Hi there,
I’m really new to this tool and the related functions.
Is it possible for Knime to run a Python script which fetch a file in my local folder?
I tried to add a CSV reader before the scipt node but it was not working.
Thank you @mlauber71 (just added your hub to my favorite !!)
It seems that the forum only accpets certain kinds of files.
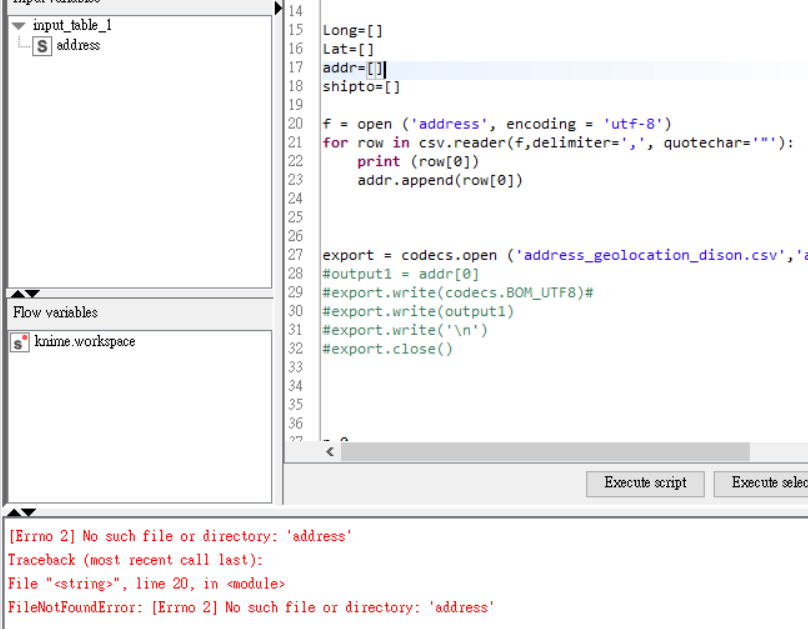
For the feed2.csv, there is only address (manually input) in the first column.
The target is to fetch latitude and longitude based on the addresses I put in “feed2.csv”.
The steps are like:
manually input address in feed.csv.
run python to fetch latitude and longitude from google.
python generate another csv file with address/latitude/longtitude.
I wouldn’t bother reading files in python unless there is some critical performance related reason to do so.
In current KNIME version you pay a pretty large penalty when moving data between KNIME and python. So if you are reading in millions of rows, then yes reading them in in python vs a file reader before will help a lot with performance. But else you are just not benefiting form the “easy of use” of knime.
If the csv reader doesn’t work in KNIME you could also try the file reader or File reader (complex format). The first is much faster but has less options to configure.
I just tried one of my use-cases and I’m actually a bit surprised as the speedup is rather much lower than expected. for to_pandas only 20% faster. to_arrow requires major code change and I’m not really familiar with pyarrow so what I did is probably not optimized but lead to a 25% speedup.
To be fair yes it does “heavy processing” so the serialization overhead becomes less important. I guess the exact use-case will have a huge impact on the speed improvement.
What would help is a guide how to work with the pyarrow table especially iterate it and generate new columns based on existing columns (eg pandas.apply)
Hi Christian, yes it’s clear only the data transfer was made faster. I was just assuming for this specific case that it was actually a larger part of the overall runtime than it really was.
Columnar backend is enabled, yes with maximize performance.