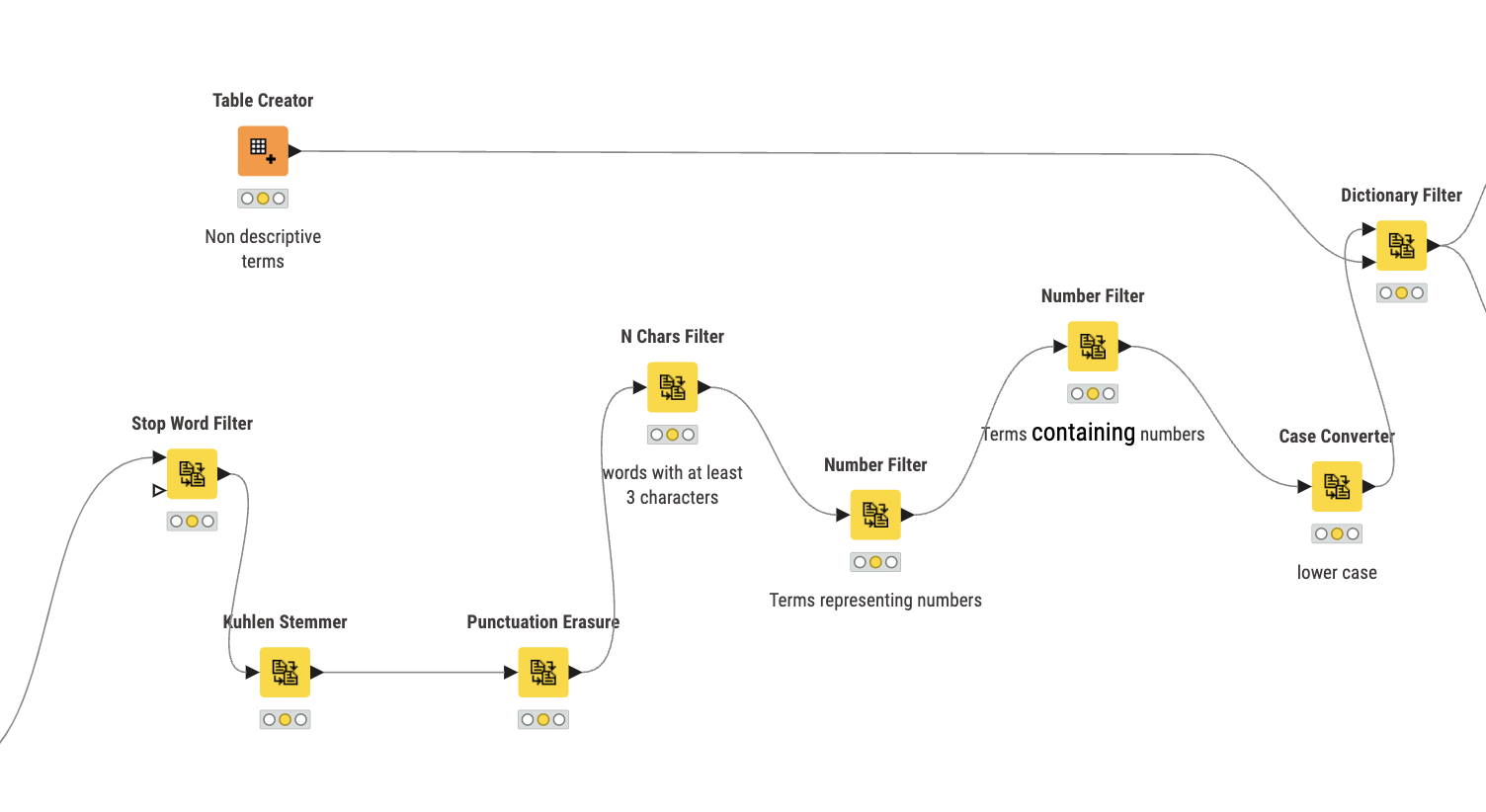
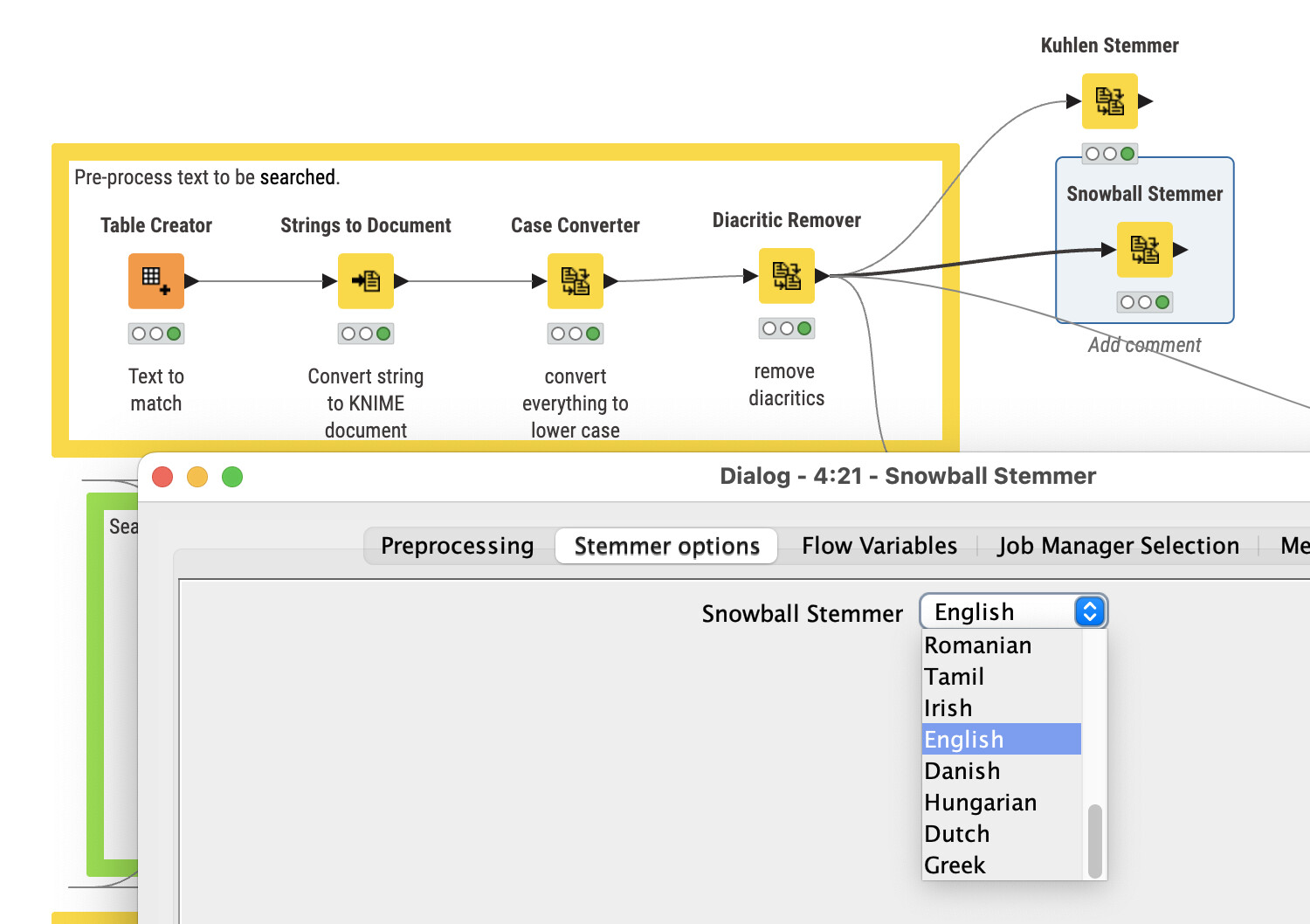
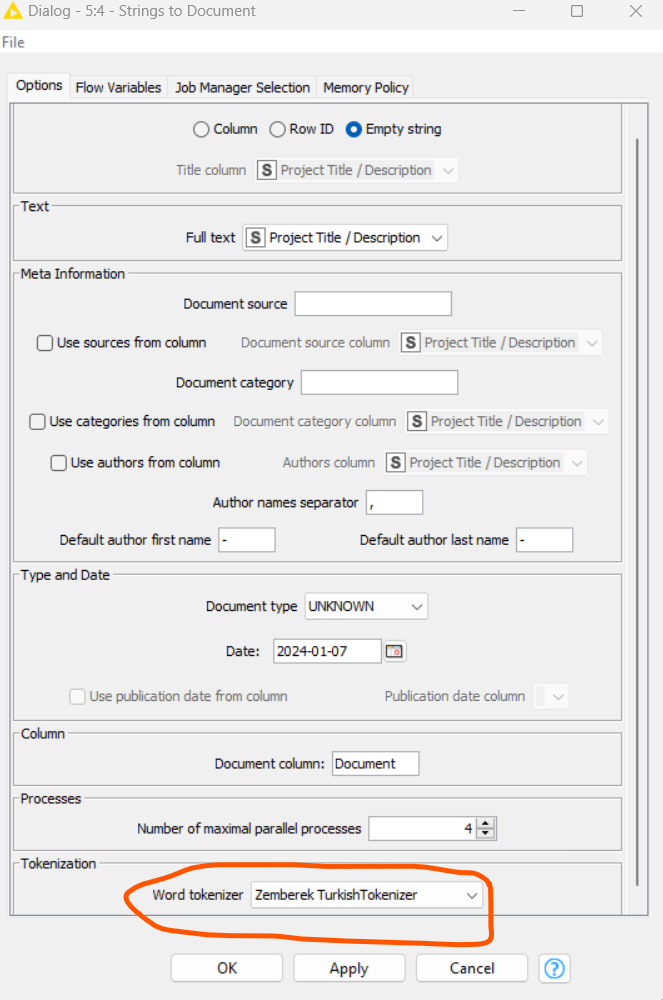
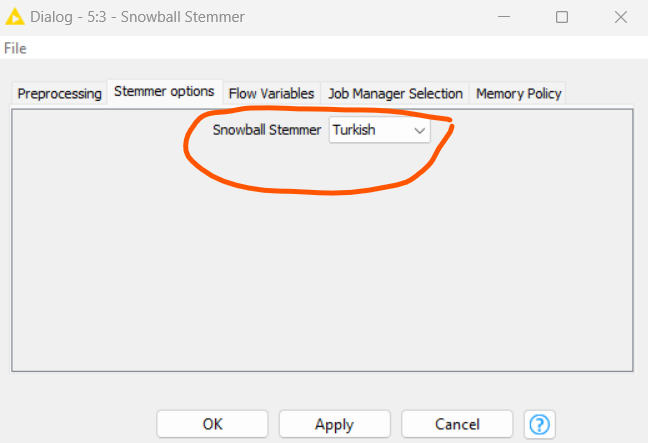
Hello everyone;
For a few days, I have been lost in trying to make the most accurate and highest matching classifications for a common standard classification in different languages.
I’m trying to find the most accurate and working workflow that can be implemented in any language. Classifying code from a data set. (with reference code list prepared for each language)
** But the most important part is to create the best classification or the most relevant classification in each language. English, French, Spanish, German… It’s easy, but even now I’m working with data containing 26 languages and the number of languages will increase.
