Hi, I want to load data into Snowflake from an Amazon S3 bucket.
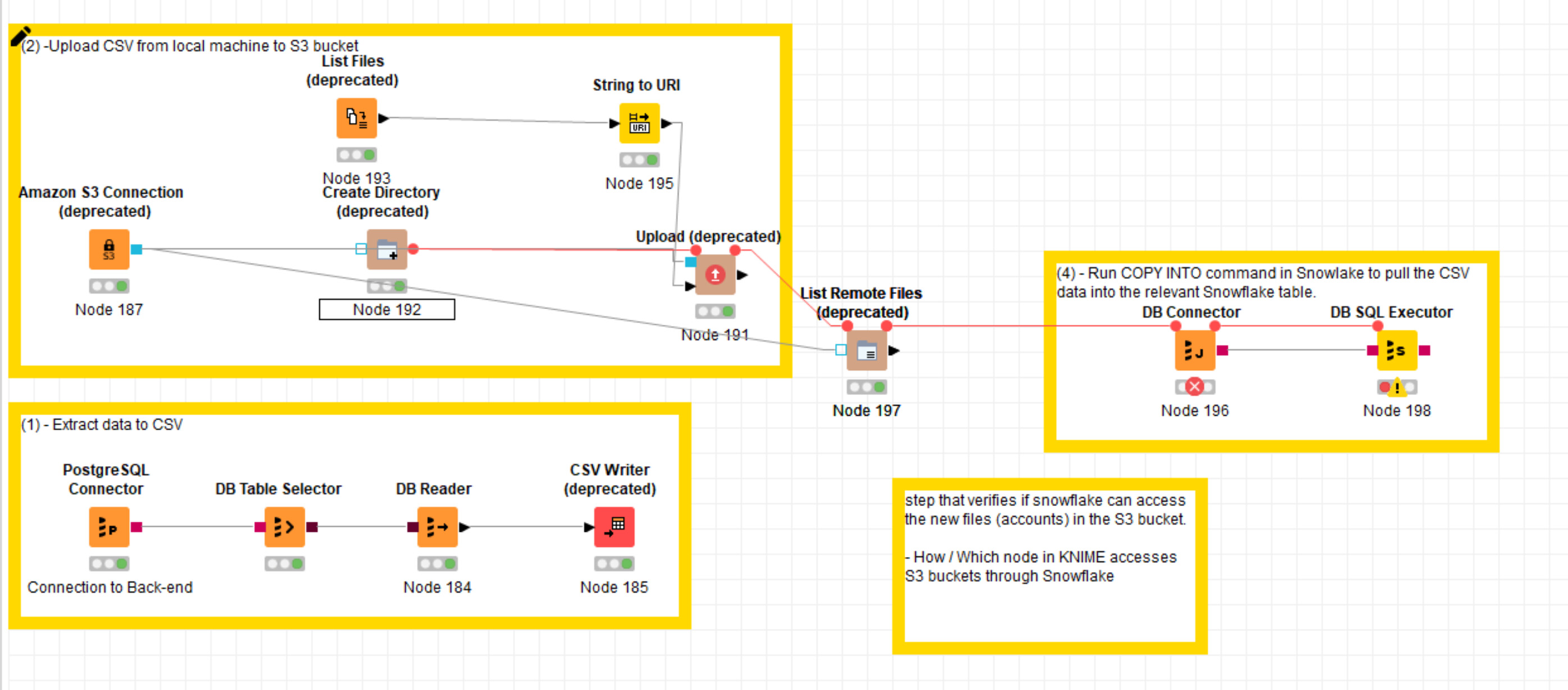
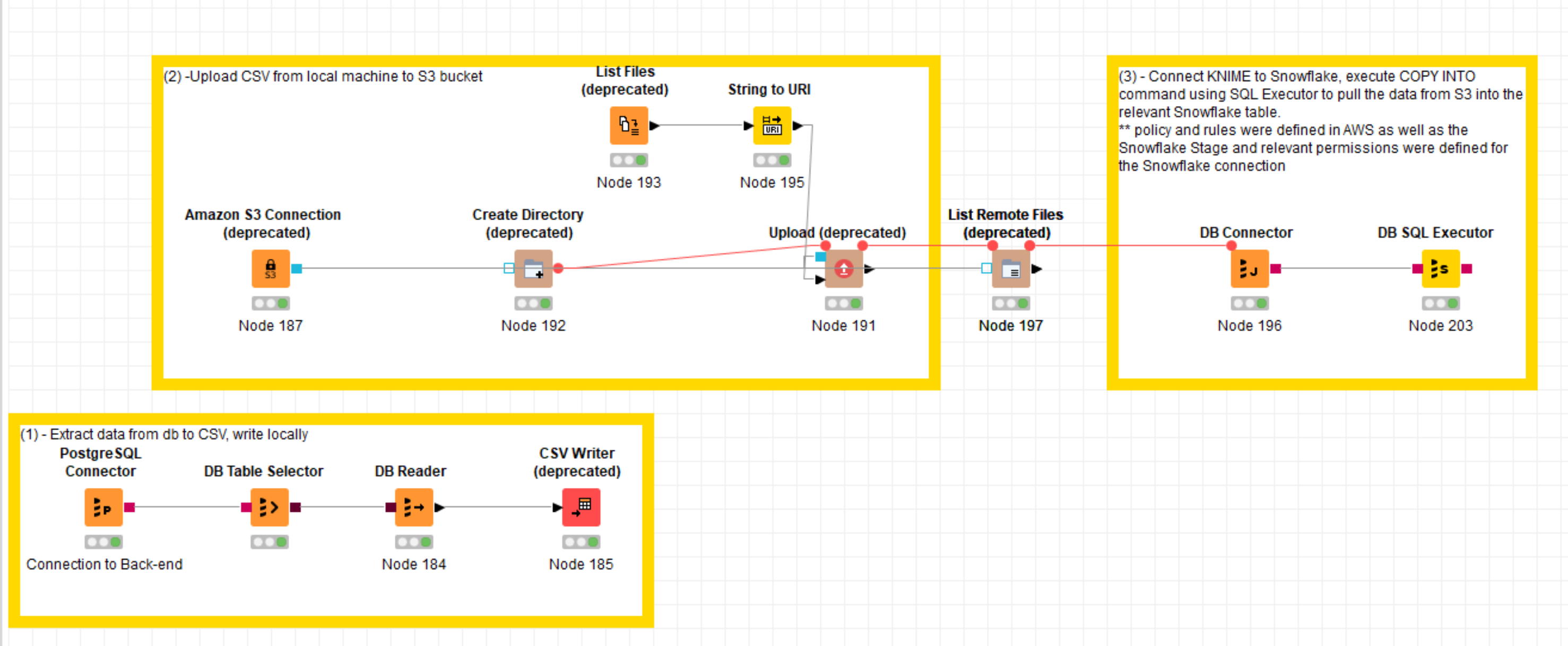
As described below, first I create a .csv output from a source database. Second, I upload the .csv to the S3 bucket, then use COPY INTO command by DB SQL Executor node.
I have created a stage on Snowflake that has access to the S3 bucket and I can pull the data from the file directly from Snowflake GUI.
What steps or nodes are missing in the workflow to replace the step described above?
Not sure if you made any progress on this one! Please enlighten us if you did.
From my understanding, Snowflake can directly query S3 staged files. If the List Remote Files actually outputs the file you want (and you could try reading it back into KNIME as well to confirm its working), then I would focus on the Snowflake portion of the workflow and not on S3.
The third step establishes a connection to Snowflake (DB Connector), the next node (DB SQL Executor) executes COPY INTO of the CSV files from the Snowflake S3 stage to a Snowflake table.
Here is the query executed within the DB SQL Executor looks like: COPY INTO people( a, b, c,
``d) FROM '@s3_test_stage/people.csv' FILE_FORMAT = ( TYPE = CSV, FIELD_DELIMITER=',', RECORD_DELIMITER = '\n' , FIELD_OPTIONALLY_ENCLOSED_BY = '"' SKIP_HEADER=1) force=true;
It appears several nodes seem deprecated, e.g. Amazon S3 Connection, CSV Writer, List Files, Created Directory, Upload and List Remote Files.
Only Amazon S3 Connection and CSV Writer seem to have equivalent new nodes to replace the older ones. For instance, Amazon S3 Connection becomes two nodes - a connection node and an authentication node.
What nodes to use to create the same workflow or process without using the deprecated nodes?
Glad to see you’re making good progress! Here’s an example that shows most of the new cloud nodes. https://kni.me/w/QXPXSwpKpCJaDu1k
There is a new File Handling Framework in the latest release of KNIME, where many of the nodes are now independent of the file system. So you can read/write directly in many cases.