Hi,
I am the new of using spark big data extension. I have a large json file and want to transfer this knime table of json into spark data frame.

I have already created a spark job server like this:
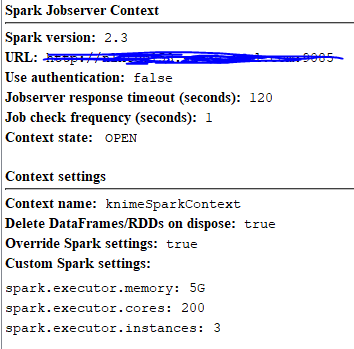
But when I input my json table to ‘table to spark’ node, I get error ‘java heap space’ since this node need to serializing json data table to tmp file.
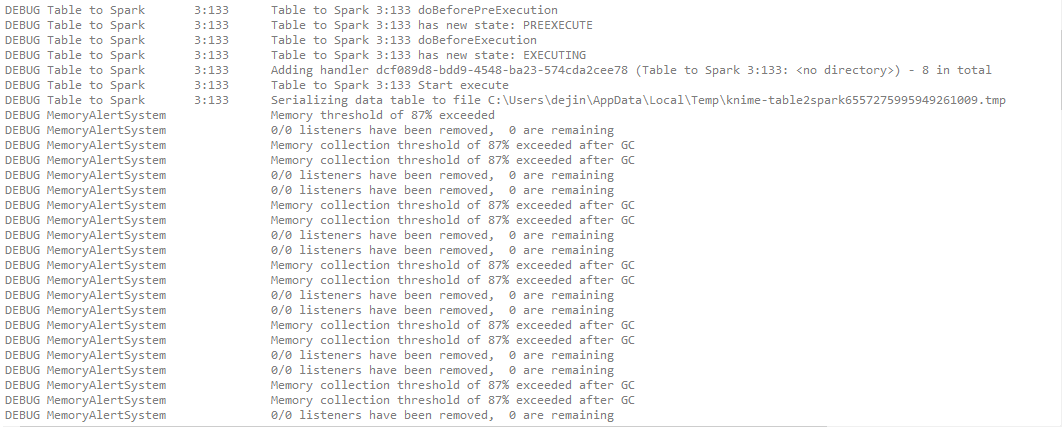
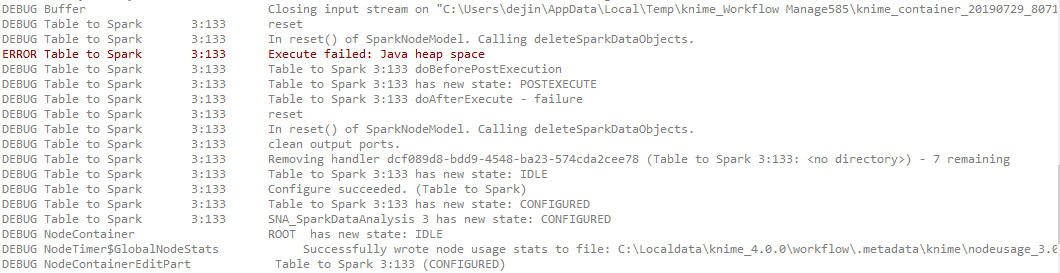
I know there is the way to change the memory cache of Knime, but it is not the solution if I have larger data need to be processed.
So I would like to ask that if there is any way in knime that allowing users to process big data into spark dataframe?