thanks,
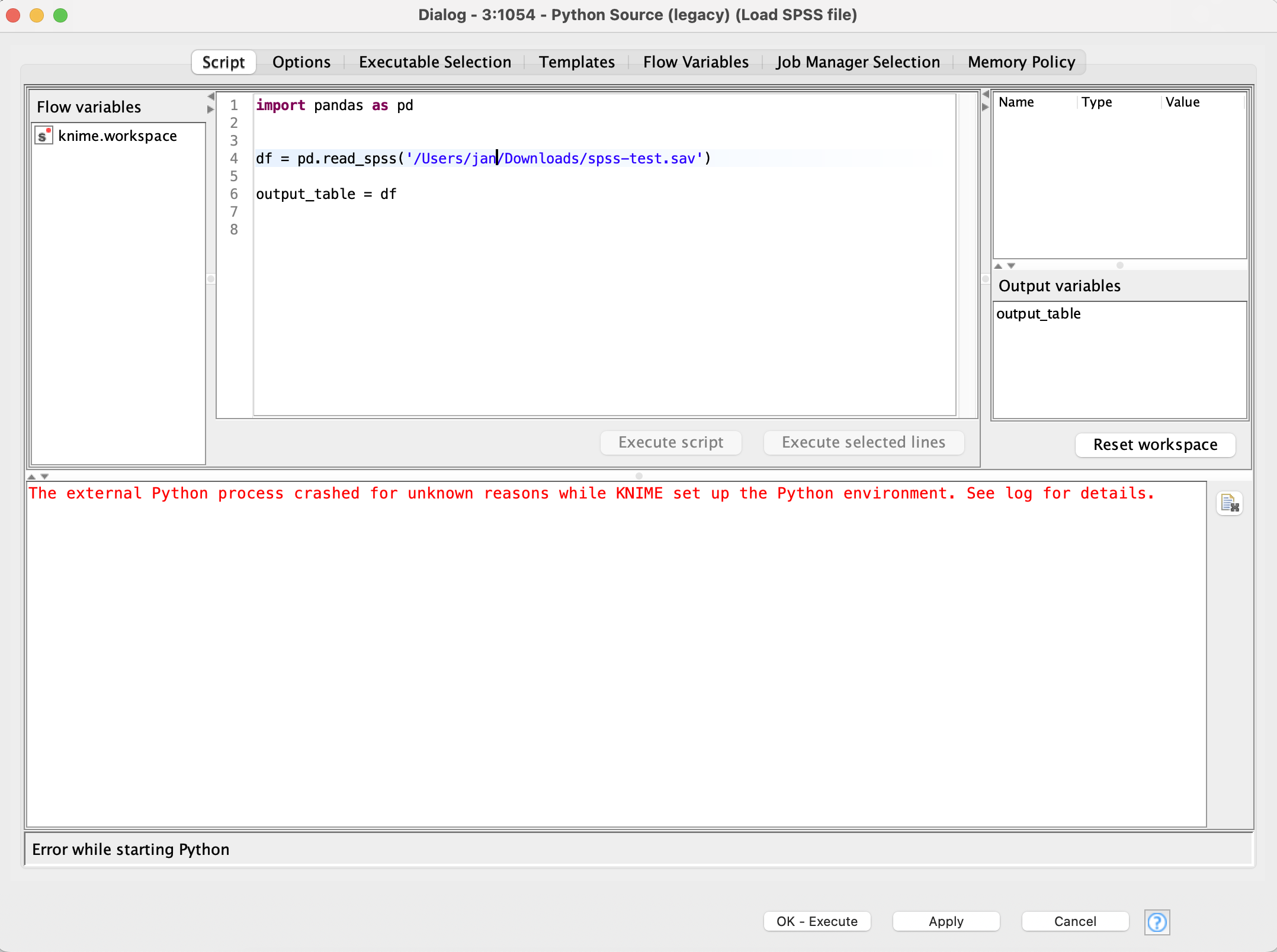
I tried the bundled python version but it fails when reading the SPSS file because pyreadstat is not found:
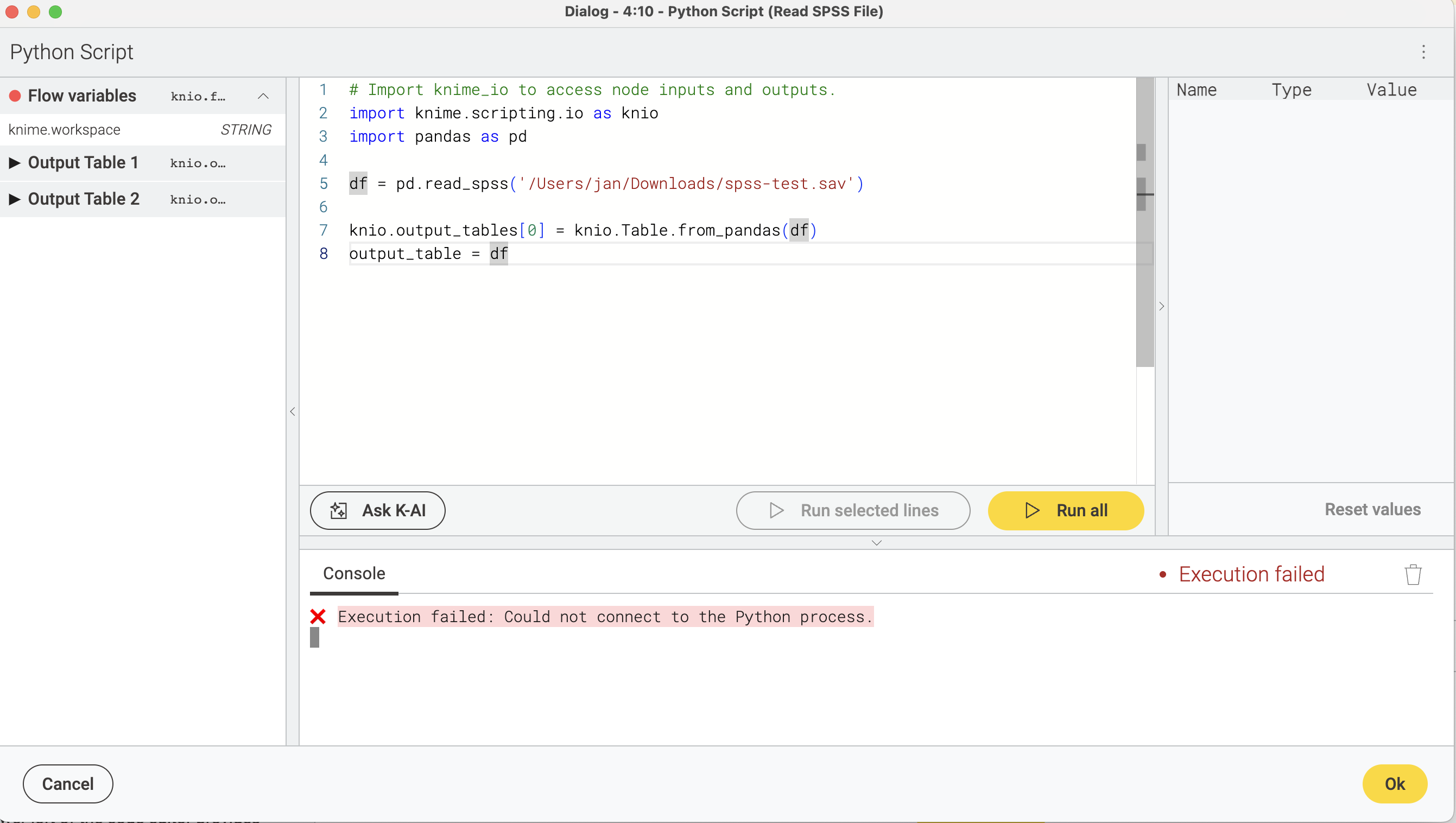
import knime.scripting.io as knio
import pandas as pd
df = pd.read_spss('/Users/jan/Downloads/spss-test.sav')
knio.output_tables[0] = knio.Table.from_pandas(df)
output_table = df
error:
File "<string>", line 5, in <module>
File "/Users/jan/Downloads/KNIME 5.4.0.app/Contents/Eclipse/bundling/envs/org_knime_pythonscripting/lib/python3.11/site-packages/pandas/io/spss.py", line 54, in read_spss
pyreadstat = import_optional_dependency("pyreadstat")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/jan/Downloads/KNIME 5.4.0.app/Contents/Eclipse/bundling/envs/org_knime_pythonscripting/lib/python3.11/site-packages/pandas/compat/_optional.py", line 145, in import_optional_dependency
raise ImportError(msg)
When I try the my own python installation (with pandas and pyreadstat), I get the error
Execution failed: Could not connect to the Python process.
