Hi,
I am doing the data analysis and have an input dataset, for example like this: 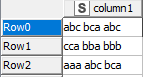
Then I would like to count the unique value in this table, the desired output is: 
I tried to use the value counter node, but I got Execute failed: Encountered duplicate row ID " " " " at row number 2. I checked the related topics, it seems that I have duplicate row ID " " in line 2. But I cannot find such a row with ID " " in line 2 of my dataset.

Since I am a newer of Knime, I am even not sure if using value counter is the corrent way. Any suggestions?