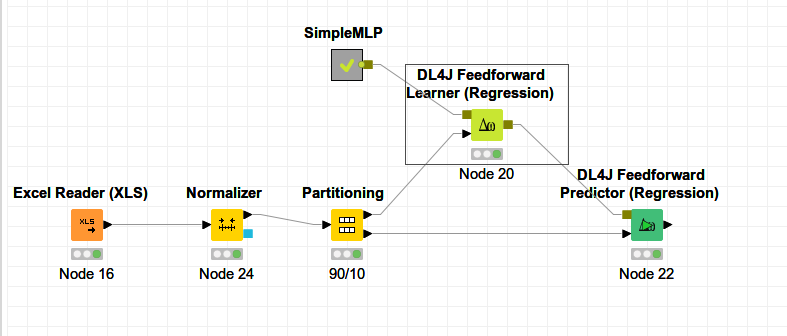
I have a small database in form of xls/csv containing “temperature” and “solubilities” of a substance. I want to make a deep learning model with dl4j that can predict “solubilities” using “temperature” as feature. I have attached the database file. I made a simple deeplearning workflow using dl4j but in the learning process is is showing all predictions as “NaN”.
Please help me to create this workflows and what all configurations parameters to be used with the nodes.
I guess you didn’t normalize your data before modelling, because when I omit this node from my workflow Dl4j.knwf (91.6 KB), the predictions are indeed “NaN”
First of all tank you HanS for replying.
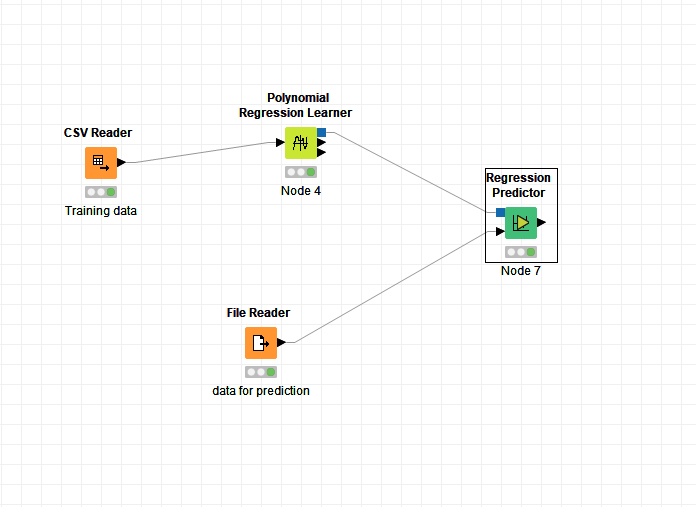
I saw your workflow, you normalized the input/training data in xls file, but the thing is don’t want to normalize the data between 0 and 1 as it is of no use to me, what i want is to make the model to predict the solubilities from Tempertature data from a file having unknown temperatures(other than training data). I am able to do this with polynomial regression but i am more interested in applying deep learning for the learning sake.
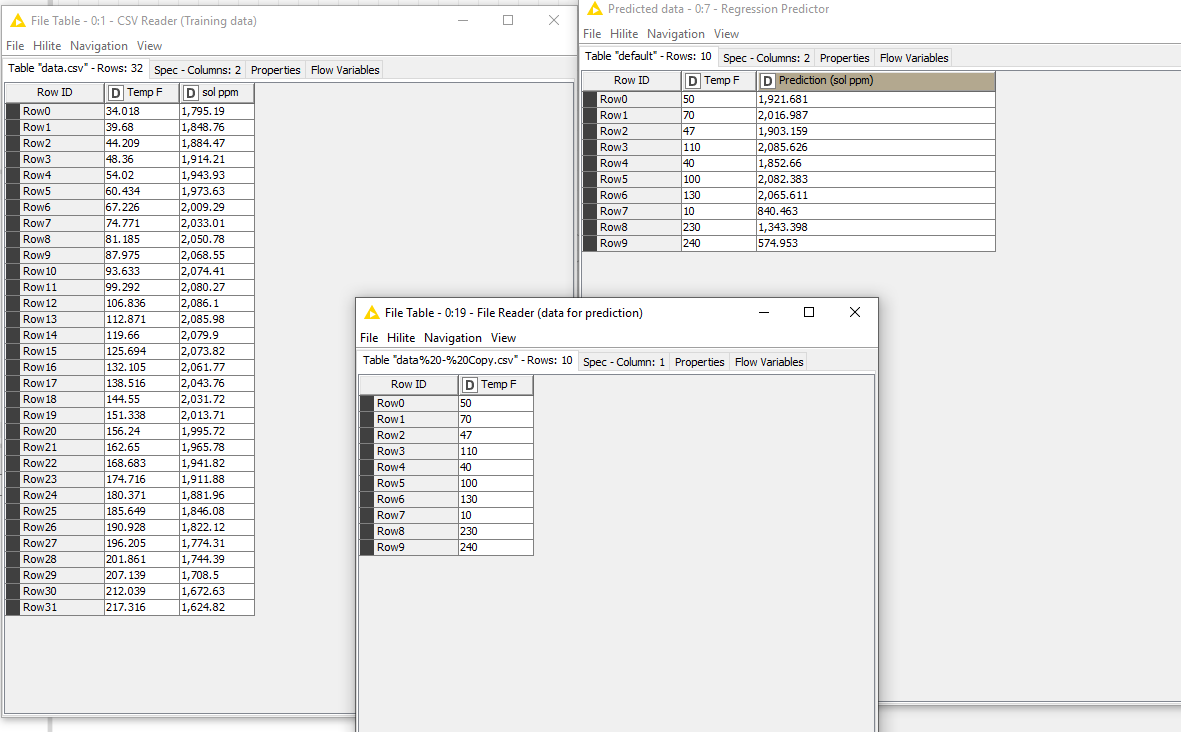
I have attached the picture of polynomial regression workflow and the predicted data by it. All i want is to do this by deep learning by dl4j.
I think when using a neural-net algorithm you beter normalize your data. From the deeplearning4j website comes the following:
Neural networks work best when the data they’re fed is normalized, constrained to a range between -1 and 1. There are several reasons for that. One is that nets are trained using gradient descent, and their activation functions usually having an active range somewhere between -1 and 1. Even when using an activation function that doesn’t saturate quickly, it is still good practice to constrain your values to this range to improve performance.
Thanks @ HansS for the quick response. Ok now I get it. But as you say that the data has to be normalized then how to get prediction(solubility in ppm) like i need (eg. 1900, 2100 etc) which cannot be between 0 and 1?