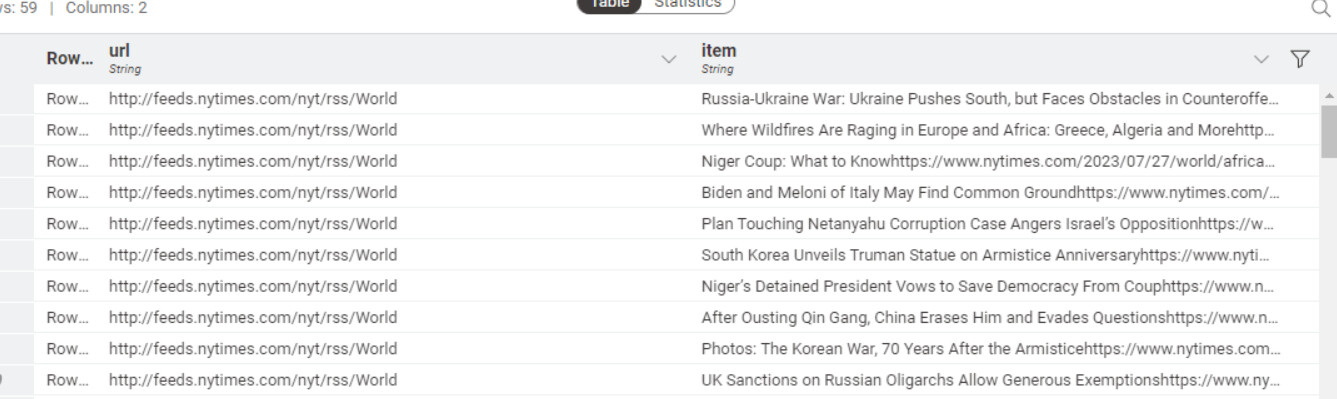
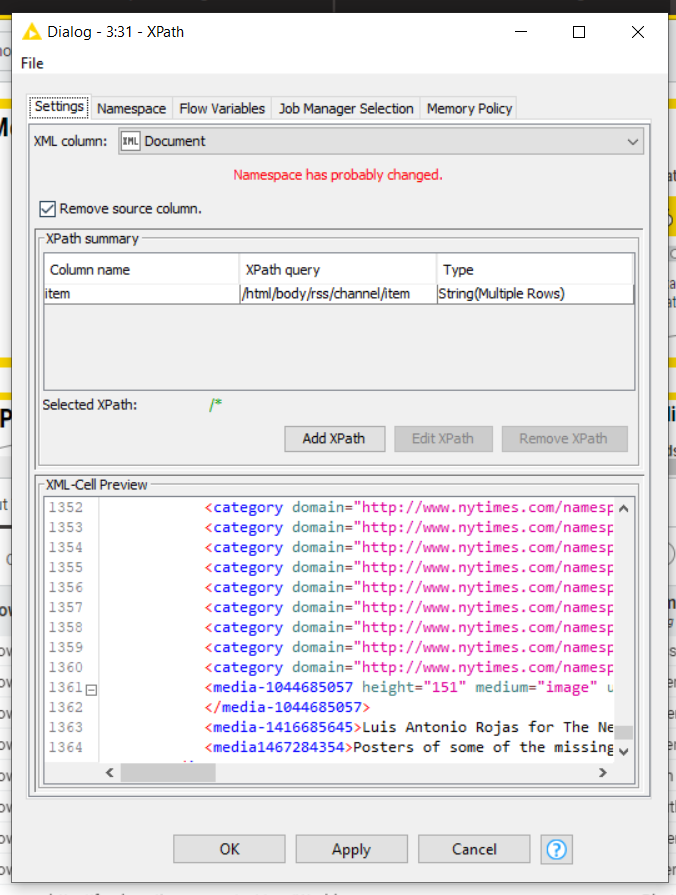
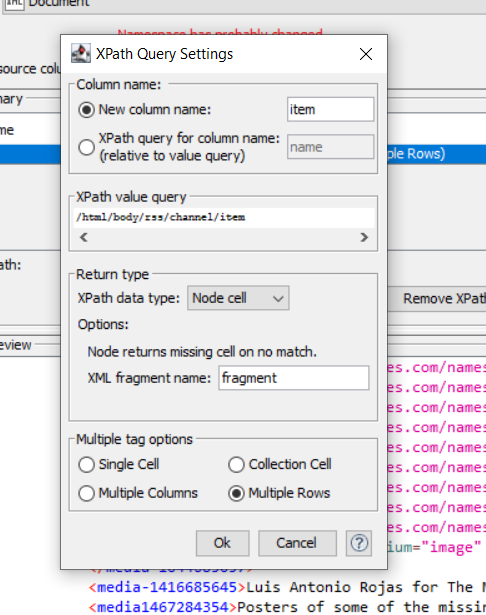
And then, I follow this step. I use Xpath Node for scrapping a websites that I take.
but the results I get are not the same as the workflow above, where the results from the Xpath node for the Item column are of type String data, not XML.
