I have a PDF file that I upload to KNIME using this script
import pandas as pd
pdf_file = “C:/Users/aldem/Desktop/New folder/OC08320.pdf”
with open(pdf_file, ‘rb’) as f:
text = “”
output_table = pd.DataFrame({“Text”: [text]})
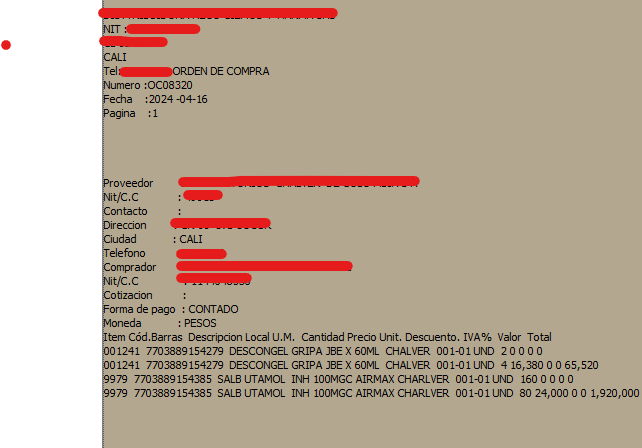
But the PDF was left this way
I would like it to stay this way
As is the original PDF
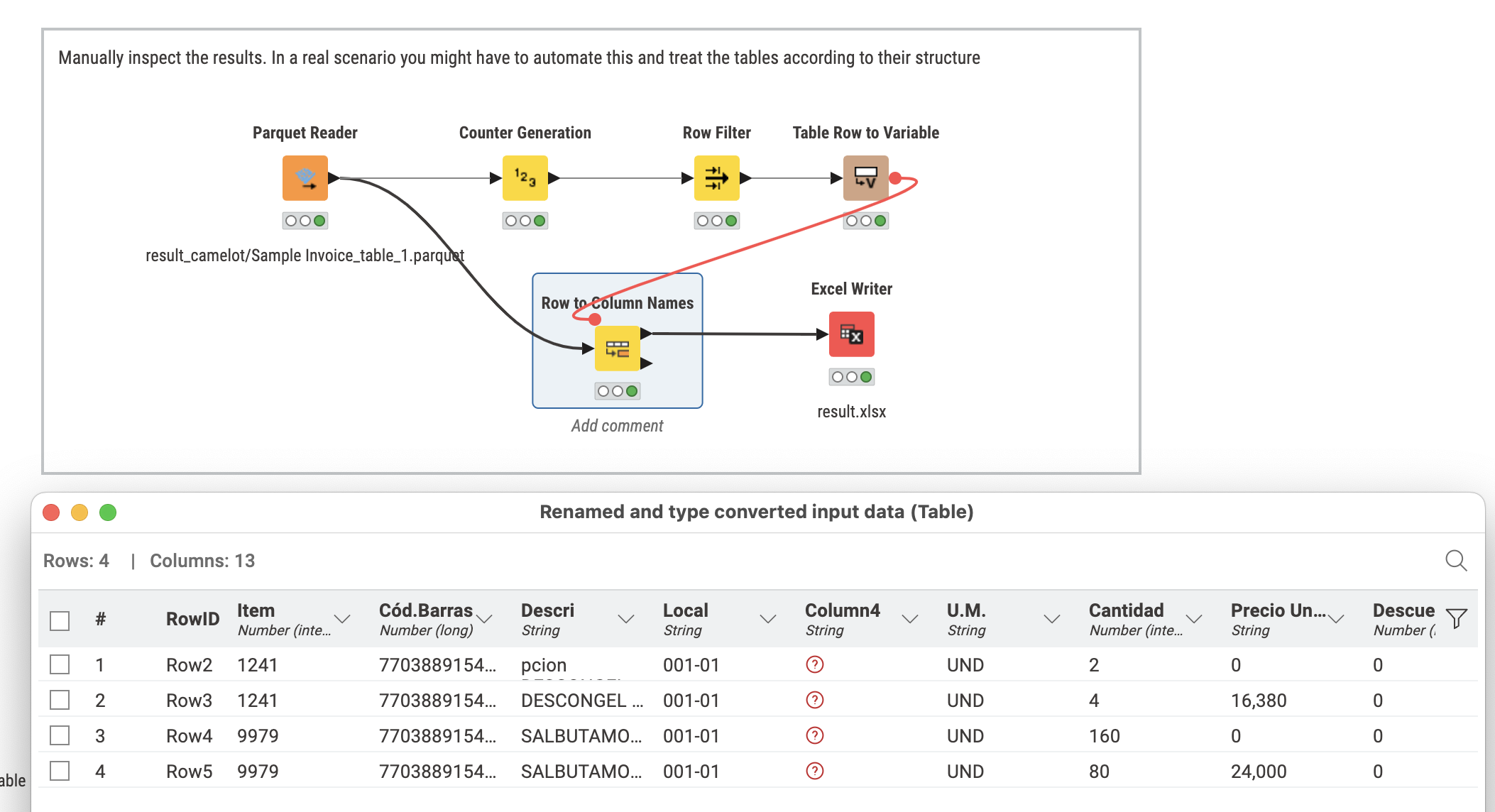
@Aprins maybe you could provide us with a sample file. If you want to extract tables from a PDF I have this article with code and examples.
1 Like
Thank you very much for the reply
But where I am working I don’t have access to those Python libraries.
Here is some sample of the PDF FileOC083201.pdf (33.4 KB)
I have a question, to do all that, do I have to use all that big flow? And the other question, does that work for any PDF?
@Aprins the article should explain how this works. And this would work on all pdfs though they are notoriously complicated structures so it will depend on the specific format. But the Camelot Python package can detect tables and the KNIME setup can help processing them.
system
August 13, 2024, 10:11pm
7
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.