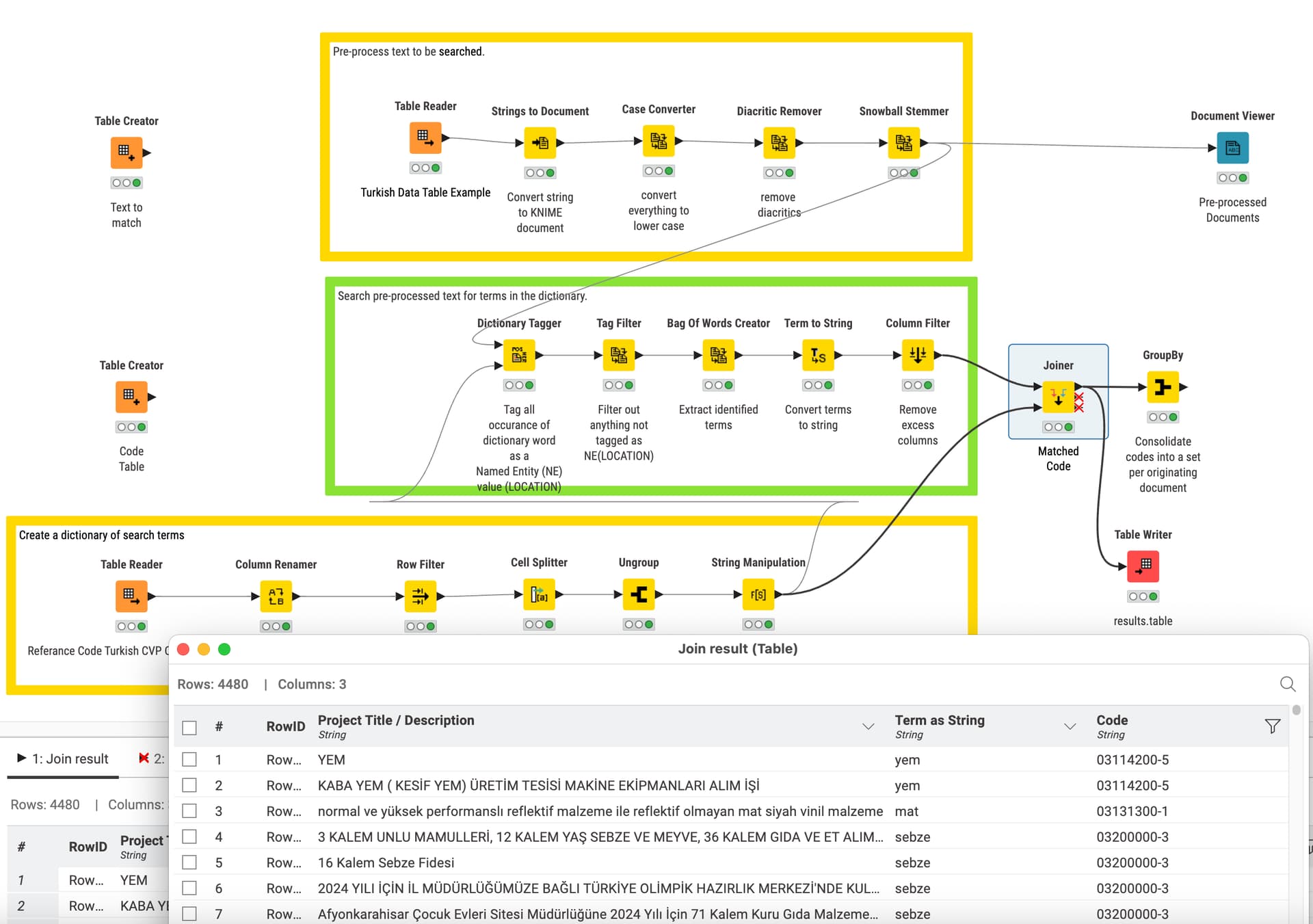
What I’m thinking about right now is from the simplest perspective. I created reference code and description for 26 languages. If I can include any word in the description section in the classification/category addition section, as in the example below, I will be one step closer, at least a classification will be created in the reference code list created for each language.
Example;
Data: Cable and construction repairs will be carried out in Paris.
classification/category
code: 112 / description: construction engineering services
code: 488 / description: cable supply
code: 266 / description: cable works
code: 996 / description: construction products
As a result, all codes must be present in the classification code column according to the data. Because; It is necessary to be flexible to produce the most relevant and close approach. If it is only based on the description in the code list, the matches will be very few. If there is a rule that the word group in the code description must be present even if it is irregular in the text, this will not happen and matches will be low.
** To create a must-have code classification group; If any word in the code classification description is included in the data text, add it to the code column.
In other words, the column output should look like this for the example data above:
Classification code: 112, 488, 266, 996
Finally, if there is a better method, please share your example. But I need an example of a workflow that works like this that will work for me in any language.