I am novice in Knime platform. So, apologies if I am making no sense.
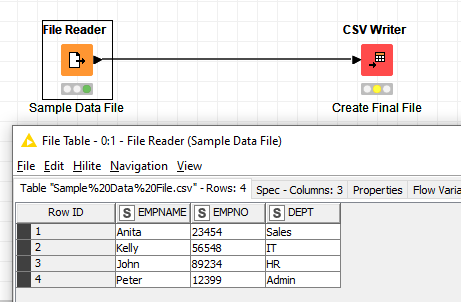
I have a requirement wherein I have to read a CSV file (I figured this part) with some structure, say 50 columns.
Then I will do some manipulation, transformation (I think I can do this part as well) on the column(s).
Ultimately I need to write to CSV file with some structure say 100 columns and output file. Sequence of columns are important for output file.
Is there a way in Knime using which I can do this. I mean any node for data mapping between source CSV to target CSV, or something like that.
Your requirement is frequent, makes sense and KNIME can do it just as you described it. Read your data, perform manipulations and transformations on it to get it into format you need and finally write data out. As you are novice in KNIME I recommend this (free) E-Learning course where you’ll learn basic concepts around KNIME: https://www.knime.com/knime-introductory-course
In above link you’ll find more learning content that can be useful. To check KNIME examples (&more) you can explore KNIME Hub.
Is there a simple way if I want to add 100 columns.
How I can map data in these columns. Is there a way I can map data in column values dynamically(may be depending on some values in other column. For example: I want to derive Manager based on EMPNAME).
Is there a way I can reorder columns of the file reader. Ex: From EMPNAME, EMPNO,DEPT to EMPNO,EMPNAME,DEPT.
Don’t think so but on the other hand why would you like to have 100 blank columns?
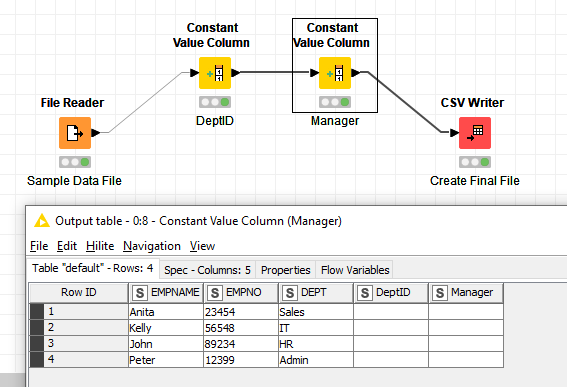
This depends on mapping. For example if you want to have new column with manager name depending on employee name you can use Rule Engine (have in mind that Rule Engine, as well as other nodes, don’t need a blank column before in order to be populated). And if you have manager name together with employee names in other table you can use Joiner or Cell Replacer to add new column to your table
Use Column Resorter node. A way to find out about nodes is to look for/search them in Node Repository from within KNIME Analytics Platform or on already mentioned KNIME Hub
Here is basic ETL workflow example which you can check:
I will need blank columns to match with the output file structure, as it has a predefined structure.
I think this information will be sufficient for me for now.
Actually yes. Use Table Creator node and add as many column as you need with proper names and types. Then use Column Appender node to add them to your input data. You’ll have missing values but that should be just fine.
Once you have all your columns established and they should for some reasons have the wrong order (your wrote that this seems important), you can use the column sorter node.