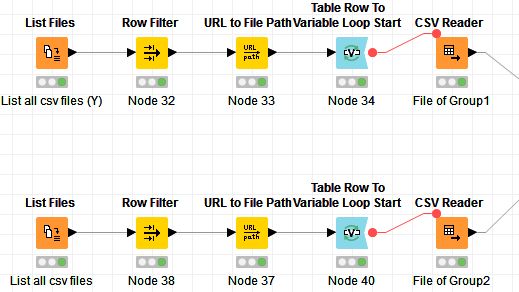
I have created a workflow to merge files from two file groups, the Group1 and Group2.
This file merge seems simple if I could concatenate all the rows to one file for each file group. But I’m worrying about memory overflow error since the files are too many and too large.
The real data of Group1 has over 10,000 files, each file 5MB.
Group2 has 700 files, each file 100MB (each file containing over 100,000 rows).
I try to test my workflow from the following image.
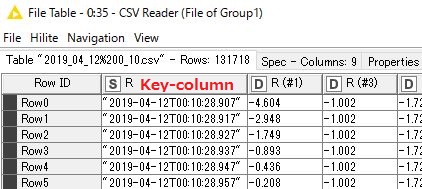
Data of Group1 CSV Reader
Data of Group2 CSV Reader
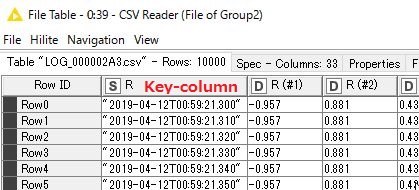
See the 1st. column of both Group, which actually is the merge key column containing a Date&time Sring.
My task is to make full data of Group1, which means need to merge Group2 to Group1.
To achieve this merge, the detail expected operation would be:
Step1. Find the 1st. row of Group1 CSV.
Step2. Seach the rows of Group2 CSV,
If the key-column matched, merge columns of Group1 CSV to Group2 CSV.
If the current CSV doesn’t have any match of key-column, then go to the next CSV of Group2, until matched or the last row of the last CSV in Group2.
Step3. Go to the next row of Group1 CSV until the last row, repeat the Operation2
Step4. Go to the next CSV of Group1, back to the Step1.
Step5. End at the last CSV of Group2.
This operation in KNIME is too complicated for me.
Or there would be a better way to do this large file merge(?).
How can I complete this large files merge operation in KNIME? Please give some adice for me.
Thanks in advance!


 .
. .
.