First of all, your question is more about understanding how this perplexity score works. There is nothing wrong with that. But getting an answer on this specific result wont help you in long term. I would like to refer you to this medium article.
Also, the workflow you mentioned is created by one of the KNIME community members. If you scroll down on the page of the workflow on the KNIME Hub, you have the option to start discussing the workflow right there on the hub page as shown in the screenshot below.
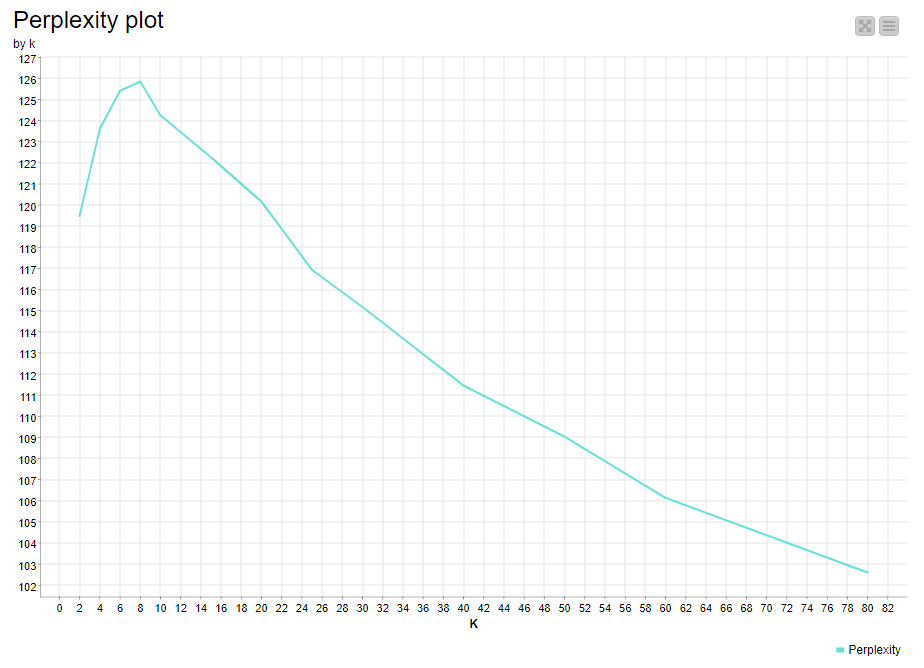
I think you are right! I am still quite perplexed because of the perplexity score. I admit I do not have a deeper technical understanding of this method, but as far as I could understand, the lower perplexity is, the better the model fit.
For example in a chart like this I would assume that the “optimal” topic number is 3 (right?):