I’m able to run the same script outside of Knime so my python installation is correct
python spss-test.py
Participants Location Gender ... Fate_of_IS Suggestions_solve Suggestion_prevent
0 1.0 Belay Zeleke Male ... Contitues to exist as it is Consistency application of rules/directives Leadership commitment
1 2.0 Belay Zeleke Male ... Contitues to exist as it is Regularization Leadership commitment
2 3.0 Belay Zeleke Male ... Contitues to exist as it is Compensation after subsequent demolishing sound land administration/ management
3 4.0 Belay Zeleke Male ... Disappear shortly Regularization Leadership commitment
4 5.0 Belay Zeleke Female ... Contitues to exist as it is Regularization Leadership commitment
[5 rows x 37 columns]
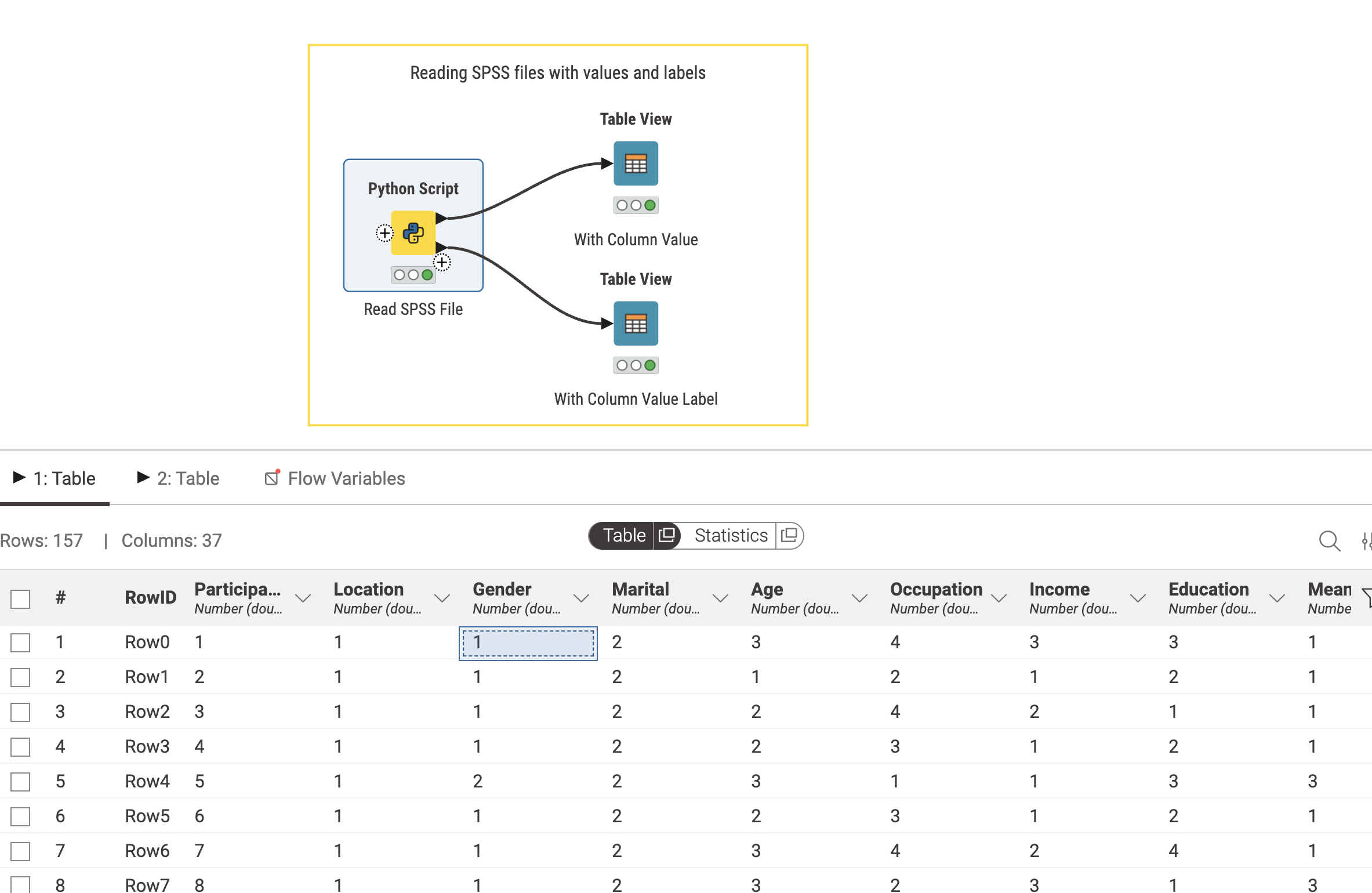
On thing that I realized is that the python node has by default an input table so it’s not suitable for reading a file using python but rather transforming existing data using python.
In order to read the data in that script, one needs to remove the input table from the node by clicking on the arrow and delete icon