Currently, I am developing a node with the use of java and I am having some difficulties with transferring the stored or set data from the Dialog of my node. How will I put the settings or values from the DialogComponentNumber and DialogComponentColumnFilter into the output data of the node? All your comments and advices would be a great help.
There are 2 parts to this, which all rely on creating an identical SettingsModel for each DialogComponent in both the dialog and NodeModel. This is easiest done with a static factory method in the dialog:
public class MyNodeDialog extends DefaultNodeSettingsPane {
// A private constant with the displayed text which is also used as the settings key
// Not essential to do this, but it makes it easier for a user selecting in the flow variables tab
private static final String NUMBER_INPUT = "Enter a number";
public MyNodeDialog() {
// Add the dialog component, with the setting model created by the static factory method
addDialogComponent(new DialogComponentNumber(createNumberModel(),
NUMBER_INPUT, 0, 10));
}
/** Package-visible factory method for required SettingsModel */
static final SettingsModelInteger createNumberModel() {
// Use the constant for the key, with a default value
return new SettingsModelInteger(NUMBER_INPUT, 0);
}
}
Now, in the NodeModel implementation the key parts are to ensure you use the same factory method, and load / save the model:
Thank you for the sample codes Steve. However, I already did this on my codes but still not able to get the output data based on settings from the Dialog. Is there anything that I need to do with DataTableSpec, DataColumnSpec and BufferedDataTable? Also for the “.getIntValue()”, I tried to do this but I still can’t get the output.Can you give me an example on how to implemment it correctly? I apologize for my primitive questions but I your support will be very helpful to me.
Without knowing what you are trying to do, difficult to answer, but a couple of things you could try to check the settings are all transferring correctly:
Implement a trivial #configure() and #execute() method:
You should then be able to configure and run the node (the incoming tables will just be passed through unchanged), and see a couple of ‘ERROR’ messages in the console - hopefully with the corrent value from the settings model
The other common ‘gotcha’ which I think relates to an error somewhere in the documentation, is to make sure that in your NodeModel implementation your SettingsModels are not declared as static - if they are, then you will see seemingly random behaviour as all copies of your node will be sharing and updating a single instance of the SettingsModel
Ow! Sorry, I forgot to mention my purpose. On my dialog, I am filtering some columns, and then the included columns will be manipulated/processed. On the output data, all columns, including the excluded columns on the settings should still be on the table. I just used the column filtering to process or manipulate the included columns.
Ah, OK. In that case you can probably save yourself some trouble in the NodeModel by subclassing SimpleStreamableFunctionNodeModel instead (As long as your node only modifies a row at a time and doesn’t need data from multiple/other rows to compute a single output row). You still need to set up your settings models and handle their saving / loading as previously, but the configure and execute methods are handled for you. Instead, you need to implement the abstract #createColumnRearranger() method. The easiest thing for me to do is to point you to the source for some of our collection handling nodes at
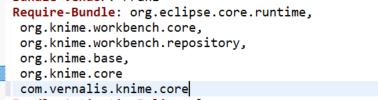
Those nodes actually subclass AbstractSimpleStreamableFunctionNodeModel which is in the Vernalis core plugin (com.vernalis.knime.core), and which also handles the settings model load / save automatically as long as you wrap each declaration with a call to #registerSettingsModel(). Otherwise, the implementation is the same as for SimpleStreamableFunctionNodeModel (If you want to use the Vernalis base NodeModel there, then you can just add com.vernalis.knime.core to your plugin dependencies in the MANIFEST.MF). Either way, parallelisation and streaming execution are all handled behind the scenes.
For example:
In the first part of the method, you initialise a ColumnRearranger with the incoming DataTableSpec, and make sure your settings are valid for your purposes (i.e. you have selected some columns etc), then you can use the various methods on ColumnRearranger to remove or replace any columns you dont want in the output table, and then append one or more columns - in this example multiple columns are added so the call is to
(If you only have a single new column, then you can use SingleCellFactory in place of AbstractCellFactory)
As a general ‘good practice’ comment, you should use a ColumnRearranger wherever possible to generate your output table, as this is very efficient - it stores a reference to the incoming table and the new data / changes, rather than a new copy of the entire table.
FInally, I think in these nodes I used DialogComponentColumnFilter2 in place of DialogComponentColumnFilter (I cant remember what the differences are between the two)
Thank you for this references.
Just to clarify, you mean I can use the SimpleStreamableFunctionNodeModel or the AbstractSimpleStreamableFunctionNodeModel(but I need to add the com.vernalis.knime.core on my MANIFEST.MF)? But is it the same? And also I tried to add the com.vernalis.knime.core on my MANIFEST.MF but I am getting some error.
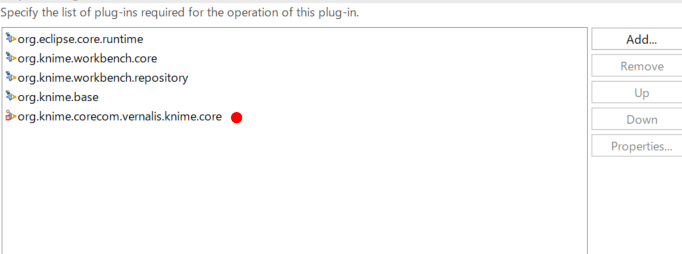
The Vernalis one adds a bit of extra stuff to handle the SettingsModels without you having to do all the load/save/validate manually yourself. To be able to use it, assuming you set up your Eclipse instance following the instructions at GitHub - knime/knime-sdk-setup: KNIME Analytics Platform - SDK Setup then you will need to modify your target platform definition to use the Vernalis version, as follows:
Open the .target file you are using and on the Definition tab, click ‘Add…’
Under the ‘Cheminformatics’ group, select the ‘Vernalis KNIME nodes’
You should then be able to save your updated .target file and click on the Reload Target Platform option at the top right of the Target Definition editor
If that seems like a lot of faff, then probably easiest to use the KNIME SimpleStreamableFunctionNodeModel
Thank you for this. I am currently studying both. With regards to the input and output port of node, it is a bit unclear with me. Because on NodeMode I can just use “super(1,1);” but on the SimpleStreamableFunctionNodeModel, it should be “super(m_inPortTypes, m_outPortTypes, 1, 1);”? Should I define first the m_inPortTypes and m_outportTypes?And I would also like to request for a link or site where I can read and study knime packages,classes, etc(with examples o how to use them). I apologize for the inconvenience but I thank you for your support!