Hi, @armingrudd
I still have one question about Xpath…
I wanna fetch the topic by path : /item/description/
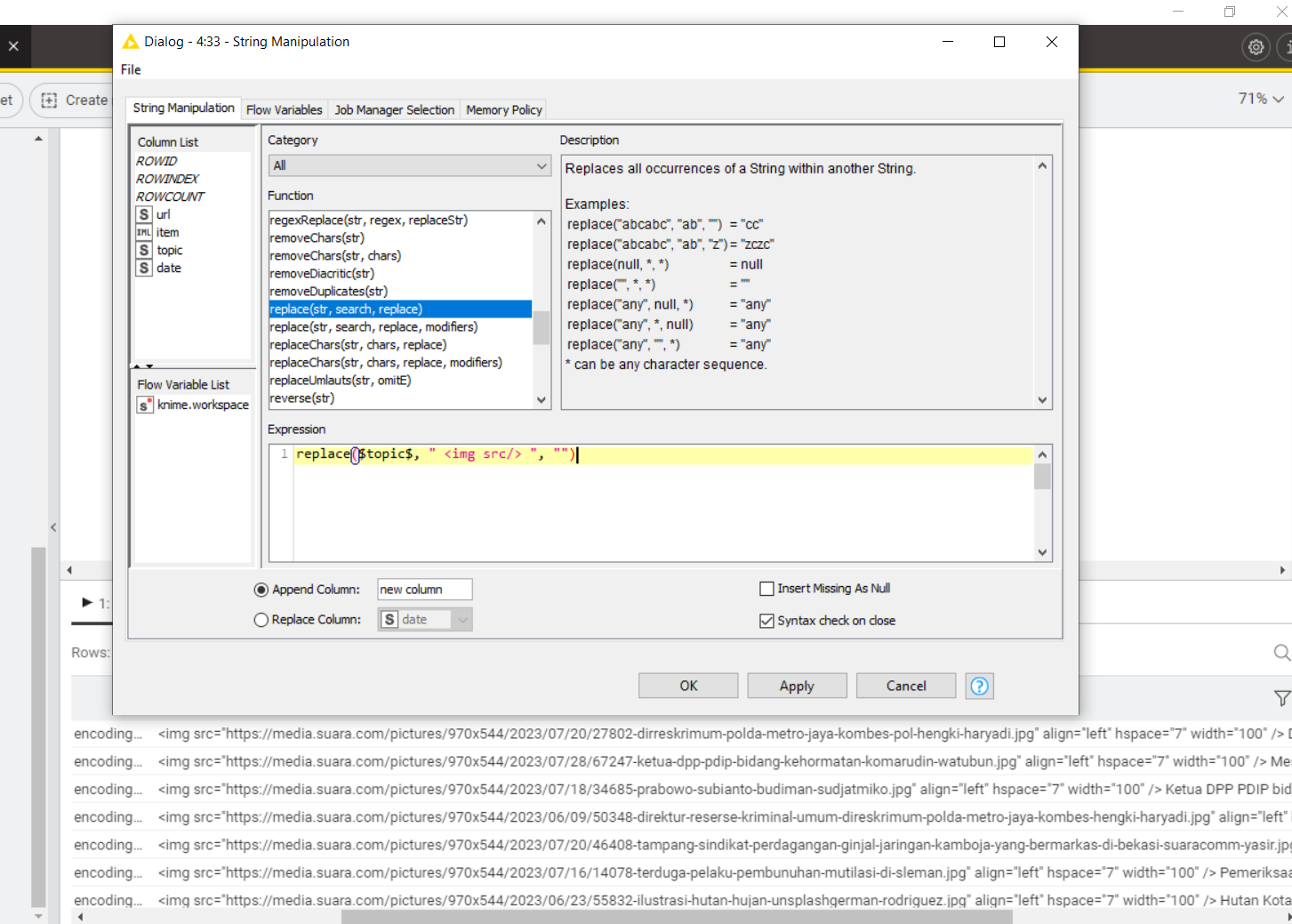
But, I want to delete a picture in the description. Do you know of a path expression to handle it?
I only want to take the part of the article that is written in the < description > tag. However, some articles in the < description > have tags to load images. While I don’t need it.
Can I remove the existing part of “img” ?
I’ve tried using the String manipulation node. By using the “replace” function. But this doesn’t work.