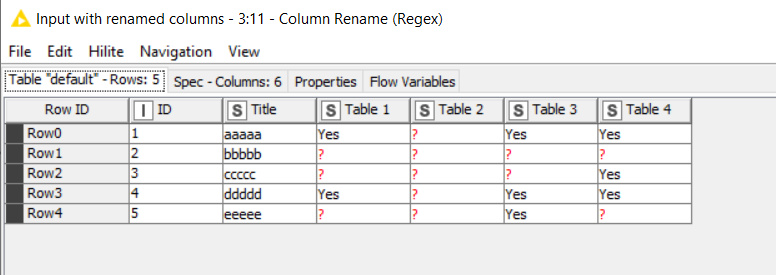
To make this work, I had to fix your joiners so I took a guess at what they should be. Given that you have “optional” files in your workflow, for it to end up producing anything, you need to change some or all of your joiners to include “unmatched” rows from one or other of the tables. If they only contain “matched” rows, and the user doesn’t provide anything to match, then clearly the joiner cannot return anything. As I reread your original post, I’m wondering if this is actually central to the problem you are experiencing? Are you only returning “matching” rows in your joiner and expecting it to return data when one of the tables being joined is empty?
Anyway, here is the above workflow demo
Table_does_not_exist_new with component.knwf (457.2 KB)
The CSV Reader (error-safe) component can be found here: