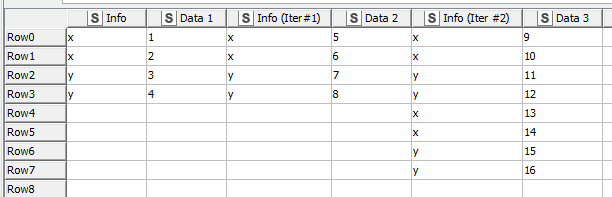
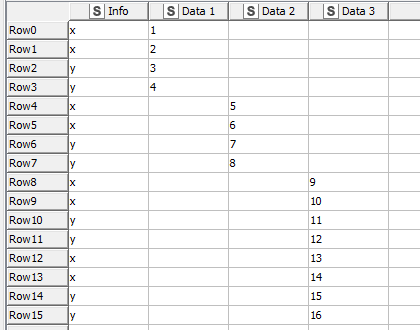
Newbie here. I’ve been building a workflow that reduces table columns from from ones containing the info and data name into a separate “Info” column(s) with columns with just the type of data.Due to my use of loops I am always left with two forms of the data. Its probably best if I illustrate my conundrum below:
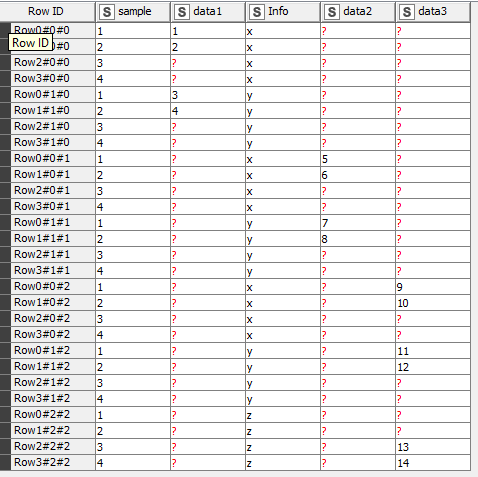
Below are two tables that contain an “Info” column with two types (“x” and “y”) and three data columns all with unique values (1-16). Two data cols have the same number of results while the third has twice as many, resulting in the following tables (you’ll recognize the two types of loop end node results).
(original columns looked like “Data1-X, Data1-Y, Data 2-X, Data 2-Y…”)
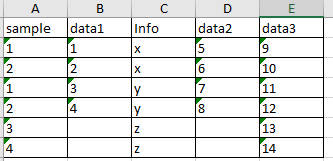
What I would like is this:
I’ve tried various grouping using temporary group columns, the unpivoting node, collection/splitting. But I can never get it right. My next attempt was going to involve splitting the columns, renaming the Info Iterations to just Info, then merging. But this would involve yet another intensive expensive loop. Most of the time I find that if I design my flow upstream to avoid confounding results to begin with things are far better. But I have yet to nail that either. So until I develop my skills better, any ideas for reducing the tables above for now?
Thank you very much in advance. This forum has been a wealth of help for me.
Hi Chumnley,
i don’t get the meaning of your expected result, i mean, you have a column info that share the same “x” and “y” across multiple “run” of data, how you navigate by them?
instead of giving us a pre-elaborate, can you show us the raw data that you are feeding inside KNIME?
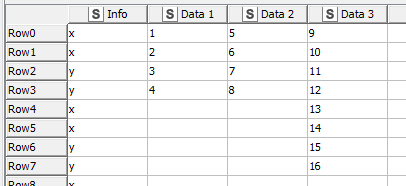
Thanks for your comments. My examples above were too simplistic, flawed. I apologize. I constructed some very simple data based on the above and put them through the actual flow.
In this case I included the unique row identifier, “sample” (essential). My issue arises when one set of data structure in the table is different for columns, e.g. samples 3 and 4 were only run in the z condition for data type 3. In my actual datasets there are scores of these types of incongruities.
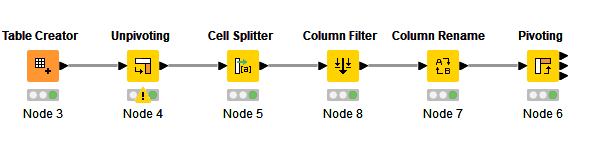
I use loops and regex extractions, etc to parse out the information, create the new columns.
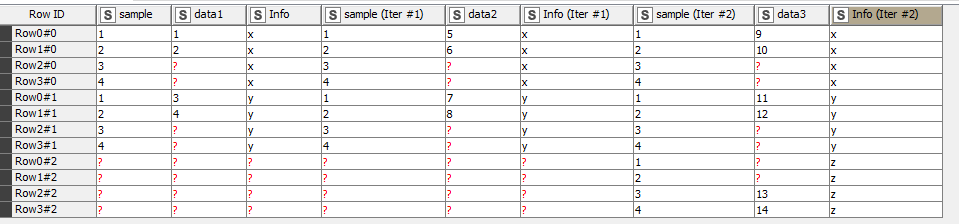
Below is the output of the flow using my loop column append:
Its impossible for me to add back the “sample” column (avoid loop iterations) as its needs to be brought along in the looping to maintain structure (to my knowledge to date). Simply filtering all iteration columns makes me lose my “z” information.
Below is the output if I instead use a loop end (concatenate):
This layout contains a lot of redundant rows which I have tried without success to group. Its closer to what I would envision. Which is this:
I’ll continue to optimize my upstream methods to avoid this conundrum entirely (9 times out of 10 I’ve found this to be the solution). If not, look into the suggestions above to further manipulate these tables. Again many thanks, apologies for my previous unclear examples. I’m learning a lot, even through this re-post.
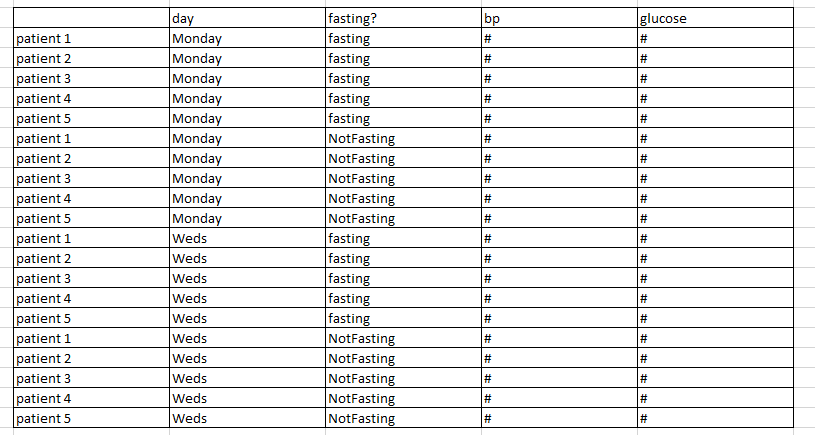
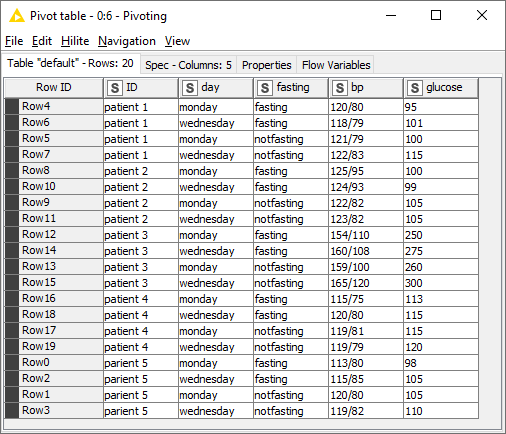
Heres a more real-world example (apologies for my poor communication above):
This is an example of the starting data. Unfortunately the method of data collection includes all the conditions like day, fasting, with the column header that includes the assay. Viewing data like this in something like Spotfire is difficult because its not simple to filter by, in this case, day or whether the patient was fasting.
Hopefully I used the term parse correctly, but a wf that performs this to the data is what I have been working on. You can see how in this example, if all 7 days were tested, and patient’s weight, height, age, were included in the headers the table column numbers blow up fast. Thats what I am dealing with. This is much better:
Based on the problems you say you’ve been having, I’m not sure how closely this latest example reflects your current situation. It’s easy to create simplistic examples that are more easily solved than the “real” situation would be.
I spent some time trying unpivoting some time back. indeed with the small sample sets its great but with my real sets it blew up on me. But this was a couple months ago and my knowledge has improved since. (I think I didnt know how to create and use array variables then, which no doubt will be key). Thank you very much for this insight. I will switch my approach.