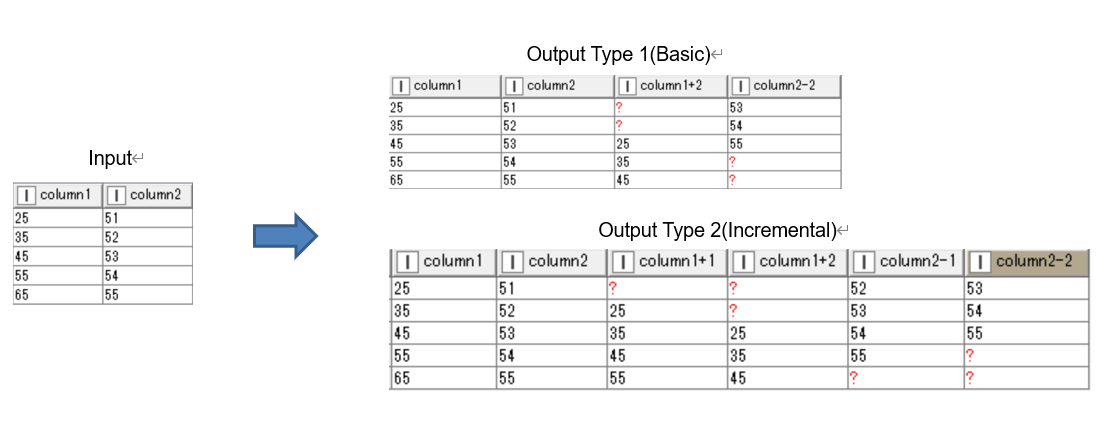
I would like to share my target output for my development. I don’t know if Columrearranger can do this or what other ways can it be done. I was trying to open to get the codes of the existing knime nodes but unfortunately I can’t find it. Please see image for your reference.
So the scenario is, I already made the user’s interface/dialog for this. I am currently doing the NodeModel.java file. On my dialog, I have two types of direction, the Upward and Downward direction like what the LagColumn Node can do. Then on my initial plan, I created one column filter for each direction so I can select the column or columns that I want to process. Next is I have the number of rows settings for each direction so the user can decide how many rows will columns move in downward or upward direction. Last is I have two types of output selection, the Basic and Incremental. On the Basic, it will directly show how many rows it moved while the incremental shows one rows at a time.
That’s it. I am having a hard time doing this on my NodeModel.java. I know this is more complicated than my questions before but I am just getting started. Any suggestions here will be a great help.
This scenario is definitely outside the scope of a ColumnRearranger implementation.
To outline what you need to do in your execute method:
Create your output table spec (DataTableSpec)
Create a container for the output table - BufferedDataContainer bdc = exec.createDataContainer(spec);
Loop over the rows of your incoming table:
BufferedDataTable inTable = inData[0];
long rowIndex = 0L;
for (DataRow inRow: inTable){
//check the user didnt cancel
exec.checkCancelled();
// Should also update progress here with exec.setProgress() methods
// Add rows to output - there are various implementations of DataRow
// This just shows a basic mechanism adding a row containing 5 missing cells
// As a (boring!) example
DataCell[] outCells = new DataCell[5];
Arrays.fill(outCells, DataType.getMissingCell());
// This just adds a simple 'Row_0', 'Row_1' etc key
// You can use 'new RowKey(String)' for more complex
RowKey key = RowKey.createRowKey(rowIndex++);
DataRow outRow = new DefaultRow(key, outCells);
bdc.addRowToTable(outRow);
}
// Finally you must close the container before getting the table
bdc.close();
BufferedDataTable outTable = bdc.getTable();
You will probably need in your case to read a few rows and store them in a Queue or similar data structure before you can start adding output rows.
Bear in mind, you can create a row in stages, e.g.:
DataRow outRow = new DefaultRow(key, cells);
// figure some more cells to add here...
outRow = new AppendedColumnRow(outRow, extraCells);
Regards being able to see the KNIME source - there is a simple fix (I think!), but I can’t remember what it is, and I always have to ask @gab1one …
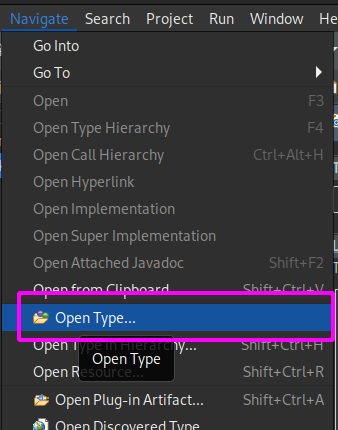
I mean the Open Type action in Eclipse, you can either use the Navigate menu:
Or the associated keyboard shortcut, which is by default Ctrl + Shift + T