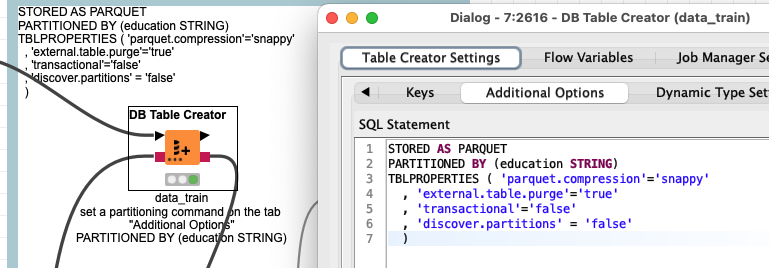
@hhkim You can use the „DB Table creator“ with additional settings for partitions and then load data into the newly created table. The DB Loader would need a temporary folder in the HDFS file system.
You can try and adapt this example here. Please note the partition would be the last column and is being omitted i the create on purpose since it will be set in the additional options.
Another option would be to load the data into a temporary table and then use an SQL Executor command to insert the data.
Here is a complete „self-healing“ reporting system with Hive that could demonstrate additional functions:
@hhkim I created an example workflow that would demonstrate the use of Hive tables and partitions with the KNIME DB nodes.
If you want to do an OVERWRITE of a specific partition the easiest way to do so would be to first explicitly drop the relevant partition (there is a node doing that in the example).
I think DB Table Creator or DB Reader node can use my local PC resource.
So I just want insert selected DB data into DB table directly by using “INSERT OVERWRITE with PARTITION” query.
“INSERT OVERWRITE with PARTITION” query can use when the table that I want to select already exists.
But when the table that I want to select comes from DB node, I don’t know how to do.
I hope my explanation is enough so you can understand what I mean.
@hhkim there ware two ways to add a partition to an existing one:
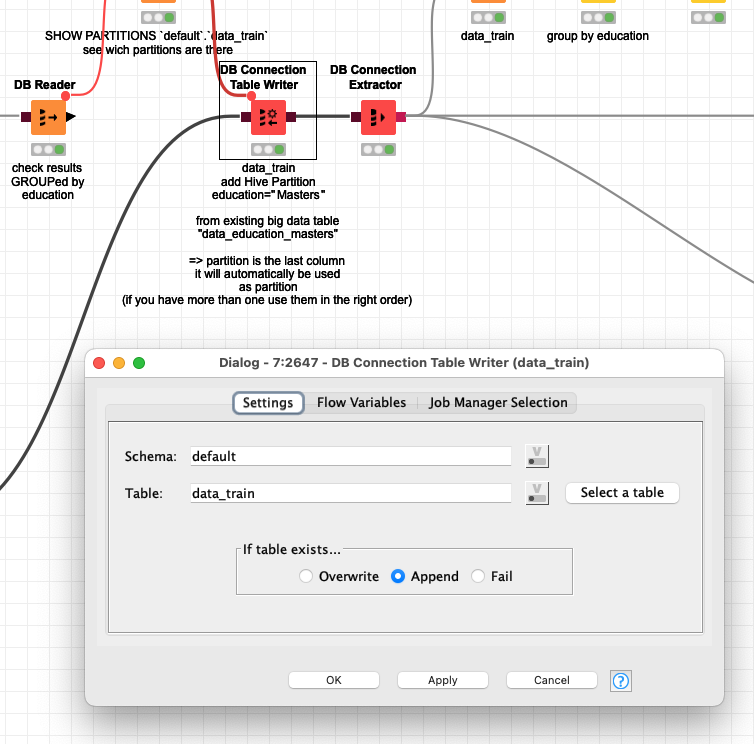
You can use the DB Connection Table Writer and just make sure your partitions are in the same order (at the end) of the file - like in this version the column “education”. Here it would append the data (all educations=Masters) if you would execute it more than once:
Or you could use the syntax you already have mentioned - “INSERT OVERWRITE” where you mention the partition column. Again: the partitions have to be the last columns (and have to have the same order as in the target file).
INSERT OVERWRITE TABLE `default`.`data_train`
PARTITION (`education`)
SELECT *
FROM `default`.`data_education_masters`
Summarizing your answer, I understood that I can insert the data through the “DB SQL Executor” node when the table I want select exists, and I can insert the data through the “DB Connection Table Writer” node when the table I select does not exist.