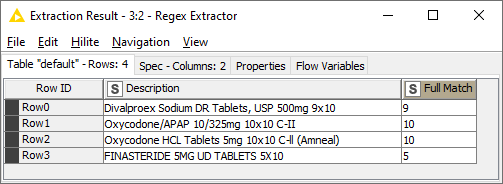
Thank you! I am just beginning to learn Regex. I’m going to try to look up some guides to learn the syntax. I’ve installed the software package you mentioned. Your expression worked great, but there are a few outliers where it was unable to find a match.
The problem here is that I assumed that the number being extracted would always be preceded by a space, but it turns out that this is not the case.
Removing that condition gives the RegEx \d{1,}(?=[X|x]) which works for all 8 strings that you’ve posted here, but I’d be worried that it’s not specific enough. Is there a chance that there’d be multiple #X# sequences in a single string?